Redis(一):redis基本数据类型与底层存储结构
最近在整理有关redis的相关知识,对于redis的基本数据类型以及其底层的存储结构简要的进行汇总和备注(主要为面试用😂)
Redis对外提供的基本数据类型主要为五类,分别是
- STRING:可以存储字符串、数字
- LIST:列表,链表的每个节点存储一个字符串对象
- HASH:包含键值对的无需散列表
- SET:无序集合,集合中包含的是不重复的集合对象
- ZSET:有序集合,是有一对一对字符串成员-浮点数分值所构成的有序映射,排序规则由分值大小所决定
以上是我们在使用Redis的时候经常见到的五种数数据结构,这五种数据结构在底层存储上又有着千丝万缕的联系;例如字符串对象作为一个最基本的存储对象,其在上午五种数据结构中均有应用,那么具体在Redis底层数据结构中是如何构造这五种数据结构的,本文将对底层存储做深入解析。
文章中所描述的数据结构大都基于2.9版本,如有描述不对还请留言指正,万分感谢🍻
一、STRING
字符串对象根据保存值的类型、长度不同,可以分为三种存储结构
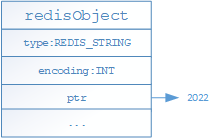
- 如果存储的是整数值(可以用long表示),则底层通过如下结构进行存储,其中type代表当前对象为STRING对象,encoding表示当前对象的编码格式,ptr的属性保存是真实的值;
举例: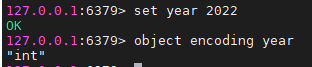
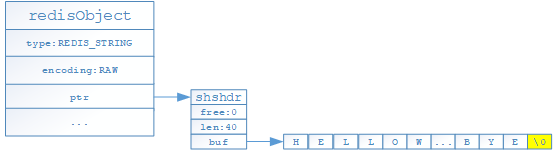
- 如果存储的是字符串且字符串长度超过39字节,则底层通过如下结构进行存储,其中type代表当前对象为STRING对象,encoding表示当前对象的编码格式,ptr为指针指向一个SDS(shshdr:简单动态字符串对象)来保存具体的值;
举例:
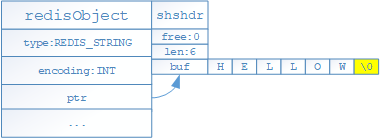
- 如果存储的是字符串且字符串长度未超过39字节,则底层通过如下结构进行存储(需要一块连续的内存空间),其中type代表当前对象为STRING对象,encoding表示当前对象的编码格式,ptr为指针指向一个SDS(shshdr:简单动态字符串对象)来保存具体的值;
举例:
- 存储结构差异
- embstr需要一块连续的内存空间,因此其效率上比raw方式要高
- emstr在内存分配以及内存释放时只需要一次接口,而raw方式需要两次(因为存在redisObject和shshdr两个对象)
- embstr为只读对象,任何对embstr编码对象的修改都会导致对象的编码格式变为raw
- int/embstr编码格式的字符串对象在满足一定条件后会自动转为raw编码格式
- 字符串对象常用的命令
| 命令 | 作用 | 备注 |
| set | 设置key的值 | 根据值不同底层会采用三种不同的编码进行存储 |
| get | 获取字符串对象值 | 对于int编码格式有个值拷贝-转换的过程 |
| append | 在现有字符串值后面追加新的值 | int/embstr编码格式对象会先转换为raw后在执行追加操作 |
| incrbyfloat | 对浮点型数值进行加法操作 | |
| incrby | 对整数型数值进行加法操作 | embstr/raw不能执行此命令 |
| decrby | 对整数型数值进行减法操作 | embstr/raw不能执行此命令 |
| strlen | 返回字符串长度 | int编码格式需要拷贝对象并转换为raw格式后在执行操作 |
| setrange | 在字符串指定索引上的值设置为给定值 | int/embstr需要转换为raw后在执行操作 |
| getrange | 返回字符串指定索引的值 | int编码格式需要拷贝对象并转换为raw格式后在执行操作 |
二、LIST
列表对象根据存储数据的长度以及存储数据元素个数的不同,可以分为两种存储结构:
- 如果列表对象保存的所有字符串对象值的长度均未超过64字节且列表对象保存元素数量小于512个的时候,就采用ziplist(压缩列表)格式存储
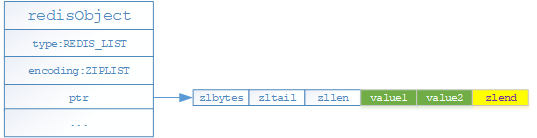
- 如果列表对象保存的所有字符串对象值的长度有超过64字节或者列表对象保存元素数量大于等于512个的时候,就采用linkedlist(双端链表)格式存储
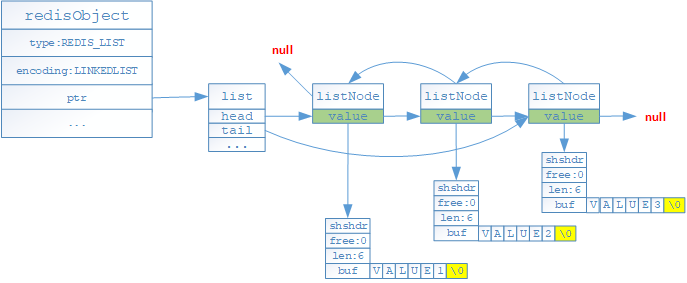
