R语言:group_by, summarise, arrange, slice
生成数据:
library(dplyr)
set.seed(1)
df <- expand.grid(list(A = 1:5, B = 1:5, C = 1:5))
df$value <- runif(nrow(df))
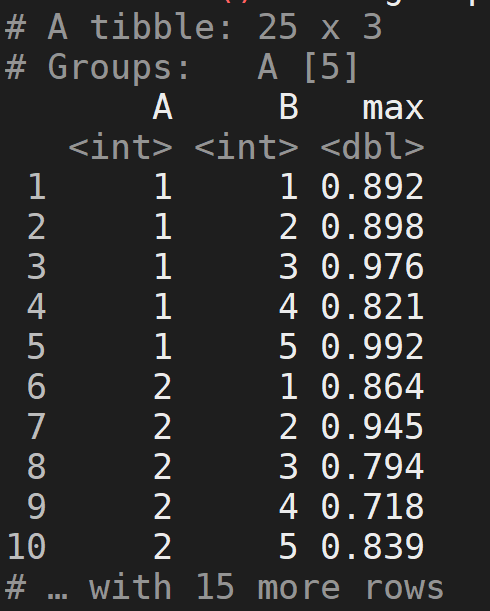
情况 1:group_by + summarise
df %>% group_by(A, B) %>% summarise(max = max(value))
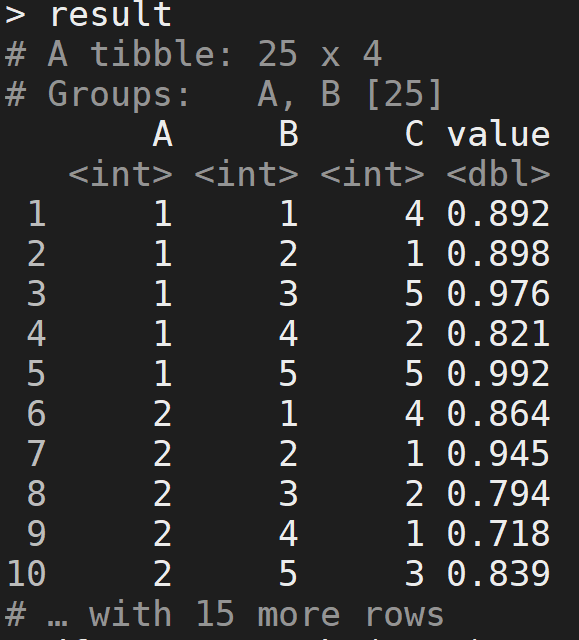
情况 2:group_by + arrange
result <- df %>% group_by(A, B) %>% filter(value == max(value)) %>% arrange(A,B,C)
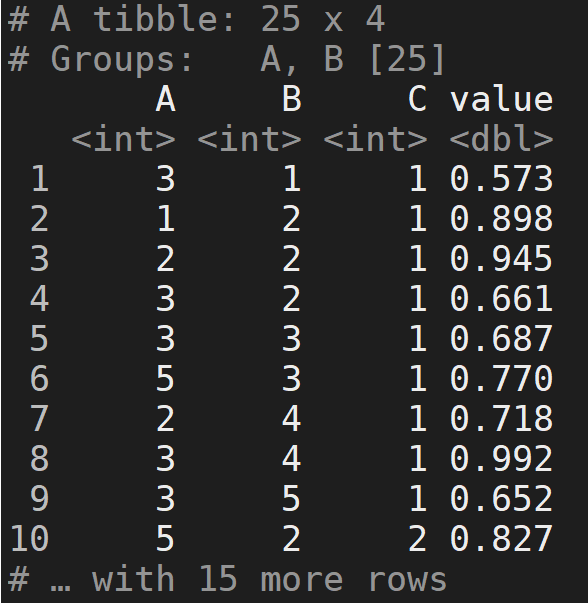
情况 3:group_by + top_n
df %>% group_by(A, B) %>% top_n(n=1)
情况 4:group_by + slice
df %>% group_by(A,B) %>% slice(which.max(value))
本文来自博客园,作者:橙子牛奶糖(陈文燕),转载请注明原文链接:https://www.cnblogs.com/chenwenyan/p/16164272.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号