
第四次软工作业:结对编程
#第四次软件工程作业:结对编程
|||
|:--:|:--|
|GIT地址|[点击查看](https://github.com/F0urty-Tw0/WordCount.git)|
|结对伙伴|[陈纪龙201831061109](https://www.cnblogs.com/FourtyTwo/)|
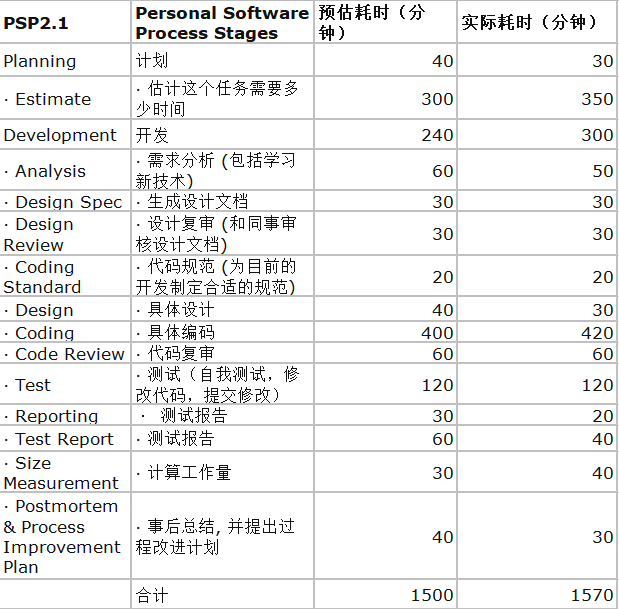
##一、PSP表格
##二、代码设计
在阅读过作业要求后,想到了python中列表和词典的功能,词典的结构正好可以来存储记录单词频率和词组频率。但涉及到命令行操作的不怎么懂。
具体代码设计及编程思想体现过程请移步结对伙伴[陈纪龙同学的博客](https://www.cnblogs.com/FourtyTwo/p/11660582.html "陈纪龙同学博客")
三、代码复审过程(问题情况)
- Python编码规范
