
Dubbo负载均衡设计解读
-
前言
今天来研究一下负载均衡的具体实现,LB(Load Balance)是计算机应用中实现集群化的一种技术,因为在网络基础协议中定义了,一台物理机或者一个实例化容器,存在于服务中必须有一个IP,而在当下网络服务中,专职于某个业务的服务可能是一个集群,这个集群在内网中存在多个IP,集群的意义主要在于提高系统的可用性和线性扩展,因此我们真正提供服务可能是通过某个域名,这个域名做了反向代理“平均”地讲流量分散到集群中的某一台机子上,而这个“平均”的意义,就是在于负载均衡算法的设计上了。
负载均衡算法,一是解决流量平均分配的问题,二是解决集群节点新增或者删除时候的容错性。
-
Dubbo RPC负载均衡
RPC(Remote Procedure Call),这种技术诞生是为了分布式服务能够更好的运行,集群化的服务在内部划分领域的时候,通常有个注册中心标注其集群地址列表,而调用方在调用某项服务的时候,注册中心或者路由表提供的是一系列的可调用地址,而决定去调用哪一台服务,就出现了LB的身影。
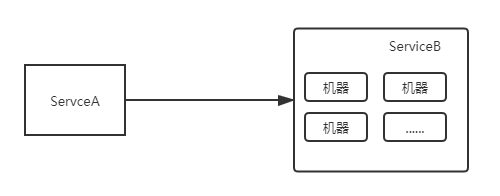
dubbo是一个阿里开源的分布式框架,继承了很多分布式系统需要的功能,LB就存在于rpc包下的cluster中。它定义了一个LoadBalance的接口,有四种实现:轮询、加权轮询、最小活跃度、一致性哈希
