8.scrapy的第一个实例
【目标】要完成的任务如下:
※ 创建一个 Scrap项目。
※ 创建一个 Spider来抓取站点和处理数据。
※ 通过命令行将抓取的内容导出。
※ 将抓取的内容保存的到 MongoDB数据库。
==============================================
【准备工作】需要安装好 Scrapy框架、 MongoDB和 PyMongo库
1.创建项目:
【操作】在想创建项目的目录按:shift+右键——在此处打开命令窗口(或 在cmd里cd进入想要的目录)输入CMD命令(此处不用test,因为系统已经有一个此名字,将报错提示已存在):
注意:在linux 系统内如提示权限问题,则在命令前加 sudo ~
scrapy startproject tutorial # 生成项目命令:最后跟的参数tutorial是项目名,也将是文件夹名
【说明】生成的目录结构如下:
tutorial # 项目总文件夹 tutorial # tutorial文件夹:保存的是要引用的模块; crapy.cfg # cfg文件:是scrapy部署时的配置文件;
【说明】../tutorial/tutorial 目录下文件及作用:
tutorial
__init__.py items.py # Items的定义,定义爬取的数据结构 middlewares.py # Middlewares的定义,定义爬取时的中间件 pipelines. py # Pipelines的定义,定义数据管道 settings.py # 配置文件 spiders # 放置 Spiders的文件夹 __init__.py
2.创建 Spider
【操作】Spider是自己定义的类, Scrapy用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy提供的 Spider类 scrapy. Spider,还要定义Spider的名称和起始请求,以及怎样处理爬取后的结果的方法。也可以使用命令行创建一个 Spider。比如要生成 quotes这个 Spider,可以执行如下cmd命令
【命令解释】进入刚才创建的tutorial文件夹,然后执行 genspider命令:第一个参数是 Spider的名称,第二个参数是网站域名:
cd tutorial
scrapy genspider quotes quotes.toscrape.com
【说明】执行完毕之后, spiders文件夹中多了一个 quotes. py(目录:E:\a\scrapy_test\tutorial\tutorial\spiders),它就是刚刚创建的 Spider,内容如下(其网址,名仅作表示,真代码见4步):
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = 'baidu' allowed_domains = ['fanyi.baidu.com\'] start_urls = ['http://fanyi.baidu.com\'] def parse(self, response): pass
【说明】这里有三个属性—name、 allowed domains和 start urls,还有一个方法 parse:
★name:它是每个项目唯一的名字,用来区分不同的 Spider
★allowed domains:它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
★start urls:它包含了 Spider在启动时爬取的url列表,初始请求是由它来定义的。
★parse:它是 Spider的一个方法。默认情况下,被调用时 start urls里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
3.创建ltem
【说明】Item是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,ltem多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建Iem需要继承 scrapy.Item类,并且定义类型为 scrapy. Field的字段。
【操作】定义Item,观察目标网站,我们可以获取到到内容有text、author、tags。此时将 Items.py修改如下:
import scrapy class QuoteItem(scrapy.Item) text= scrapy. Field() author= scrapy. Field() tags= scrapy. Field() #这里定义了三个字段,接下来爬取时我们会使用到这个Item。
4.解析response
【说明】quotes.py中我们看到, parse()方法的参数 respose是 start urls里面的链接爬取后的结果。所以在parse()方法中,我们可以直接对 response变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
【网页分析】我们可以看到网页中既有我们想要的结果,又有下一页的链接,这两部分内容我们都要进行处理。首先看看网页结构,如图13-2所示。每一页都有多个class为 quote的区块,每个区块内都包含text、 author、tags。那么我们先找出所有的 quote,然后提取每一个 quote中的内容。

quotes.py写成如下:
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): quotes=response.css('.quote') for quote in quotes: text=quote.css('.text::text').extract_first() author=quote.css('.author::text').extract_first() tags=quote.css('.tags .tag::text').extract()
#或<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
tags=quote.css('.keywords::attr(content)').extract_first()
5.使用Item
【说明】上文定义了Item,接下来就要使用它了。Item可以理解为一个字典,不过在声明的时候需要实例化。然后依次用刚才解析的结果赋值Item的每一个字段,最后将Item返回即可。
Quotes Spider的改写quotes.py如下所示:
# -*- coding: utf-8 -*- import scrapy from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider): name = "quotes" allowed_domains = ["quotes.toscrape.com"] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): quotes = response.css('.quote') for quote in quotes: item = QuoteItem() item['text'] = quote.css('.text::text').extract_first() item['author'] = quote.css('.author::text').extract_first() item['tags'] = quote.css('.tags .tag::text').extract() yield item
【代码解释】如此,所有首页内容被解析出来,赋值成一个个QuotesItem
6.后续Request(生成下一页请求)
【说明】抓取下一页内容:从当前页找到一个信息,生成下一页请求,从而往复迭代,抓取整站
【分析】找到下一页面按钮分析源码:
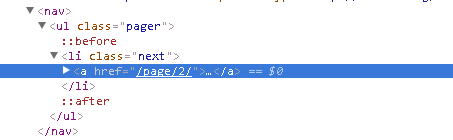
【方法说明】构造请求需用到:scrapy.Request(url=url, callback=self.parse)
参数1:url是请求的链接;
参数2:callback是回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或生成下一个请求,回调函数即刚写的 parse()函数。
