
Ceph源码解析:CRUSH算法
1、简介
随着大规模分布式存储系统(PB级的数据和成百上千台存储设备)的出现。这些系统必须平衡的分布数据和负载(提高资源利用率),最大化系统的性能,并要处理系统的扩展和硬件失效。ceph设计了CRUSH(一个可扩展的伪随机数据分布算法),用在分布式对象存储系统上,可以有效映射数据对象到存储设备上(不需要中心设备)。因为大型系统的结构式动态变化的,CRUSH能够处理存储设备的添加和移除,并最小化由于存储设备的的添加和移动而导致的数据迁移。
为了保证负载均衡,保证新旧数据混合在一起。但是简单HASH分布不能有效处理设备数量的变化,导致大量数据迁移。ceph开发了CRUSH(Controoled Replication Under Scalable Hashing),一种伪随机数据分布算法,它能够在层级结构的存储集群中有效的分布对象的副本。CRUSH实现了一种伪随机(确定性)的函数,它的参数是object id或object group id,并返回一组存储设备(用于保存object副本OSD)。CRUSH需要cluster map(描述存储集群的层级结构)、和副本分布策略(rule)。
CRUSH有两个关键优点:
- 任何组件都可以独立计算出每个object所在的位置(去中心化)。
- 只需要很少的元数据(cluster map),只要当删除添加设备时,这些元数据才需要改变。
CRUSH的目的是利用可用资源优化分配数据,当存储设备添加或删除时高效地重组数据,以及灵活地约束对象副本放置,当数据同步或者相关硬件故障的时候最大化保证数据安全。支持各种各样的数据安全机制,包括多方复制(镜像),RAID奇偶校验方案或者其他形式的校验码,以及混合方法(比如RAID-10)。这些特性使得CRUSH适合管理对象分布非常大的(PB级别)、要求可伸缩性,性能和可靠性非常高的存储系统。简而言之就是PG到OSD的映射过程。
2.映射过程
2.1 概念
ceph中Pool的属性有:1.object的副本数 2.Placement Groups的数量 3.所使用的CRUSH Ruleset
数据映射(Data Placement)的方式决定了存储系统的性能和扩展性。(Pool,PG)→ OSD set的映射由四个因素决定:
(1)CRUSH算法
(2)OSD MAP:包含当前所有pool的状态和OSD的状态。OSDMap管理当前ceph中所有的OSD,OSDMap规定了crush算法的一个范围,在这个范围中选择OSD结合。OSDMap其实就是一个树形的结构,叶子节点是device(也就是osd),其他的节点称为bucket节点,这些bucket都是虚构的节点,可以根据物理结构进行抽象,当然树形结构只有一个最终的根节点称之为root节点,中间虚拟的bucket节点可以是数据中心抽象、机房抽象、机架抽象、主机抽象等如下图。

osd组成的逻辑树形结构
struct crush_bucket
{
__s32 id; /* this'll be negative */
__u16 type; /* non-zero; type=0 is reserved for devices */
__u8 alg; /* one of CRUSH_BUCKET_* */
__u8 hash; /* which hash function to use, CRUSH_HASH_* */
__u32 weight; /* 16-bit fixed point *///权重一般有两种设法。一种按容量,一般是1T为1,500G就是0.5。另外一种按性能。具体按实际设置。
__u32 size; /* num items */
__s32 *items;/*
* cached random permutation: used for uniform bucket and for
* the linear search fallback for the other bucket types.
*/
__u32 perm_x; /* @x for which *perm is defined */
__u32 perm_n; /* num elements of *perm that are permuted/defined */
__u32 *perm;
};
(3)CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
(4)CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objects放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服器上,第3个副本分布在机架4的服务器上。
2.2 流程
Ceph 架构中,Ceph 客户端是直接读或者写存放在 OSD上的 RADOS 对象存储中的对象(data object)的,因此,Ceph 需要走完 (Pool, Object) → (Pool, PG) → OSD set → OSD/Disk 完整的链路,才能让 ceph client 知道目标数据 object的具体位置在哪里。
数据写入时,文件被切分成object,object先映射到PG,再由PG映射到OSD set。每个pool有多个PG,每个object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD个数由pool的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
Ceph分布数据的过程:首先计算数据x的Hash值并将结果和PG数目取余,以得到数据x对应的PG编号。然后,通过CRUSH算法将PG映射到一组OSD中。最后把数据x存放到PG对应的OSD中。这个过程中包含了两次映射,第一次是数据x到PG的映射。PG是抽象的存储节点,它不会随着物理节点的加入或则离开而增加或减少,因此数据到PG的映射是稳定的。
(1)创建 Pool 和它的 PG。根据上述的计算过程,PG 在 Pool 被创建后就会被 MON 在根据 CRUSH 算法计算出来的 PG 应该所在若干的 OSD 上被创建出来了。也就是说,在客户端写入对象的时候,PG 已经被创建好了,PG 和 OSD 的映射关系已经是确定了的。
(2)Ceph 客户端通过哈希算法计算出存放 object 的 PG 的 ID:
- 客户端输入 pool ID 和 object ID (比如 pool = “liverpool” and object-id = “john”)
- ceph 对 object ID 做哈希
- ceph 对该 hash 值取 PG 总数的模,得到 PG 编号 (比如 58)(第2和第3步基本保证了一个 pool 的所有 PG 将会被均匀地使用)
- ceph 对 pool ID 取 hash (比如 “liverpool” = 4)
- ceph 将 pool ID 和 PG ID 组合在一起(比如 4.58)得到 PG 的完整ID。
也就是:PG-id = hash(pool-id). hash(objet-id) % PG-number
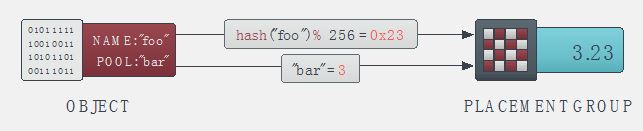
(3)客户端通过 CRUSH 算法计算出(或者说查找出) object 应该会被保存到 PG 中哪个 OSD 上。(注意:这里是说”应该“,而不是”将会“,这是因为 PG 和 OSD 之间的关系是已经确定了的,那客户端需要做的就是需要知道它所选中的这个 PG 到底将会在哪些 OSD 上创建对象。)。这步骤也叫做 CRUSH 查找。
对 Ceph 客户端来说,只要它获得了 Cluster map,就可以使用 CRUSH 算法计算出某个 object 将要所在的 OSD 的 ID,然后直接与它通信。
- Ceph client 从 MON 获取最新的 cluster map。
- Ceph client 根据上面的第(2)步计算出该 object 将要在的 PG 的 ID。
- Ceph client 再根据 CRUSH 算法计算出 PG 中目标主和次 OSD 的 ID。
也就是:OSD-ids = CURSH(PG-id, cluster-map, cursh-rules)。