- 在代码编写后我们进行了复审,针对函数的参数传递做了一些更改,让命令行参数与函数接口能更好的对接。同时在复审过程中发现了自己在注释以及一些代码思路上的问题,在陈纪龙同学的帮助下进行了改正。
四、单元测试及代码覆盖率
单元测试利用的是python自带的unitest部分进行测试。
过程如下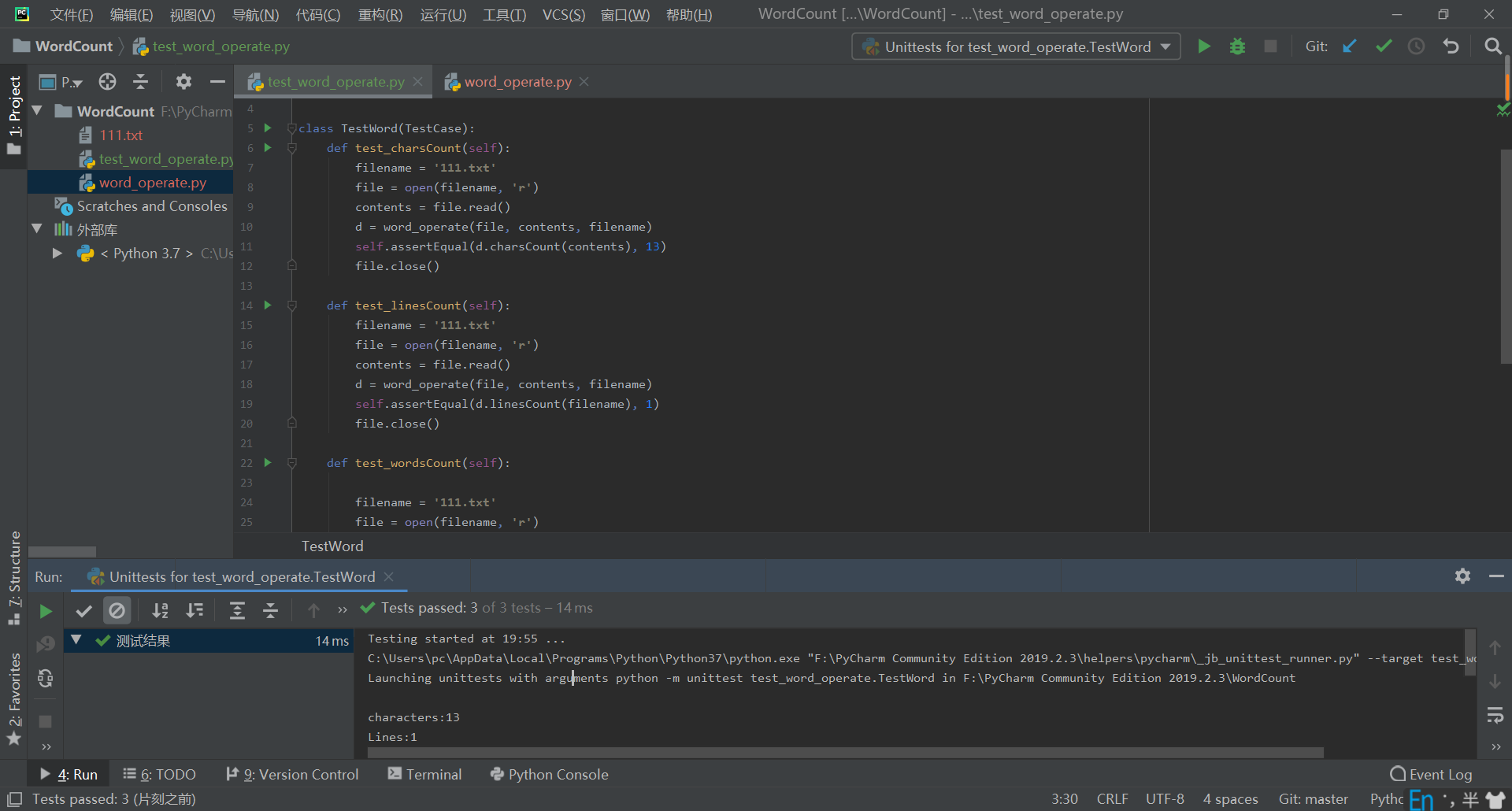
覆盖率统计自己下载coverage插件进行的代码覆盖率统计
在cmd命令行运行结果如下
这里的覆盖率结果查询资料后还是不甚明了,不知道该怎么单元测试用例才能有效提升覆盖率。
五、性能分析及改进
性能测试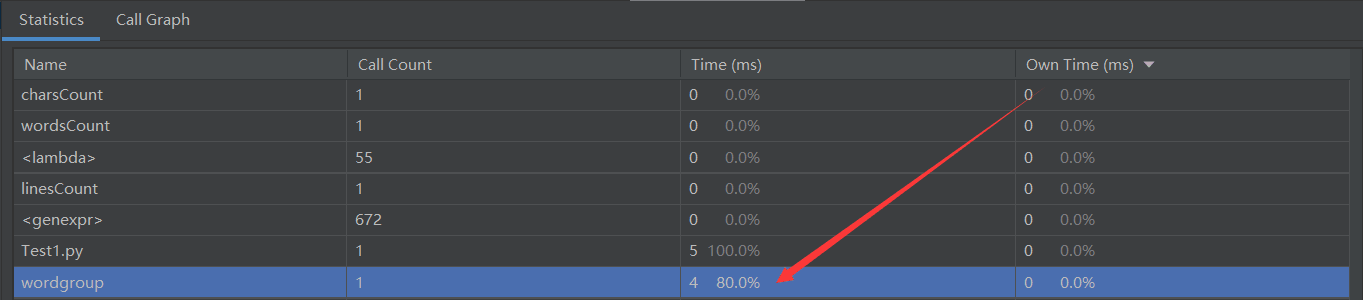
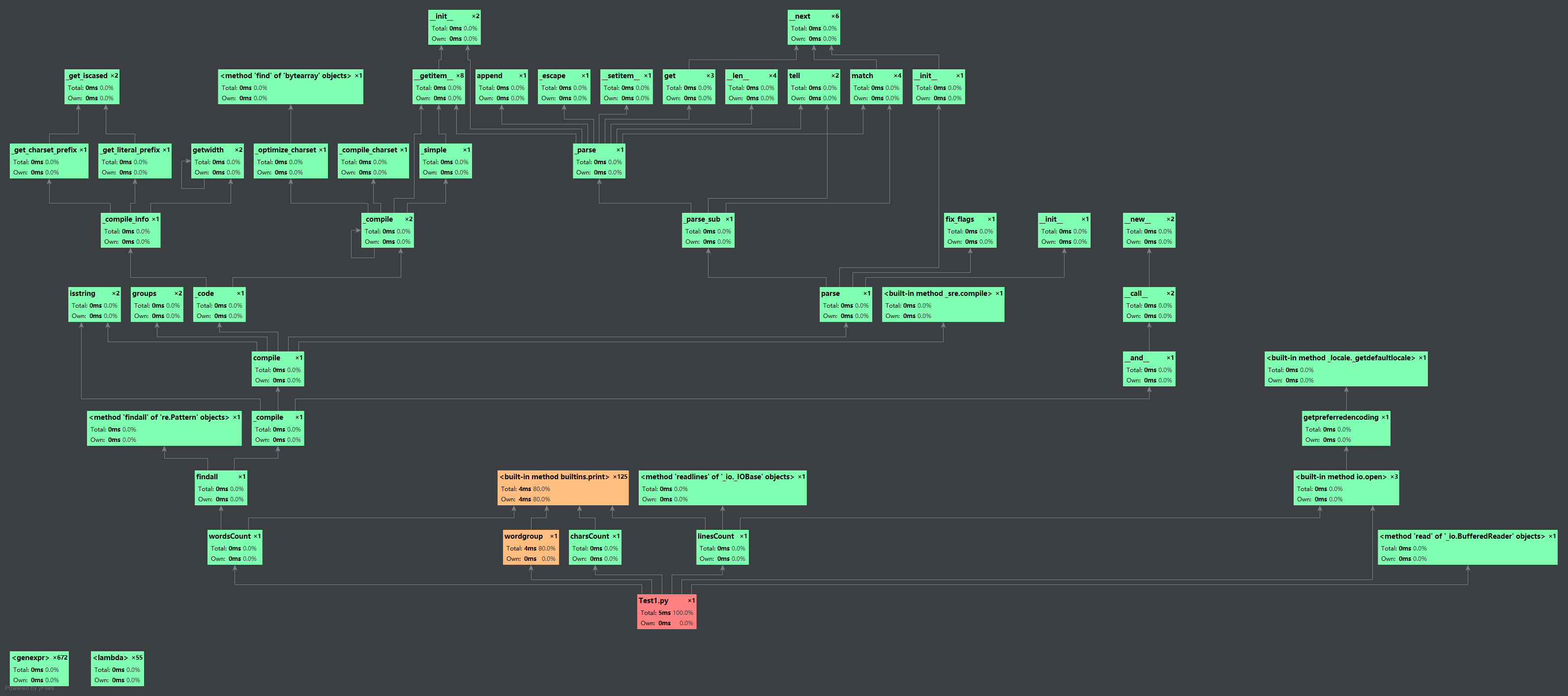
两个测试图像表明Wordgroup函数耗费最大。写这个函数的时候我想到的是利用列表可以连续读取的特性,利用循环将每次读取的区间进行更新,从而获得指定长度词组,。在利用join函数将列表读取出来的词组转化为字符串做为关键字。再利用词组的get方法获取词组出现的频率。