由于 parse()就是解析text、 author、tags的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用 parse()方法来做页面解析。
【操作】写的下一页代码如下:
next = response.css('.pager .next a::attr(href)').extract_first() url = response.urljoin(next) yield scrapy.Request(url=url, callback=self.parse)
【源码说明】:
第1行首先通过CSS选择器获取下一个页面的链接,即要获取a超链接中的href属性。这里用到了:attr(href)操作。然后再调用 extract first()方法获取内容。
第2行调用了 urljoin()方法, urljoin()方法可以将相对URL构造成一个绝对的URL。例如,获取到的下一页地址是page2, unjoint()方法处理后得到的结果就是:htp/ quotes.toscrape. com/page/2/
第3行通过ur1和 callback变量构造了一个新的请求,回调函数 callback依然使用 parse()方法。这个请求完成后,响应会重新经过 parse方法处理,得到第2页的解析结果,然后生成第2页的下一页,即第3页的请求
这样爬虫就进入了一个循环,直到最后一页。通过几行代码,我们就轻松实现了一个抓取循环,将每个页面的结果抓取下来了
【quotes.py 最终代码】如下:
# -*- coding: utf-8 -*- import scrapy from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider): name = "quotes" allowed_domains = ["quotes.toscrape.com"] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): quotes = response.css('.quote') for quote in quotes: item = QuoteItem() item['text'] = quote.css('.text::text').extract_first() item['author'] = quote.css('.author::text').extract_first() item['tags'] = quote.css('.tags .tag::text').extract() yield item next = response.css('.pager .next a::attr(href)').extract_first() url = response.urljoin(next) yield scrapy.Request(url=url, callback=self.parse)
7.运行爬虫
【运行前】记得把 settings.py中的,顺从爬虫规则去年注释,并改成False,否则,默认为Ture,可能会过滤掉许多网址
# Obey robots.txt rules,默认为Ture,即按网站规则来,把有些网址过滤掉 ROBOTSTXT_OBEY = False
【运行爬虫】进入项目目录(E:\a\scrapy_test\tutorial),运行命令即可运行爬虫,进行爬取:
scrapy crawl quotes
【结果】如下:


scrapy crawl quotes 'tags': ['friendship', 'love'], 'text': '“There is nothing I would not do for those who are...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Eleanor Roosevelt', 'tags': ['attributed', 'fear', 'inspiration'], 'text': '“Do one thing every day that scares you.”'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Marilyn Monroe', 'tags': ['attributed-no-source'], 'text': '“I am good, but not an angel. I do sin, but I am n...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Albert Einstein', 'tags': ['music'], 'text': '“If I were not a physicist, I would probably be a...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Haruki Murakami', 'tags': ['books', 'thought'], 'text': '“If you only read the books that everyone else is...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Alexandre Dumas fils', 'tags': ['misattributed-to-einstein'], 'text': '“The difference between genius and stupidity is: g...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Stephenie Meyer', 'tags': ['drug', 'romance', 'simile'], 'text': "“He's like a drug for you, Bella.”"} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Ernest Hemingway', 'tags': ['books', 'friends', 'novelist-quotes'], 'text': '“There is no friend as loyal as a book.”'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'Helen Keller', 'tags': ['inspirational'], 'text': '“When one door of happiness closes, another opens;...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/6/> {'author': 'George Bernard Shaw', 'tags': ['inspirational', 'life', 'yourself'], 'text': "“Life isn't about finding yourself. Life is about..."} 2019-04-26 13:53:50 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes .toscrape.com/page/7/> (referer: http://quotes.toscrape.com/page/6/) 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Charles Bukowski', 'tags': ['alcohol'], 'text': "“That's the problem with drinking, I thought, as I..."} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Suzanne Collins', 'tags': ['the-hunger-games'], 'text': '“You don’t forget the face of the person who was y...