具体数据读写流程下次整理分析。
3 CRUSH 算法
CRUSH算法根据种每个设备的权重尽可能概率平均地分配数据。分布算法是由集群可用存储资源以及其逻辑单元的map控制的。这个map的描述类似于一个大型服务器的描述:服务器由一系列的机柜组成,机柜装满服务器,服务器装满磁盘。数据分配的策略是由定位规则来定义的,定位规则指定了集群中将保存多少个副本,以及数据副本的放置有什么限制。例如,可以指定数据有三个副本,这三个副本必须放置在不同的机柜中,使得三个数据副本不公用一个物理电路。
给定一个输入x,CRUSH 算法将输出一个确定的有序的储存目标向量 ⃗R 。当输入x,CRUSH利用强大的多重整数hash函数根据集群map、定位规则、以及x计算出独立的完全确定可靠的映射关系。CRUSH分配算法是伪随机算法,并且输入的内容和输出的储存位置之间是没有显式相关的。我们可以说CRUSH 算法在集群设备中生成了“伪集群”的数据副本。集群的设备对一个数据项目共享数据副本,对其他数据项目又是独立的。
CRUSH算法通过每个设备的权重来计算数据对象的分布。对象分布是由cluster map和data distribution policy决定的。cluster map描述了可用存储资源和层级结构(比如有多少个机架,每个机架上有多少个服务器,每个服务器上有多少个磁盘)。data distribution policy由 placement rules组成。rule决定了每个数据对象有多少个副本,这些副本存储的限制条件(比如3个副本放在不同的机架中)。
CRUSH算出x到一组OSD集合(OSD是对象存储设备):
(osd0, osd1, osd2 … osdn) = CRUSH(x)
CRUSH利用多参数HASH函数,HASH函数中的参数包括x,使得从x到OSD集合是确定性的和独立的。CRUSH只使用了cluster map、placement rules、x。CRUSH是伪随机算法,相似输入的结果之间没有相关性。
Cluster map由device和bucket组成,它们都有id和权重值。Bucket可以包含任意数量item。item可以都是的devices或者都是buckets。管理员控制存储设备的权重。权重和存储设备的容量有关。Bucket的权重被定义为它所包含所有item的权重之和。CRUSH基于4种不同的bucket type,每种有不同的选择算法。
3.1 分层集群映射(cluster map)
集群映射由设备和桶(buckets)组成,设备和桶都有数值的描述和权重值。桶可以包含任意多的设备或者其他的桶,使他们形成内部节点的存储层次结构,设备总是在叶节点。存储设备的权重由管理员设置以控制相设备负责存储的相对数据量。尽管大型系统的设备含不同的容量大小和性能特点,随机数据分布算法可以根据设备的利用率和负载来分布数据。
这样设备的平均负载与存储的数据量成正比。这导致一维位置指标、权重、应来源于设备的能力。桶的权重是它所包含的元素的权重的总和。
桶可由任意可用存储的层次结构组成。例如,可以创建这样一个集群映射,用名为“shelf”的桶代表最低层的一个主机来包含主机上的磁盘设备,然后用名为“cabinet”的桶来包含安装在同一个机架上的主机。在一个大的系统中,代表机架的“cabinet”桶可能还会包含在“row”桶或者“room”桶里。数据被通过一个伪随机类hash函数递归地分配到层级分明的桶元素中。传统的散列分布技术,一旦存储目标数量有变,就会导致大量的数据迁移;而CRUSH算法是基于桶四个不同的类型,每一个都有不同的选择算法,以解决添加或删除设备造成的数据移动和整体的计算复杂度。
3.2 副本放置(Replica Placement)
CRUSH 算法的设置目的是使数据能够根据设备的存储能力和宽带资源加权平均地分布,并保持一个相对的概率平衡。副本放置在具有层次结构的存储设备中,这对数据安全也有重要影响。通过反射系统的物理安装组织,CRUSH算法可以将系统模块化,从而定位潜在的设备故障。这些潜在故障的资源包括物理的,比如共用电源,共用的网络。通过向集群映射编码信息,CRUSH副本放置策略可以将数据对象独立在不同故障域,同时仍然保持所需的分布。例如,为了定位可能存在的并发故障,应该确保设备上的数据副本放置在不同的机架、主机、电源、控制器、或其他的物理位置。
CRUSH算法为了适应千篇一律的脚本,像数据复制策略和底层的硬件配置,CRUSH对于每份数据的复制策略或者分布式策略的部署方式,它允许存储系统或 者管理员精确地指定对象副本如何放置。例如,有的会选择两个镜像来存储一对数据对象,有的会选择3个镜像来存储2个不同的数据对象,还有的会选择6个甚至更多的便宜廉价RAID-4硬盘设备来存储等等。

