《黑马-机学》一、简介概念、机学书

课程定位以及学习目标
课程定位:
- 以算法、案例为驱动的学习,浅显易懂的数学知识
- 注意:参考书比较晦涩难懂,不建议去直接读
课程目标
- 熟悉机器学习各类算法的原理
- 掌握算法的使用,能够结合场景解决实际问题
- 掌握使用机器学习算法库和框架的技能
第一天
大纲:
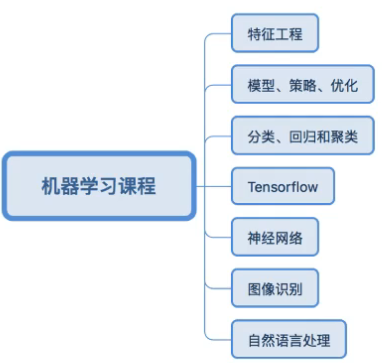
1、机器学习概述
2、数据集的结构
3、数据的特征工程
4、数据的类型
5、机器学习算法基础
什么是机器学习:
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测。
例:alphaGo学习,预测人类,取得胜利

例2 :搜索引擎自动预测你想要的东西,进行推荐
为什么要机器学习
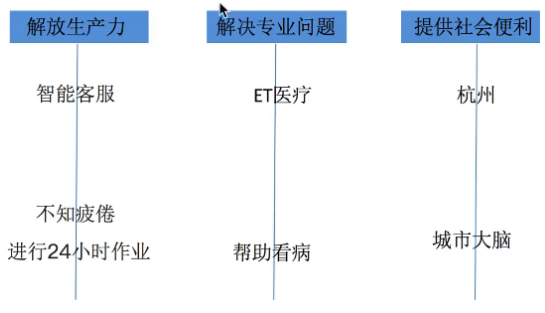
机器学习在各领域带来的价值领域:医疗、航空、教育、物流、电商.
目的:让机器学习程序替换手动的步骤,减少企业的成本也提高企业的效率
例子:一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会
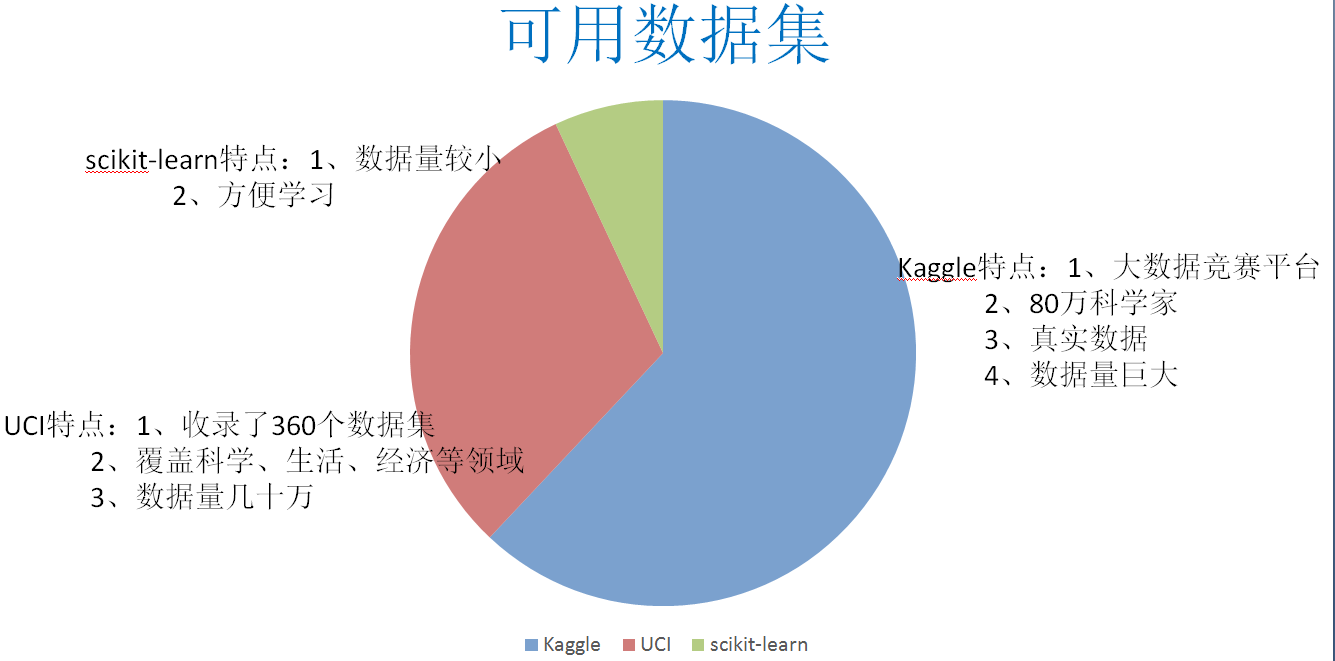
常用数据集
Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
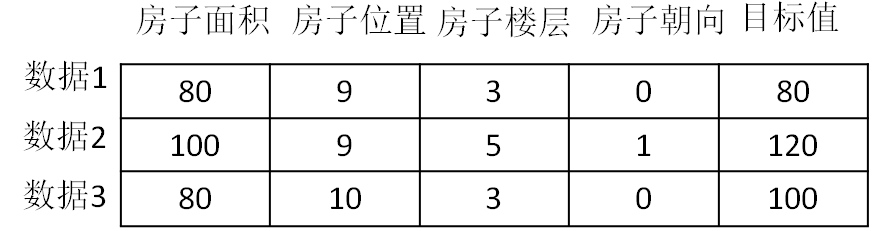
常用数据集数据的结构组成
结构:特征值+目标值(有些数据集可以没有目标值)