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Suzanne Collins', 'tags': ['humor'], 'text': "“Remember, we're madly in love, so it's all right..."} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'C.S. Lewis', 'tags': ['love'], 'text': '“To love at all is to be vulnerable. Love anything...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'J.R.R. Tolkien', 'tags': ['bilbo', 'journey', 'lost', 'quest', 'travel', 'wander'], 'text': '“Not all those who wander are lost.”'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'J.K. Rowling', 'tags': ['live-death-love'], 'text': '“Do not pity the dead, Harry. Pity the living, and...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Ernest Hemingway', 'tags': ['good', 'writing'], 'text': '“There is nothing to writing. All you do is sit do...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Ralph Waldo Emerson', 'tags': ['life', 'regrets'], 'text': '“Finish each day and be done with it. You have don...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Mark Twain', 'tags': ['education'], 'text': '“I have never let my schooling interfere with my e...'} 2019-04-26 13:53:50 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/7/> {'author': 'Dr. Seuss', 'tags': ['troubles'], 'text': '“I have heard there are troubles of more than one...'} 2019-04-26 13:53:51 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes .toscrape.com/page/8/> (referer: http://quotes.toscrape.com/page/7/) 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Alfred Tennyson', 'tags': ['friendship', 'love'], 'text': '“If I had a flower for every time I thought of you...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Charles Bukowski', 'tags': ['humor'], 'text': '“Some people never go crazy. What truly horrible l...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Terry Pratchett', 'tags': ['humor', 'open-mind', 'thinking'], 'text': '“The trouble with having an open mind, of course,...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Dr. Seuss', 'tags': ['humor', 'philosophy'], 'text': '“Think left and think right and think low and thin...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'J.D. Salinger', 'tags': ['authors', 'books', 'literature', 'reading', 'writing'], 'text': '“What really knocks me out is a book that, when yo...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'George Carlin', 'tags': ['humor', 'insanity', 'lies', 'lying', 'self-indulgence', 'truth'], 'text': '“The reason I talk to myself is because I’m the on...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'John Lennon', 'tags': ['beatles', 'connection', 'dreamers', 'dreaming', 'dreams', 'hope', 'inspirational', 'peace'], 'text': "“You may say I'm a dreamer, but I'm not the only o..."} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'W.C. Fields', 'tags': ['humor', 'sinister'], 'text': '“I am free of all prejudice. I hate everyone equal...'} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Ayn Rand', 'tags': [], 'text': "“The question isn't who is going to let me; it's w..."} 2019-04-26 13:53:51 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/8/> {'author': 'Mark Twain', 'tags': ['books', 'classic', 'reading'], 'text': "“′Classic′ - a book which people praise and don't..."} 2019-04-26 13:53:52 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes .toscrape.com/page/9/> (referer: http://quotes.toscrape.com/page/8/) 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Albert Einstein', 'tags': ['mistakes'], 'text': '“Anyone who has never made a mistake has never tri...