函数入口:
/**
* crush_do_rule - calculate a mapping with the given input and rule
* @map: the crush_map
* @ruleno: the rule id
* @x: hash input
* @result: pointer to result vector
* @result_max: maximum result size
* @weight: weight vector (for map leaves)
* @weight_max: size of weight vector
* @scratch: scratch vector for private use; must be >= 3 * result_max
*/
int crush_do_rule(const struct crush_map *map,
int ruleno, int x, int *result, int result_max,
const __u32 *weight, int weight_max,
int *scratch) //对照此函数与算法伪代码基本可以看出crush在做什么事情。部分数值计算我也看不懂为什么他这么做,水平有限。
CRUSH_RULE_TAKE /* arg1 = value to start with */
CRUSH_RULE_CHOOSE_FIRSTN = 2, /* arg1 = num items to pick */ crush_choose_firstn()
/* arg2 = type */
CRUSH_RULE_CHOOSE_INDEP = 3, /* same */ crush_choose_indep()CRUSH_RULE_EMIT = 4, /* no args */ return results
在算法1的伪代码中,每个规则都包含了一系列应用在一个简单运行环境的操作。CRUSH函数的整型输入参数就是一个典型的对象名或者标示符,这个参数就像一堆可以被复制在相同机器上的对象复制品。操作take(a)选择了一个在存储层次的bucket并把这个bucket分配给向量i,这是为后面的操作做准备。操作select(n,t)迭代每个元素i,并且在这个点中的子树中选择了n个t类型的项。存储设备有一个绑定类型,并且每个bucket在系统中拥有一个用于分辨buckets中classes的类型区域(例如哪些代表rows,哪些代表cabinets等)。对于每个i,select(n,t)都会从1到n迭代调用,同时通过任何中间buckets降序递归,它伪随机地选择一个通过函数c(r,x)嵌套的项,直到它找到请求t中的一个项。去重后的结果项n|i|会返回给输入变量i,同时也会作为随后被调用的select(n,t)操作的输入参数,或者被移动到用于触发操作的结果向量中。
- tack(a) :选择一个item,一般是bucket,并返回bucket所包含的所有item。这些item是后续操作的参数,这些item组成向量i。
- select(n, t):迭代操作每个item(向量i中的item),对于每个item(向量i中的item)向下遍历(遍历这个item所包含的item),都返回n个不同的item(type为t的item),并把这些item都放到向量i中。select函数会调用c(r, x)函数,这个函数会在每个bucket中伪随机选择一个item。
- emit:把向量i放到result中
存储设备有一个确定的类型。每个bucket都有type属性值,用于区分不同的bucket类型(比如”row”、”rack”、”host”等,type可以自定义)。rules可以包含多个take和emit语句块,这样就允许从不同的存储池中选择副本的storage target。