数据:也叫(样本)
常用工具:
pandas:一个读取数据非常方便、及处理基本格式的工具
sklearn:对特征的处理提供了强大的接口
机器学习:重复值,不需要去重
特征工程:
【定义】特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
特征:如人 的皮肤颜色,黄白黑要转化成机器可处理的数据(数字形式)
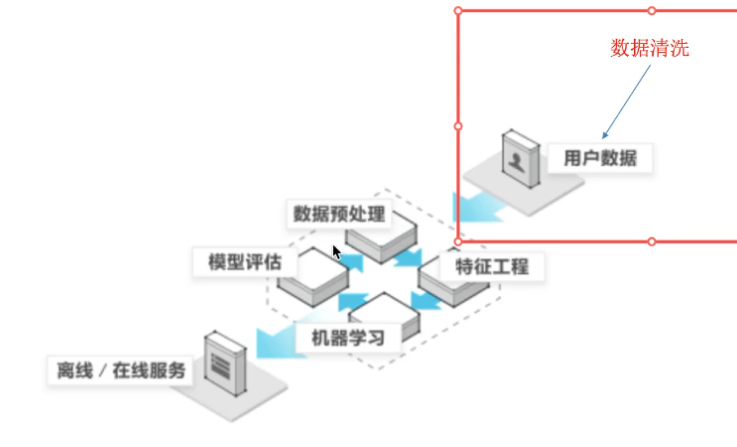
特征工程:
- 特征工程是什么
- 特征工程的意义
- scikit-learn库介绍
- 数据的特征抽取
- 数据的特征处理
- 数据的特征选择
Scikit-learn库介绍
- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。
- 目前稳定版本0.18
- 包含机学算法:
![]()

安装:
#1.创建一个基于Python3的虚拟环境(可以在你自己已有的虚拟环境中): mkvirtualenv –p /usr/bin/python3.5 ml3 #2.在ubuntu的虚拟环境当中运行以下命令 pip3 install Scikit-learn #3.然后通过导入命令查看是否可以使用: import sklearn
注:
- 安装scikit-learn需要Numpy,pandas等库
- 虚拟环境安装:https://www.cnblogs.com/chenxi188/p/10700608.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号