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Jane Austen', 'tags': ['humor', 'love', 'romantic', 'women'], 'text': "“A lady's imagination is very rapid; it jumps from..."} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'J.K. Rowling', 'tags': ['integrity'], 'text': '“Remember, if the time should come when you have t...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Jane Austen', 'tags': ['books', 'library', 'reading'], 'text': '“I declare after all there is no enjoyment like re...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Jane Austen', 'tags': ['elizabeth-bennet', 'jane-austen'], 'text': '“There are few people whom I really love, and stil...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'C.S. Lewis', 'tags': ['age', 'fairytales', 'growing-up'], 'text': '“Some day you will be old enough to start reading...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'C.S. Lewis', 'tags': ['god'], 'text': '“We are not necessarily doubting that God will do...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Mark Twain', 'tags': ['death', 'life'], 'text': '“The fear of death follows from the fear of life....'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'Mark Twain', 'tags': ['misattributed-mark-twain', 'truth'], 'text': '“A lie can travel half way around the world while...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/9/> {'author': 'C.S. Lewis', 'tags': ['christianity', 'faith', 'religion', 'sun'], 'text': '“I believe in Christianity as I believe that the s...'} 2019-04-26 13:53:52 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes .toscrape.com/page/10/> (referer: http://quotes.toscrape.com/page/9/) 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'J.K. Rowling', 'tags': ['truth'], 'text': '“The truth." Dumbledore sighed. "It is a beautiful...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'Jimi Hendrix', 'tags': ['death', 'life'], 'text': "“I'm the one that's got to die when it's time for..."} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'J.M. Barrie', 'tags': ['adventure', 'love'], 'text': '“To die will be an awfully big adventure.”'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'E.E. Cummings', 'tags': ['courage'], 'text': '“It takes courage to grow up and become who you re...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'Khaled Hosseini', 'tags': ['life'], 'text': '“But better to get hurt by the truth than comforte...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'Harper Lee', 'tags': ['better-life-empathy'], 'text': '“You never really understand a person until you co...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': "Madeleine L'Engle", 'tags': ['books', 'children', 'difficult', 'grown-ups', 'write', 'writers', 'writing'], 'text': '“You have to write the book that wants to be writt...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'Mark Twain', 'tags': ['truth'], 'text': '“Never tell the truth to people who are not worthy...'} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'Dr. Seuss', 'tags': ['inspirational'], 'text': "“A person's a person, no matter how small.”"} 2019-04-26 13:53:52 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes .toscrape.com/page/10/> {'author': 'George R.R. Martin', 'tags': ['books', 'mind'], 'text': '“... a mind needs books as a sword needs a whetsto...'