如表1中示例所示,该法则是从图1架构中的root节点开始,第一个select(1.row)操作选择了一个row类型的单例bucket。随后的select(3,cabinet)操作选择了3个嵌套在下面row2(cab21, cab23, cab24)行中不重复的值,同时,最后的select(1,disk)操作迭代了输入向量中的三个buckets,也选择了嵌套在它们其中的人一个单例磁盘。最后的结果集是三个磁盘空间分配给了三个块,但是所有的结果集都在同一行中。因此,这种方法允许复制品在容器中被同时分割和合并,这些容器包括rows、cabinets、shelves。这种方法对于可靠性和优异的性能要求是非常有利的。这些法则包含了多次take和emit模块,它们允许从不同的存储池中获取不同的存储对象,正如在远程复制脚本或者层叠式设备那样。
3.2.1 冲突,失败和过载
select(n,t) 操作可能会在多种层次的存储体系中查找以定位位于其起始点下的n个不同的t类型项,这是一个由选择的复制数 r =1,..., n部分决定的迭代过程。在此过程中,CRUSH可能会由于以下三个不同原因而丢弃(定位)项并使用修改后的输入参数 r′来重新选择(定位)项:如果某一项已经位于当前集合中(冲突——select(n,t) 的结果必须互不相同),如果设备出现故障,或者过载。虽然故障或过载设备在集群map中尽可能地被标记出来,但他们还是被保留在体系中以避免不必要的数据迁移。CRUSH利用集群map中的可能性,特别是与过度利用相关的可能性,通过伪随机拒绝有选择的转移过载设备中的一小部分数据。对于故障或过载设备,CRUSH通过在select(n,t) 开始时重启递归来达到项在存储集群中的均匀分布(见算法1第11行)。对于冲突情况,替代参数r′首先在迭代的内部级别使用以进行本地查找(见算法1的第14行),这样可以远离比较容易出现冲突的子树以避免全部数据的分布不均(比如桶(数量)比n小的时候)。
- 冲突:这个item已经在向量i中,已被选择。
- 故障:设备发生故障,不能被选择。
- 超载:设备使用容量超过警戒线,没有剩余空间保存数据对象。
3.2.2 复制排名
奇偶检验和纠删码方案相比复制在配置要求上都有些许不同。在原本复制方案中,出现故障后,原先副本(已经拥有该数据的副本)成为新的原本常常是需要的。在这种情况下,CRUSH可以使用r′ = r + f 重新进行选择并使用前n个合适项,其中 f表示执行当前操作select(n,t)过程中定位失败的次数(见算法1第16行)。然而,在奇偶检验和纠删码方案中,CRUSH输出中的存储设备排名或位置是特定的,因为每个目标保存了数据对象中的不同数据。特别是,如果存储设备出现故障,它应在CRUSH输出列表⃗R 的特定位置被替换掉,以保证列表中的其他设备排名保持不变(即查看图2中 ⃗R的位置)。在这种情况下,CRUSH使用r′=r+frn进行重新选择,其中fr是r中的失败尝试次数,这样就可以为每一个复制排名确定一系列在统计上与其他故障独立的候选项。相反的是,RUSH同其他存在的哈希分布函数一样,对于故障设备没有特殊的处理机制,它想当然地假设在使用前n个选项时已经跳过了故障设备,这使得它对于奇偶检验方案很难处理。

3.3 Map的变化和数据移动
在大型文件系统中一个比较典型的部分就是数据在存储资源中的增加和移动。为了避免非对称造成的系统压力和资源的不充分利用,CRUSH主张均衡的数据分布和系统负载。当存储系统中个别设备宕机后,CRUSH会对这些宕机设备做相应标记,并且会将其从存储架构中移除,这样这些设备就不会参与后面的存储,同时也会将其上面的数据复制一份到其它机器进程存储。

当集群架构发生变化后情况就比较复杂了,例如在集群中添加节点或者删除节点。在添加的数据进行移动时,CRUSH的mapping过程所使用的按决策树中层次权重算法比理论上的优化算法∆w /w更有效。在每个层次中,当一个香港子树的权重改变分布后,一些数据对象也必须跟着从下降的权重移动到上升的权重。由于集群架构中每个节点上伪随机位置决策是相互独立的,所以数据会统一重新分布在该点下面,并且无须获取重新map后的叶子节点在权重上的改变。仅仅更高层次的位置发送变化时,相关数据才会重新分布。这样的影响在图3的二进制层次结构中展示了出来。

架构中数据移动的总量有一个最低限度∆w/w,这部分数据将会根据∆w权重重新分布在新的存储节点上。移动数据的增量会根据权重h以及平滑上升的界限h ∆w决定。当∆w非常小以至于几乎接近W时移动数据的总量会通过这个上升界限进行变化,因为在每个递归过程中数据对象移动到一个子树上会有一个最低值和最小相关权重。
代码流程图:

bucket: take操作指定的bucket;
type: select操作指定的Bucket的类型;
repnum: select操作指定的副本数目;
rep:当前选择的副本编号;
x: 当前选择的PG编号;
item: 代表当前被选中的Bucket;
c(r, x, in): 代表从Bucket in中为PG x选取第r个副本;
collide: 代表当前选中的副本位置item已经被选中,即出现了冲突;
reject: 代表当前选中的副本位置item被拒绝,例如,在item已经处于out状态的情况下;
ftotal: 在Descent域中选择的失败次数,即选择一个副本位置的总共的失败次数;
flocal: 在Local域中选择的失败次数;
local_retries: 在Local域选择冲突时的尝试次数;
local_fallback_retries: 允许在Local域的总共尝试次数为bucket.size + local_fallback_retires次,以保证遍历完Buckt的所有子节点;
tries: 在Descent的最大尝试次数,超过这个次数则放弃这个副本。