造成耗费大的原因应该是循环中嵌套了对列表转字符串的操作以及对词组频率的统计
希望能有更好的方法
运行结果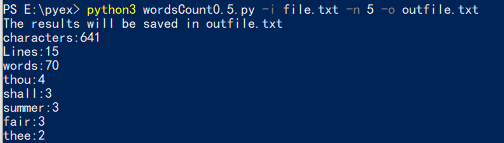
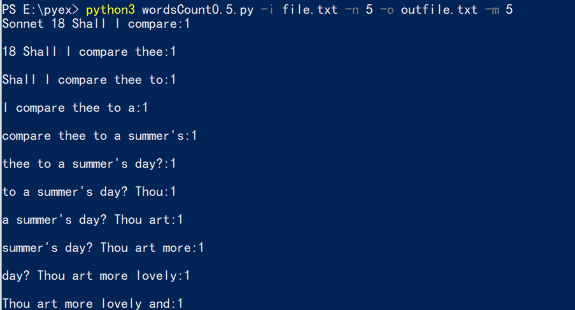
六、异常处理
参考陈纪龙的博客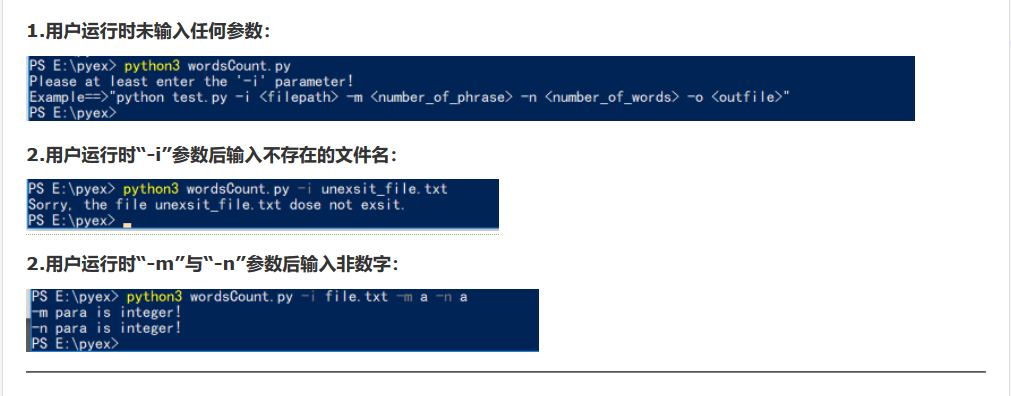
七、结对过程
在此次结对编程作业中,陈纪龙同学出了很多力,我们两个都有python基础,但是在结对过程可以明显感觉到伙伴的效率逼我高很多,我想是因为我的代码量较少,很多都没进行实际操作,看来实践是检验技术的唯一标准。在纪龙同学的帮助下我收获了很多,包括学会了一些没学过的技术,以及面向对象的基础思想,最终顺利完成了此次编写作业,由衷地体会到了结对编程地“1+1>2”。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号