} 2019-04-26 13:53:52 [scrapy.dupefilters] DEBUG: Filtered duplicate request: <GET http://quotes.toscrape.com/page/10/> - no more duplicates will be shown (see DU PEFILTER_DEBUG to show all duplicates) 2019-04-26 13:53:52 [scrapy.core.engine] INFO: Closing spider (finished) 2019-04-26 13:53:52 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 2870, 'downloader/request_count': 11, 'downloader/request_method_count/GET': 11, 'downloader/response_bytes': 24812, 'downloader/response_count': 11, 'downloader/response_status_count/200': 10, 'downloader/response_status_count/404': 1, 'dupefilter/filtered': 1, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 4, 26, 5, 53, 52, 939800), 'item_scraped_count': 100, 'log_count/DEBUG': 112, 'log_count/INFO': 9, 'request_depth_max': 10, 'response_received_count': 11, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/404': 1, 'scheduler/dequeued': 10, 'scheduler/dequeued/memory': 10, 'scheduler/enqueued': 10, 'scheduler/enqueued/memory': 10, 'start_time': datetime.datetime(2019, 4, 26, 5, 53, 38, 767800)} 2019-04-26 13:53:52 [scrapy.core.engine] INFO: Spider closed (finished) C:\Users\Administrator\Desktop\py\scrapytutorial>
【解释】结果:
a) 首先Scrap输出了当前的版本号以及正在启动的项目名称。
b) 接着输出了当前 settings. py中一些重写后的配置。
c) 然后输出了当前所应用的 Middlewares和 Pipelines Middlewares默认是启用的,可以在 settings.py中修改。
d) Pipelines默认是空,同样也可以在 settings. py中配置。后面会对它们进行讲解。
e) 接下来就是输出各个页面的抓取结果了,可以看到爬虫一边解析,一边翻页,直至将所有内容抓取完毕,然后终止。
f) 最后, Scrap输出了整个抓取过程的统计信息,如请求的字节数、请求次数、响应次数、完成原因等。
整个 Scrap程序成功运行。我们通过非常简单的代码就完成了一个网站内容的爬取,这样相比之前一点点写程序简洁很多。
8.1保存到文件json csv xml pickle marshal
【说明】运行完 Scrap后,我们只在控制台看到了输出结果。如果想保存结果可直接用, Scrap提供的【 Feed Exports】轻松将抓取结果输出。
【操作a】 将上面的结果【保存成JSON文件】,可以执行如下命令:
#CMD命令,完成后,目录下多出一个quotes.json文件即结果 scrapy crawl quotes -o quotes.json
【操作b】还可以【每一个Item输出一行】JSON,输出后缀为jl,为 jsonline的缩写,命令如下所示:
#cmd命令:每个item导出为一行的joson文件。写法1 scrapy crawl quotes -o quotes.jl #-----或-------: #cmd命令:每个item导出为一行的joson文件.写法2 scrapy crawl quotes -o quotes.jsonlines
【操作c】其它格式输出:
1.输出格式还支持很多种,例如csv、xml、 pickle、 marshal等,还支持仰、s3等远程输出;
2.另外还可以通过自定义 ItemExporter来实现其他的输出。
【操作】下面命令对应的输出分别为【csv、xml、 pickle、 marshal格式、ftp远程输出】:
#cmd命令:其它格式输出 scrapy crawl quotes -o quotes.csv scrapy crawl quotes -o quotes.xml scrapy crawl quotes -o quotes.pickle scrapy crawl quotes -o quotes.marshal #ftp输出需要正确配置用户名、密码、地址、输岀路径,否则会报错。其它ftp文件格式参考上一段 scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
8.2其它复杂格式输出(用Pipline.py 输出到数据库)
【引言】通过 Scrap提供的 Feed Exports,我们可以轻松地输出抓取结果到文件。对于一些小型项目来说,这应该足够了。如想要更复杂的输出,如输出到数据库等,则可用 Item Pipeline来完成
【目标】如果想进行更复杂的操作,如【将结果保存到 MongoDB数据库】,或者筛选某些有用的Iem,则我们可以定义 Item Pipeline来实现
【操作说明】Item Pipeline为项目管道。当Item生成后,它会自动被送到 Item Pipeline进行处理,我们【常用ltem Pipeline来做如下操作】:
§ 清理HTML数据。
§ 验证爬取数据,检查爬取字段。
§ 查重并丢弃重复内容。
§ 将爬取结果保存到数据库。
【用到的方法】很简单,只需要定义一个类并实现 process_item()方法即可。启用 Item Pipeline后, Item Pipeline会自动调用这个方法:
process_item()方法必须返回包含数据的字典或Item对象 或 者抛出 DropItem异常。
process_item()方法有两个参数。一个参数是item,每次 Spider生成的Item都会作为参数传递过来。
另一个参数是 spider,就是 Spider的实例。
【实操】接下来,我们实现一个 Item Pipeline,筛掉text长度大于50的Item,并将结果保存到 MongoDB:
【步骤1】修改项目里的 [ pipelines.py ] 文件,之前用命令行自动生成的文件内容可以删掉,增加一个TextPipeline类,内容如下所示:
import pymongo from scrapy.exceptions import DropItem #新写部分 class TextPipeline(object): def __init__(self): self.limit = 50 def process_item(self, item, spider): if item['text']: if len(item['text']) > self.limit: item['text'] = item['text'][0:self.limit].rstrip() + '...' return item else: return DropItem('Missing Text')
【代码说明】:这段代码在构造方法里定义了限制长度为50,实现了 process item()方法,其参数是item和spider。首先该方法判断item的text属性是否存在,如果不存在,则抛出 DropItem异常;如果存在,再判断长度是否大于50,如果大于,那就截断然后拼接省略号,再将item返回即可。
【步骤2】接下来,我们将处理后的【item存入 MongoDB】,定义另外一个 Pipeline。同样在 pipelines. py中,我们实现另一个类 MongoPipeline,内容如下所示:
class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def process_item(self, item, spider): name = item.__class__.__name__ self.db[name].insert(dict(item)) return item def close_spider(self, spider): self.client.close()
【步骤3】MongoPipeline类实现了API定义的另外几个方法。