当Take操作指定的Bucket和Select操作指定的Bucket类型之间隔着几层Bucket时,算法直接深度优先地进入到目的Bucket的直接父母节点。例如,从根节点开始选择N个Host时,它会深度优先地查找到Rack类型的节点,并在这个节点下选取Host节点。为了方便表述,将Rack的所有子节点标记为Local域,将Take指定的Bucket的子节点标记为Descent域,如上图所示。
选取过程中出现冲突、过载或者故障时,算法先在Local域内重新选择,尝试有限次数后,如果仍然找不到满足条件的Bucket,那就回到Descent域重新选择。每次重新选择时,修改副本数目为r += ftotal。因此每次选择失败都会递增ftotal,所以可以尽量避免选择时再次选到冲突的节点。
3.4 Bucket类型
一般而言,CRUSH的开发是为了协调两个计算目标:map计算的高效性和可伸缩性,以及当添加或者移除存储设备后的数据均衡。在最后,CRUSH定义了4种类型的buckets来代表集群架构中的叶子节点:一般的buckets、列表式buckets、树结构buckets以及稻草类型buckets。对于在数据副本存储的进程中的伪随机选择嵌套项,每个类型的bucket都是建立在不同的内部数据结构和充分利用不同c(r,x)函数的基础上,这些buckets在计算和重构效率上发挥着不同的权衡性。一般的bucket会被所以具有相同权重的项限制,然而其它类型的bucket可以在任何组合权重中包含混合项。这些bucket的差异总结如下表所示:

3.4.1 一般的Bucket
这些存储设备纯粹按个体添加进一个大型存储系统。取而代之的是,新型存储系统上存储的都是文件块,就像将机器添加进机架或者整个机柜一样。这些设备在退役后会被分拆成各个零件。在这样的环境下CRUSH中的一般类型Bucket会被当成一个设备集合一样进行使用,例如多个内存组成的计算集合和多个硬盘组成的存储集合。这样做的最大好处在于,CRUSH可以一直map复制品到一般的Bucket中。在这种情况下,正常使用的Bucket就可以和不能正常使用的Bucket直接互不影响。
当我们使用c(r,x)=(hash(x)+rp)函数从m大小的Bucket中选择一个项时,CRUSH会给一个输入值x和一个复制品r,其中,p是从大于m的素数中随机产生。当r<=m时,我们可以使用一些简单的理论数据来选择一个不重复的项。当r>m时,两个不同的r和一个x会被分解成相同的项。实际上,通过这个存储算法,这将意味着出现一个非零数冲突和回退的概率非常小。
如果这个一般类型的Bucket大小发生改变后,数据将会在这些机器上出现完全重组。
bucket的所有子节点都保存在item[]数组之中。perm_x是记录这次随机排布时x的值,perm[]是在perm_x时候对item随机排列后的结果。r则是选择第几个副本。
定位子节点过程。这时我们重新来看uniform定位子节点的过程。根据输入的x值判断是否为perm_x,如果不是,则需要重新排列perm[]数组,并且记录perm_x=x。如果x==perm_x时,这时算R = r%size,算后得到R,最后返回 perm[R]。
/*
* Choose based on a random permutation of the bucket.
*
* We used to use some prime number arithmetic to do this, but it
* wasn't very random, and had some other bad behaviors. Instead, we
* calculate an actual random permutation of the bucket members.
* Since this is expensive, we optimize for the r=0 case, which
* captures the vast majority of calls.
*/
static int bucket_perm_choose(struct crush_bucket *bucket,
int x, int r)
{
unsigned int pr = r % bucket->size;
unsigned int i, s;/* start a new permutation if @x has changed */
if (bucket->perm_x != (__u32)x || bucket->perm_n == 0)
{
dprintk("bucket %d new x=%d\n", bucket->id, x);
bucket->perm_x = x;/* optimize common r=0 case */
if (pr == 0)
{
s = crush_hash32_3(bucket->hash, x, bucket->id, 0) %
bucket->size;
bucket->perm[0] = s;
bucket->perm_n = 0xffff; /* magic value, see below */
goto out;
}for (i = 0; i < bucket->size; i++)
bucket->perm[i] = i;
bucket->perm_n = 0;
}
else if (bucket->perm_n == 0xffff)
{
/* clean up after the r=0 case above */
for (i = 1; i < bucket->size; i++)
bucket->perm[i] = i;
bucket->perm[bucket->perm[0]] = 0;
bucket->perm_n = 1;
}/* calculate permutation up to pr */
for (i = 0; i < bucket->perm_n; i++)
dprintk(" perm_choose have %d: %d\n", i, bucket->perm[i]);
while (bucket->perm_n <= pr)
{
unsigned int p = bucket->perm_n;
/* no point in swapping the final entry */
if (p < bucket->size - 1)
{
i = crush_hash32_3(bucket->hash, x, bucket->id, p) %
(bucket->size - p);
if (i)
{
unsigned int t = bucket->perm[p + i];
bucket->perm[p + i] = bucket->perm[p];
bucket->perm[p] = t;
}
dprintk(" perm_choose swap %d with %d\n", p, p + i);
}
bucket->perm_n++;
}
for (i = 0; i < bucket->size; i++)
dprintk(" perm_choose %d: %d\n", i, bucket->perm[i]);s = bucket->perm[pr];
out:
dprintk(" perm_choose %d sz=%d x=%d r=%d (%d) s=%d\n", bucket->id,
bucket->size, x, r, pr, s);
return bucket->items[s];
}