- 存储结构差异
- 压缩列表是有一系列特殊编码的连续内存块组成的顺序型数据结构,而双端链表则不需要连续的内存块
- 压缩列表的每个节点是由三部分组成(previous_entry_length/encoding/content),其中previous_entry_length是记录前一个节点的长度,以便程序可以通过任意节点的指针计算出前一个节点的起始位置;而双端链表则必须通过头尾节点进行遍历获取
- 由于previous_entry_length属性会随着前一个节点的字节长度不同而存储1或者5字节,如果新增的头结点长度大于254字节,会导致当前头结点的previous_entry_length(假设当前节点的previous_entry_length为1)的长度无法保存新节点的长度,此时程序会对原头节点进行内存空间重新分配,最坏的情况是新增的头结点导致原列表中的所有元素全部重新分配;而双端链表则不会存在该问题;因此在使用列表对象时要考虑连锁更新的问题;
三、HASH
哈希对象根据存储键值对数据长度以及键值对数量,可以分为两种存储结构:
- 如果hash对象保存的所有键值对的字符串长度小于64直接且键值对数量小于512个,采用ziplist(压缩列表)编码存储

key-value总是以成对的方式存在,存储顺序类似于栈,先添加的键值对会存在列表的前面,后添加的会在列表的尾部;
- 如果hash对象保存的键值对的字符串长度有超过64字节或者键值对数量大于等于512个,将采用hashtable编码存储
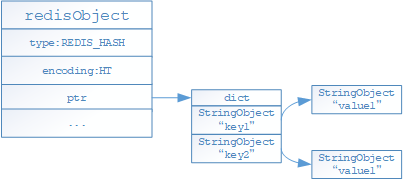
- 上述存储格式会随着存储的内容变化进行编码格式转变,转变只能从ziplist转换为hashtable
四、SET
集合对象根据存储数据的长度以及存储数据元素类型的不同,可以分为两种存储结构:
- 如果列表对象保存的所有元素均是整数型且保存元素数量不超过512个的时候,就采用intset编码存储
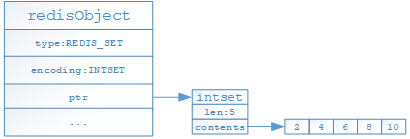
- 如果列表对象保存的元素有不是整数型或者保存元素数量超过512个的时候,就采用hashtable编码存储
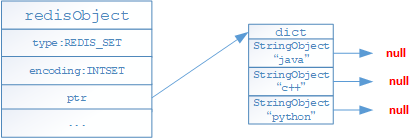
- 上述存储格式会随着存储的内容变化进行编码格式转变,转变只能从intset转换为hashtable
- 在实际使用过程中,需要提前规划好存储数据内容,尽量不要出现编码格式转换
五、ZSET
有序集合对象根据数据元素数量以元素成员长度,可以分为两种存储结构:
- 如果有序集合对象保存的元素数量小于128个且有序结合对象保存的元素成员的长度都小于64字节,就采用ziplist(压缩列表)编码存储
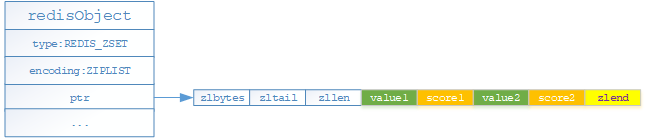
使用压缩列表的有序结合中每个对象由两个节点构成,第一个节点保存元素的具体值,第二个节点保存元素的分值;默认情况元素是按照分值从小到大排序;
- 如果有序集合对象保存的元素数量>=128个或有序结合对象保存的元素成员的长度存在>=64字节,就采用skplist(跳跃表【详细请参见:算法-跳跃表原理与实现】)和dict编码存储
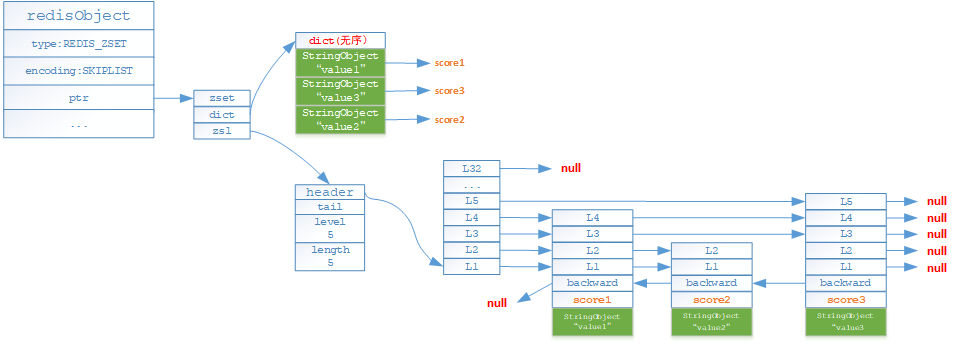
为了兼顾查找与范围查找,有序集合需要同时使用跳跃表与字典
- 字典可以保证O(1)复杂度直接根据指定key查找成员值
- 跳跃表可以在O(logN)的复杂度下完成范围查找,远远优于字典的O(NlogN)
在底层存储上,针对相同的数据对象以及分值,跳跃表与字典会通过指针进行共享,因此不会产生较多的内存浪费
六、总结
Redis对外提供的是上述五种数据类型,但是在底层构造这五种数据类型时,底层实际上使用了包括“简单动态字符串”、“链表”、“字典”、“跳跃表”、“整数集合”、“压缩列表”来构造
根据存储数据的类型、长度以及数量,不同存储格式之间可以进行动态转换,有的存储结构体现是查询速度,有的存储接口体现的空间占用
STRING |
INT |
| embstr | |
| raw | |
| LIST | ziplist |
| linkedlist | |
| HASH | ziplist |
| ht | |
| SET | intset |
| ht | |
| ZSET | ziplist |
| skiplist |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号