§ from crawler。它是一个类方法,用@ classmethod标识,是一种依赖注入的方式。它的参数就是 crawler,通过 crawler我们可以拿到全局配的每个配置信息。在全局配置 settings.py中,我们可以定义 MONGO URI和MoN0DB来指定 MongoDB连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取 settings. py中的配置的。
§ open spider。当 Spider开启时,这个方法被调用。上文程序中主要进行了一些初始化操作
§ close spider。当 Spider关闭时,这个方法会调用。上文程序中将数据库连接关闭。
最主要的 process item()方法则执行了数据插入操作。定义好 TextPipeline和 MongoPipeline这两个类后,我们需要在 [ settings.py ] 中使用它们 MongoDB的连接信息还需要定义,在其中加入如下信息:
ITEM_PIPELINES = { 'tutorial.pipelines.TextPipeline': 300, 'tutorial.pipelines.MongoPipeline': 400, } MONGO_URI='localhost' MONGO_DB='tutorial'
【代码说明】赋值 ITEM PIPELINES字典,键名是 Pipeline的类名称,键值是调用优先级,是一个数字,数字越小则对应的 Pipeline越先被调用。
【步骤4】再重新执行爬取,命令如下所示:
#重新运行,爬取 scrapy crawl quotes
【代码说明】爬取结束后, MongoDB中创建了一个 tutorial的数据库、 Quoteltem的表,如图所示:
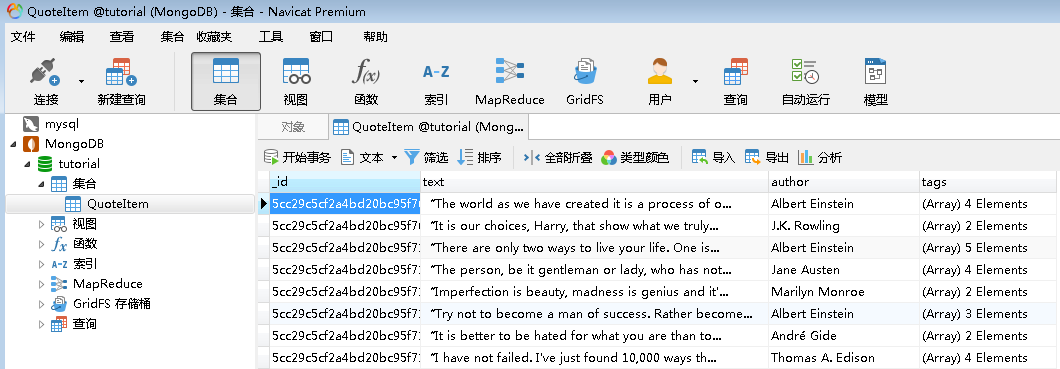
【说明】其中text长的部分已经被追加省略号…短的不变,其它author,tags也有加入其中
【结语】至此已经完成最简单用scrapy爬取quotes网站。但更复杂的功能还需进一步学习。
实例代码
quote.py
# -*- coding: utf-8 -*- import scrapy from tutorial.items import TutorialItem class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): quotes=response.css(".quote") for quote in quotes: item=TutorialItem() item['text']=quote.css(".text::text").extract_first() item['author']=quote.css('.author::text').extract_first() #tags=quote.css('.tags .tag::text').extract() #或<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world"> item['tags']=quote.css('.keywords::attr(content)').extract_first() yield item #print(text,author,tags) #下一页 next=response.css('.next >a::attr(href)').extract_first() #函数.urljoin()把当前网址:http://quotes.toscrape.com/+next获取的 拼接成完整网址 url=response.urljoin(next) yield scrapy.Request(url=url, callback=self.parse)
settings.py
# -*- coding: utf-8 -*- # Scrapy settings for tutorial project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'tutorial' SPIDER_MODULES = ['tutorial.spiders'] NEWSPIDER_MODULE = 'tutorial.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'tutorial (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'tutorial.middlewares.TutorialSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'tutorial.middlewares.TutorialDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'tutorial.pipelines.TutorialPipeline': 300, #} ITEM_PIPELINES = { 'tutorial.pipelines.TutorialPipeline': 300, 'tutorial.pipelines.MongoPipeline': 400, } MONGO_URI='localhost' MONGO_DB='tutorial2' # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
piplines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo from scrapy.exceptions import DropItem class TutorialPipeline(object): def __init__(self): self.limit=50 def process_item(self, item, spider): if item['text']: if len(item['text']) > self.limit: item['text']=item['text'][0:self.limit].rstrip()+"..." return item else: return DropItem("text were missing!") class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def process_item(self, item, spider): name = item.__class__.__name__ self.db[name].insert(dict(item)) return item def close_spider(self, spider): self.client.close()
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class TutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() text=scrapy.Field() author=scrapy.Field() tags=scrapy.Field() #pass
main.py
# -*- coding: utf-8 -*- __author__='pasaulis' #在程序中运行命令行,方法调试,如:在jobbole.py中打个断点,运行就会停在那 from scrapy.cmdline import execute import sys,os #获取到当前目录:E:\a\scrapy_test\Aticle,方便后面cmd命令运行不必去找目录 sys.path.append(os.path.dirname(os.path.abspath(__file__))) #测试目录获取是否正确 # print(os.path.dirname(os.path.abspath(__file__))) #调用命令运行爬虫scrapy crawl quotes execute(["scrapy","crawl","quotes"])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号