uniform bucket 适用的情况:
a.适用于所有子节点权重相同的情况,而且bucket很少添加删除item,这种情况查找速度应该是最快的。因为uniform的bucket在选择子节点时是不考虑权重的问题,全部随机选择。所以在权重上不会进行特别的照顾,为了公平起见最好是相同的权重节点。
b.适用于子节点变化概率小的情况。当子节点的数量进行变化时,size发生改变,在随机组合perm数组时,即使x相同,则perm数组需要完全重新排列,也就意味着已经保存在子节点的数据要全部发生重排,造成很多数据的迁移。所以uniform不适合子节点变化的bucket,否则会产生大量已经保存的数据发生移动,所有的item上的数据都可能会发生相互之间的移动。
3.4.2 List类型buckets
List类型的buckets组织其内部的内容会像list的方式一样,并且里面的项都有随机的权重。为了放置一个数据副本,CRUSH在list的头部开始添加项并且和除这些项外其它项的权重进行比较。根据hash(x,r,item)函数的值,每个当前项会根据适合的概率被选择,或者出现继续递归查找该list。这种方法重申了数据存储所存在的问题“是大部分新加项还是旧项?”这对于一个扩展中的集群是一个根本且直观的选择:一方面每个数据对象会根性相应的概率重新分配到新的存储设备上,或者依然像以前一样被存储在旧的存储设备上。这样当新的项添加进到bucket中时这些项会获得最优的移动方式。当这些项从list的中间或者末尾进行移动时,list类型的bucket将比较适合这种环境。
它的结构是链表结构,所包含的item可以具有任意的权重。CRUSH从表头开始查找副本的位置,它先得到表头item的权重Wh、剩余链表中所有item的权重之和Ws,然后根据hash(x, r, i)得到一个[0~1]的值v,假如这个值v在[0~Wh/Ws)之中,则副本在表头item中,并返回表头item的id,i是item的id号。否者继续遍历剩余的链表。
list bucket的形成过程。list bucket 不是真的将所有的item都穿成一个链表,bucket的item仍然保存在item数组之中。这时的list bucket 每个item 不仅要保存的权重(根据容量换算而来)weight,还要记录前所有节点的重量之和sum_weight如图,list bucket的每个item的权重可以不相同,也不需要按顺序排列。

list bucket定位数据在子节点的方法。从head开始,会逐个的查找子节点是否保存数据。
如何判断当前子节点是否保存了数据呢?首先取了一个节点之后,根据x,r 和item的id 进行crush_hash得到一个w值。这个值与sum_weight之积,最后这个w再向右移16位,最后判断这个值与weight的大小,如果小于weight时,则选择当前的这个item,否则进行查找下一个item。
static int bucket_list_choose(struct crush_bucket_list *bucket,
int x, int r)
{
int i;for (i = bucket->h.size - 1; i >= 0; i--)
{
__u64 w = crush_hash32_4(bucket->h.hash, x, bucket->h.items[i],
r, bucket->h.id);
w &= 0xffff;
dprintk("list_choose i=%d x=%d r=%d item %d weight %x "
"sw %x rand %llx",
i, x, r, bucket->h.items[i], bucket->item_weights[i],
bucket->sum_weights[i], w);
w *= bucket->sum_weights[i];
w = w >> 16;
/*dprintk(" scaled %llx\n", w);*/
if (w < bucket->item_weights[i])
return bucket->h.items[i];
}dprintk("bad list sums for bucket %d\n", bucket->h.id);
return bucket->h.items[0];
}

