
Linux:显示特定字符所在的行,并统计特定字符之间的行数差(grep, awk)
举个例子,我想计算>开头的行之间的行数差距,如下截图,>开头的行分别在第1、8、18、25、32行。因此,第1、8、18、25、32行之间的行数差为7、10、7、7。
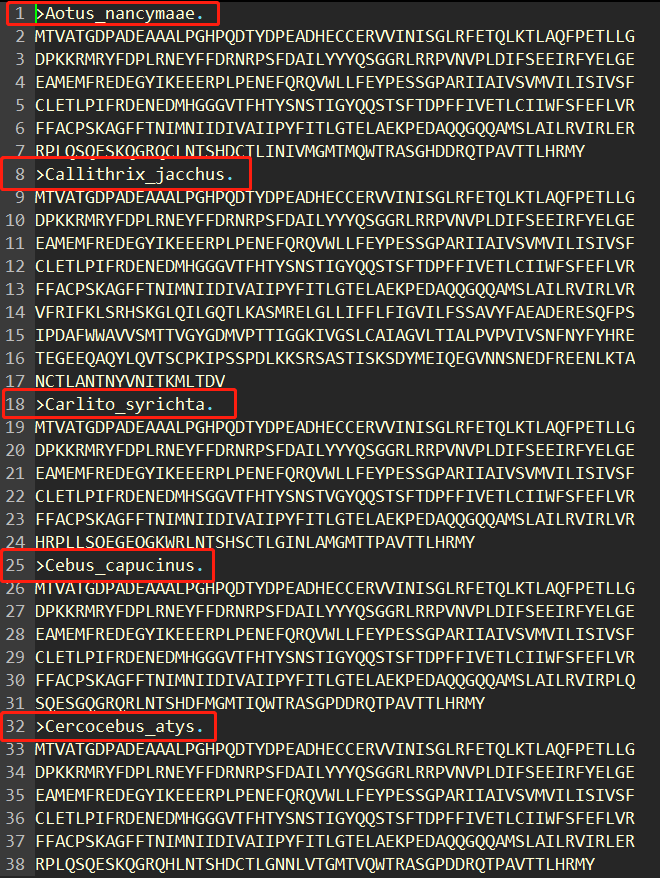
使用如下命令即可完成:
grep -n ">" file | awk 'NR==1{tmp=$1;print $1}NR>1{print $1-tmp;tmp=$1}'
其中,file指的是截图的文件;
grep -n ">" 指的是显示包含>字符的行数N;
awk 后面的命令指的是计算N-(N-1),即我们所需的行数差;
结果如下所示:

如果是多个文件的话(以fa结尾),可以考虑来个循环:
for i in *.fa; do
echo $i
grep -n ">" $i | awk 'NR==1{tmp=$1;print "'$i'"}NR>1{print $1-tmp;tmp=$1}' >> test
done
效果如下:

本文来自博客园,作者:橙子牛奶糖(陈文燕),转载请注明原文链接:https://www.cnblogs.com/chenwenyan/p/14298509.html

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步