
15.javaweb XML详解教程

1, 作用:用于描述和保存现实中具有某种关系的数据,还可以作为软件配置文件,和描述程序模块之间的关系

2, 语法:
首先 先看一个XML文件的组成部分

关于文档声明

Version同时使用为w3c在2000年颁布的1.0版本,encoding指明浏览器在解析xml文件是编码,必须与xml文件保存的是编码一致,否则会出现乱码文件,因为xml文件在保存时是按照某编码规则将中文编码成二进制数,浏览器再解析的时候按照此编码可将二进制数解析成正确中文,否则将报错。
关于元素,即标签,一个xml文档中有且只有一个根标签,标签分含标签体<a>***</a>和不含标签体<a/>,标签体中的空格和换行都会被当作标签内容处理。对于标签的命名规范如下

关于属性,一个标签中可以有多个属性,属性由属性名和值组成,属性名命名规范与元素一样,小技巧”可以将一个属性改写成标签的一个子标签
关于注释:<!--注释-->,注释不能在文档声明之前,也不能嵌套
关于CDATA区

关于转义字符
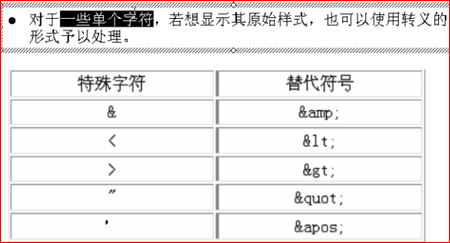
关于转义与CDATA区别,转义是把XML中特殊字符显示出来给人看,CDATA是把XML中内容读给程序看
关于处理指令

应用
XML文件

结果

3, DTD约束和DTD校验
概述:在XML技术里可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束
约束分类:XML DTD,XML Schema
XML DTD

<! DOCTYPE 暑假 SYSTEM “book.dtd”> 表示引用book.tdt约束来约束XML文档的书写规范
<! ELEMENT 书架 (书+)>表示在”书架”这个标签中,可以有多个“书”子标签
<! ELEMENT 书(书名,作者,售价)>表示”书”这个标签中,应该有“书名”,“作者”,“售价”这个三个子标签
<! ELEMENT 书名 (#PCDATA)>表示”书名”这个标签中的内容应该是字符串
XML DTD文档的编写:DTD约束既可作为一个单独的文件编写,也可以XML文件内编写
上述例子即为单独文件编写,下面是在一个XML文件内编写

DTD文档的引用

DTD约束语法:元素定义,属性定义,实体定义
元素定义


属性定义

设置说明

属性值类型:枚举

属性值类型:ID

常用属性值类型

实体定义:概念

实体定义:引用实体

实体定义:参数实体

4, xml编程(CRUD)
XML解析技术

关于dom和sax的区别
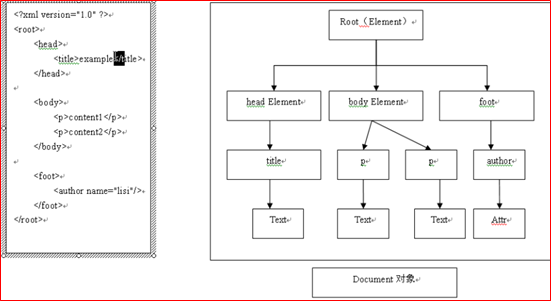
dom解析是把XML的节点以文档对象的形式保存的内存中,对象之间以树的形式组织,所以dom解析适合对XML文件增删改查,但对内存消耗较大
sax解析是一行一行的读取XML文件并解析,所以sax解析对内存消耗较小,解析速度快,但不适合增删改查
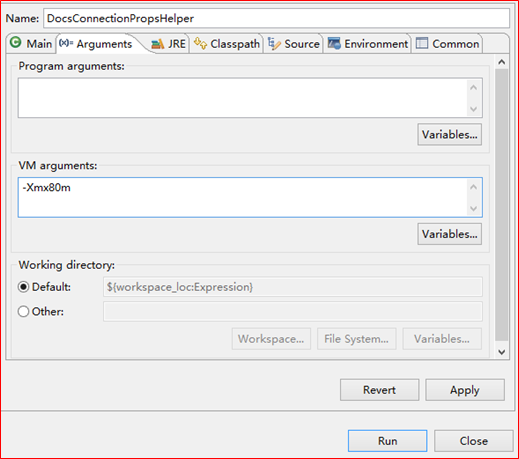
调整jvm最大占用内存大小:JVM默认程序的最大可占用内存是64M,当程序运行所需内存超过了这个值就会报错
可通过如下方式设置程序运行时最大可占用内存,设置值为80M
5, JAXP解析包对XML文档进行dom解析