list bucket使用的情况:
a.适用于集群拓展类型。当增加item时,会产生最优的数据移动。因为在list bucket中增加一个item节点时,都会增加到head部,这时其他节点的sum_weight都不会发生变化,只需要将old_head 上的sum_weight和weight之和添加到new_head的sum_weight就好了。这样时其他item之间不需要进行数据移动,其他的item上的数据 只需要和 head上比较就好,如果算的w值小于head的weight,则需要移动到head上,否则还保存在原来的item上。这样就获得了最优最少的数据移动。
b.list bucket存在一个缺点,就是在查找item节点时,只能顺序查找 时间复杂度为O(n)。
3.4.3 树状 Buckets
像任何链表结构一样,列表buckets对于少量的数据项还是高效的,而遇到大量的数据就不合适了,其时间复杂度就太大了。树状buckets由RUSHT发展而来,它通过将这些大量的数据项储存到一个二叉树中来解决这个问题(时间复杂度过大)。它将定位的时间复杂度由 O(n)降低到O(logn),这使其适用于管理大得多设备数量或嵌套buckets。 RUSHT i等价于一个由单一树状bucket组成的二级CRUSH结构,该树状bucket包含了许多一般buckets.
树状buckets是一种加权二叉排序树,数据项位于树的叶子节点。每个递归节点有其左子树和右子树的总权重,并根据一种固定的算法(下面会讲述)进行标记。为了从bucket中选择一个数据项,CRUSH由树的根节点开始(计算),计算输入主键x,副本数量r,bucket标识以及当前节点(初始值是根节点)标志的哈希值,计算的结果会跟(当前节点)左子树和右子树的权重比进行比较,仪确定下次访问的节点。重复这一过程直至到达(存储)相应数据项的叶子节点。定位该数据项最多只需要进行logn次哈希值计算和比较。
该buckett二叉树结点使用一种简单固定的策略来得到二进制数进行标记,以避免当树增长或收缩时标记更改。该树最左侧的叶子节点通常标记为“1”, 每次树扩展时,原来的根节点成为新根节点的左子树,新根节点的标记由原根节点的标记左移一位得到(比如1变成10,10变成100等)。右子树的标记在左子树标记的基础上增加了“1”,拥有6个叶子节点的标记二叉树如图4所示。这一策略保证了当bucket增加(或删除)新数据项并且树结构增长(或收缩)时,二叉树中现有项的路径通过在根节点处增加(或删除)额外节点即可实现,决策树的初始位置随之发生变化。一旦某个对象放入特定的子树中,其最终的mapping将仅由该子树中的权重和节点标记来决定,只要该子树中的数据项不发生变化mapping就不会发生变化。虽然层次化的决策树在嵌套数据项项之间会增加额外的数据迁移,但是这一(标记)策略可以保证移动在可接受范围内,同时还能为非常巨大的bucket提供有效的mapping。

链表的查找复杂度是O(n),决策树的查找复杂度是O(log n)。item是决策树的叶子节点,决策树中的其他节点知道它左右子树的权重,节点的权重等于左右子树的权重之和。CRUSH从root节点开始查找副本的位置,它先得到节点的左子树的权重Wl,得到节点的权重Wn,然后根据hash(x, r, node_id)得到一个[0~1]的值v,假如这个值v在[0~Wl/Wn)中,则副本在左子树中,否者在右子树中。继续遍历节点,直到到达叶子节点。Tree Bucket的关键是当添加删除叶子节点时,决策树中的其他节点的node_id不变。决策树中节点的node_id的标识是根据对二叉树的中序遍历来决定的(node_id不等于item的id,也不等于节点的权重)
tree bucket 会借助一个叫做node_weight[ ]的数组来进行帮助搜索定位item。首先是node_weight[ ]的形成,nodeweight[ ]中不仅包含了item,而且增加了很多中间节点,item都作为叶子节点。父节点的重量等于左右子节点的重量之和,递归到根节点如下图。

tree bucket的搜索过程,通过一定的方法形成node tree。这tree的查找从根节点开始直到找到叶子节点。当前节点的重量weight使用crush_hash(x,r)修正后,与左节点的重量left_weight比较,如果比左节点轻 则继续遍历左节点,否则遍历右节点如下图。所以该类型的bucket适合于查找的,对于变动的集群就没那么合适了。
static int bucket_tree_choose(struct crush_bucket_tree *bucket,
int x, int r)
{
int n;
__u32 w;
__u64 t;/* start at root */
n = bucket->num_nodes >> 1;while (!terminal(n))
{
int l;
/* pick point in [0, w) */
w = bucket->node_weights[n];
t = (__u64)crush_hash32_4(bucket->h.hash, x, n, r,
bucket->h.id) * (__u64)w;
t = t >> 32;/* descend to the left or right? */
l = left(n);
if (t < bucket->node_weights[l])
n = l;
else
n = right(n);
}return bucket->h.items[n >> 1];
}

3.4.4 Straw类型Buckets
列表buckets和树状buckets的结构决定了只有有限的哈希值需要计算并与权重进行比较以确定bucket中的项。这样做的话,他们采用了分而治之的方式,要么给特定项以优先权(比如那些在列表开头的项),要么消除完全考虑整个子树的必要。尽管这样提高了副本定位过程的效率,但当向buckets中增加项、删除项或重新计算某一项的权重以改变其内容时,其重组的过程是次最优的。
Straw类型bucket允许所有项通过类似抽签的方式来与其他项公平“竞争”。定位副本时,bucket中的每一项都对应一个随机长度的straw,且拥有最长长度的straw会获得胜利(被选中)。每一个straw的长度都是由固定区间内基于CRUSH输入 x, 副本数目r, 以及bucket项 i.的哈希值计算得到的一个值。每一个straw长度都乘以根据该项权重的立方获得的一个系数 f(wi),这样拥有最大权重的项更容易被选中。比如c(r,x)=maxi(f(wi)hash(x,r,i)). 尽管straw类型bucket定位过程要比列表bucket(平均)慢一倍,甚至比树状bucket都要慢(树状bucket的时间复杂度是log(n)),但是straw类型的bucket在修改时最近邻项之间数据的移动是最优的。
Bucket类型的选择是基于预期的集群增长类型,以权衡映射方法的运算量和数据移动之间的效率,这样的权衡是非常值得的。当buckets是固定时(比如一个存放完全相同磁盘的机柜),一般类型的buckets是最快的。如果一个bucket预计将会不断增长,则列表类型的buckets在其列表开头插入新项时将提供最优的数据移动。这允许CRUSH准确恰当地转移足够的数据到新添加的设备中,而不影响其他bucket项。其缺点是映射速度的时间复杂度为O(n) 且当旧项移除或重新计算权重时会增加额外的数据移动。当删除和重新计算权重的效率特别重要时(比如存储结构的根节点附近(项)),straw类型的buckets可以为子树之间的数据移动提供最优的解决方案。树状buckets是一种适用于任何情况的buckets,兼具高性能与出色的重组效率。
这种类型让bucket所包含的所有item公平的竞争(不像list和tree一样需要遍历)。这种算法就像抽签一样,所有的item都有机会被抽中(只有最长的签才能被抽中)。每个签的长度是由length = f(Wi)*hash(x, r, i) 决定的,f(Wi)和item的权重有关,i是item的id号。c(r, x) = MAX(f(Wi) * hash(x, r, i))。
这种类型是一种抽签类型的bucket,他选择子节点是公平的,straw和uniform的区别在于,straw算法考虑了子节点的权重,所以是最公平的bucket类型。

straw bucket首先根据每个节点的重量生成的straw,最后组成straw[] 数组。在straw定位副本的过程中,每一个定位都需要遍历所有的item,长度draw = crush(x,r,item_id)*straw[i]。找出那个最长的,最后选择这个最长,定位到副本。
static int bucket_straw_choose(struct crush_bucket_straw *bucket,
int x, int r)
{
__u32 i;
int high = 0;
__u64 high_draw = 0;
__u64 draw;for (i = 0; i < bucket->h.size; i++)
{
draw = crush_hash32_3(bucket->h.hash, x, bucket->h.items[i], r);
draw &= 0xffff;
draw *= bucket->straws[i];
if (i == 0 || draw > high_draw)
{
high = i;
high_draw = draw;
}
}
return bucket->h.items[high];
}
3.5 CRUSH RULE
crush rule主要有3个重点:a.从OSDMap中的哪个节点开始查找,b.使用那个节点作为故障隔离域,c.定位副本的搜索模式(广度优先 or 深度优先)。
# rules
rule replicated_ruleset #规则集的命名,创建pool时可以指定rule集
{
ruleset 0 #rules集的编号,顺序编即可
type replicated #定义pool类型为replicated(还有esurecode模式)
min_size 1 #pool中最小指定的副本数量不能小1\
max_size 10 #pool中最大指定的副本数量不能大于10
step take default #定义pg查找副本的入口点
step chooseleaf firstn 0 type host #选叶子节点、深度优先、隔离host
step emit #结束
}
pg 选择osd的过程,首先要知道在rules中 指明从osdmap中哪个节点开始查找,入口点默认为default也就是root节点,然后隔离域为host节点(也就是同一个host下面不能选择两个子节点)。由default到3个host的选择过程,这里由default根据节点的bucket类型选择下一个子节点,由子节点再根据本身的类型继续选择,知道选择到host,然后在host下选择一个osd。
还在学习阶段,整理了一些资料,自己也看了看crush的代码实现,后续有新理解再增加内容,有错误恳请指教。
参考资料:
CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
作者:一只小江 http://my.oschina.net/u/2460844/blog/531722?fromerr=ckWihIrE
作者:刘世民(Sammy Liu)http://www.cnblogs.com/sammyliu/p/4836014.html
作者:吴香伟 http://www.cnblogs.com/shanno/p/3958298.html?utm_source=tuicool&utm_medium=referral
感谢以上作者的无私分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号