注意导入javax.xml.parsers包
dom解析下,xml文档的每一个组成部分都会用一个对象表示,例如标签用Element,属性用Attr,但不管什么对象都是Node的子类,所以在开发中可以获取到的任何结点都当作Node对待。
package com.chen.ying; import java.io.FileOutputStream; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import javax.xml.transform.stream.StreamSource; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; public class paraseDemo01 { public static void main(String[] args) throws Exception { //1,创建工厂,得到工厂实例 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //2,通过工厂得到dom解析器 DocumentBuilder builder=factory.newDocumentBuilder(); //3,解析XML文档,得到代表文档的document对象 Document document=builder.parse("src/com/chen/ying/country.xml");//最好填写绝对路径 //4,对XML文档进行增删改查 //查询结点 NodeList list01=document.getElementsByTagName("province");//将查询结果放在Node链表中 Node node01=list01.item(1);//取得链表的第二个元素; String content01=node01.getTextContent();//得到结点内容 System.out.println("查询到的省份信息:"+content01); //遍历所有结点 Node node02=document.getElementsByTagName("country").item(0);//得到根结点 listAll(node02);//递归遍历 //查询指定结点的指定属性,如果已知查询结果是元素,则可以直接用Element接收,这样操作更丰富准确 Element element01=(Element)document.getElementsByTagName("province").item(0);//取得“四川”结点 String value=element01.getAttribute("id");//由属性名得到属性值 System.out.println(value); //向XML"四川"结点中添加结点:<city>遂宁</city> Element city=document.createElement("city"); city.setTextContent("遂宁");//创建结点并向结点添加内容 Element province01=(Element)document.getElementsByTagName("province").item(0); province01.appendChild(city);//将创建的结点挂到指定的节点下 //向指定位置处添加节点:<city>丽江</city> Element insertCity=document.createElement("city"); insertCity.setTextContent("丽江");//创建结点并向结点添加内容 //得到挂子节点 Element province02=(Element)document.getElementsByTagName("province").item(1); //得到位置参考节点 Element localCity=(Element)province02.getElementsByTagName("city").item(1); //向挂子节点的指定位置插入节点 province02.insertBefore(insertCity, localCity); //为指定节点添加属性 element01.setAttribute("mainCity", "成都");//为“四川”节点添加属性 //删除指定节点和属性:删除指定节点需要找到这个节点和这个节点的·父节点 Element province03=(Element)document.getElementsByTagName("province").item(2); province03.getParentNode().removeChild(province03); //更新结点内容:找到需要更新的节点然后重新设置内容 Element city01=(Element)document.getElementsByTagName("city").item(0); city01.setTextContent("绵阳"); //将更新后的内存写回XML文档所在硬盘区 TransformerFactory tfactory=TransformerFactory.newInstance(); Transformer tf=tfactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("src/com/chen/ying/country.xml"))); } public static void listAll(Node node) { if(node instanceof Element){//如果结点是元素则打印(解析时会将一个结点内所有内容解析成对象) System.out.println(node); } NodeList list=node.getChildNodes();//得到一个结点下的所有子结点,包括空格 for(int i=0;i<list.getLength();i++){ listAll(list.item(i));//递归遍历 } } }
XML文档
<?xml version="1.0" encoding="UTF-8"?> <country> <province id="四川"> <!--省份--> <city>成都</city> <city>广安</city> <city>南充</city> </province> <province id="云南"> <city>楚雄</city> <city>昆明</city> <city>大理</city> </province> <province id="浙江"> <city>杭州</city> <city>宁波</city> </province> </country>
案例练习,用xml文件作为数据库保存学生成绩等信息,然后用DAO的方式进行增删改查
6, sax解析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号