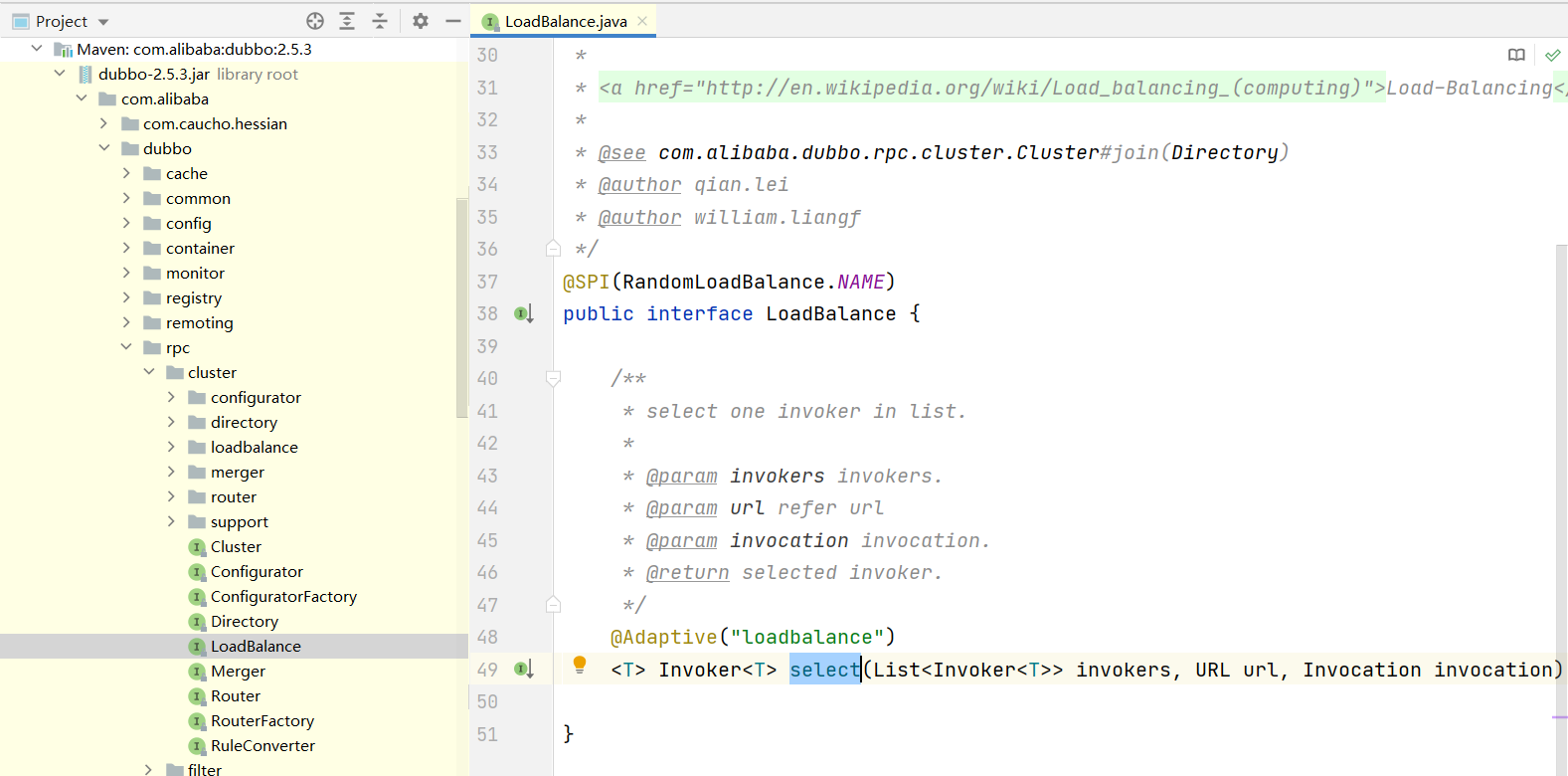
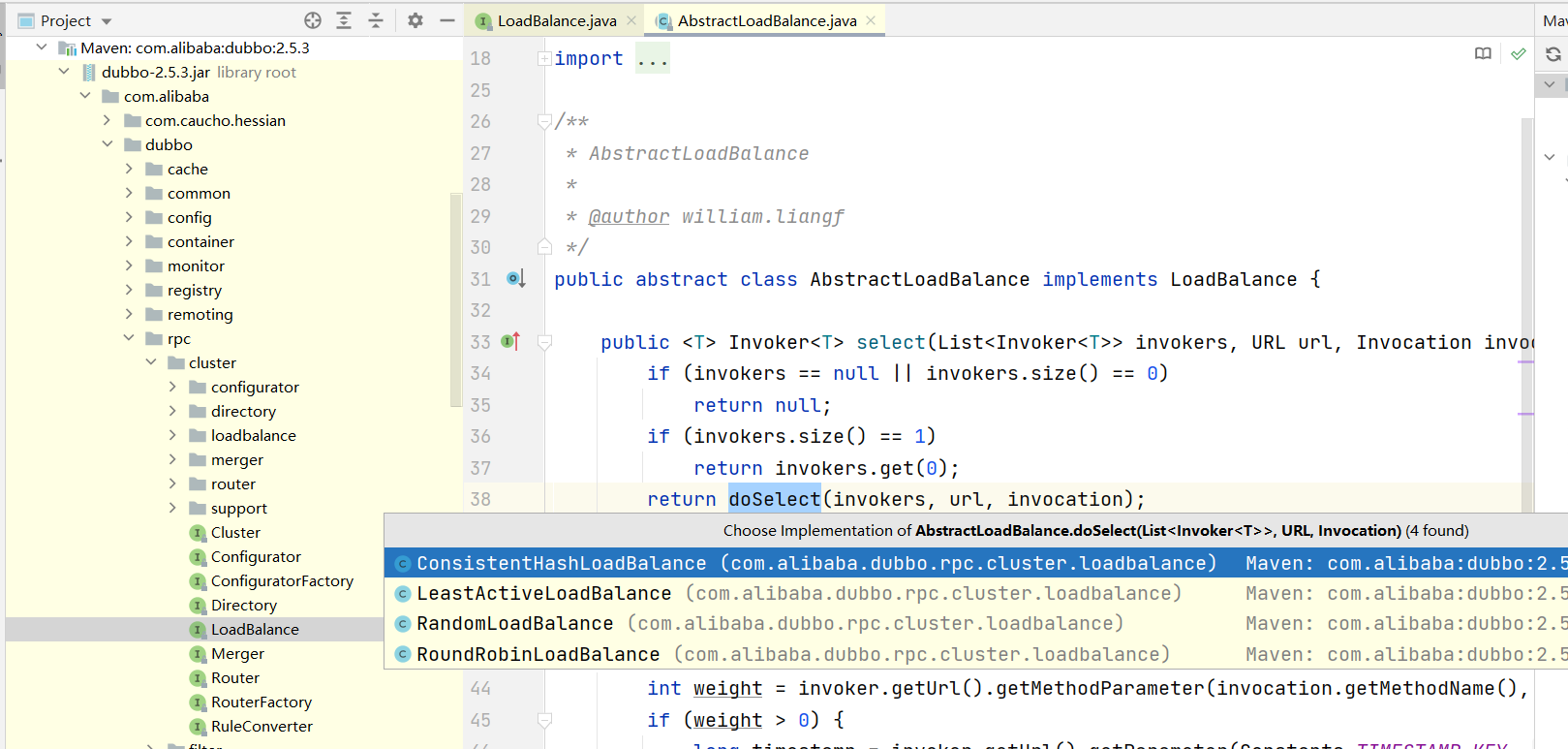
方法名叫select,入参Invokers就是上文提到的路由表,RPC有许多实现,在protocol中有定义,正常我们使用的是http形式的调用,轻便快捷,也是feign的实现。这个方法的写法,和spring的风格有点类似,就是诸如xxmethod,而真正的逻辑写在doxxmethod中。
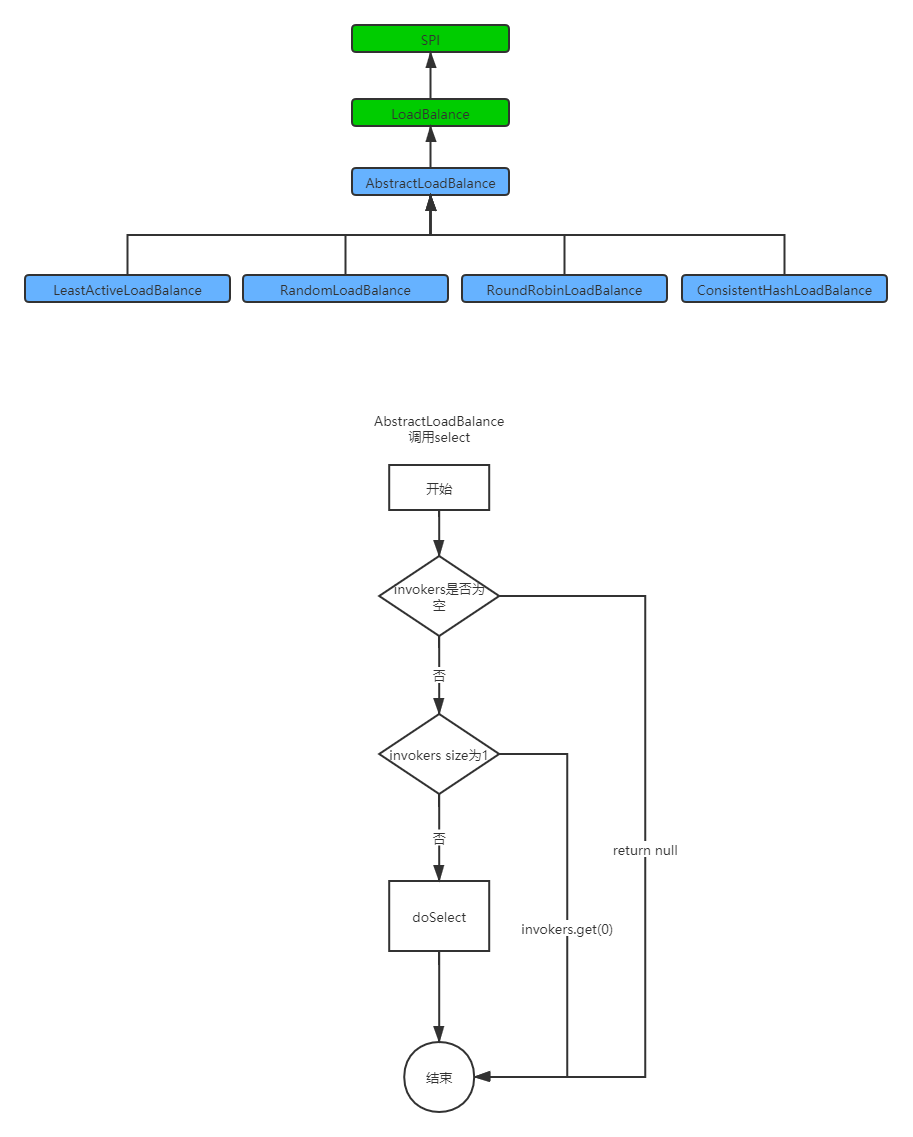
-
源码解析
1.RandomLoadBalance 加权随机负载均衡
“我有一盒红球,我想随机抽取一个”,这个过程是最容易想到的LB算法,什么也不想,生成一个随机数,然后再对长度取模,可以轻松的实现一个随机获取的算法。但是dubbo基于这个算法进行了改造,让每一个“球”带有权重的属性,所以称为加权随机算法。
在权重一样的情况下,就如随机抽取一般,但是我们可以调节让某些机器承担更大的流量,这个时候加权轮询就非常灵活了。
@Override protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) { int length = invokers.size(); // Number of invokers int totalWeight = 0; // The sum of weights boolean sameWeight = true; // Every invoker has the same weight? for (int i = 0; i < length; i++) { int weight = getWeight(invokers.get(i), invocation); totalWeight += weight; // Sum if (sameWeight && i > 0 && weight != getWeight(invokers.get(i - 1), invocation)) { sameWeight = false; } } if (totalWeight > 0 && !sameWeight) { // If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight. int offset = random.nextInt(totalWeight); // Return a invoker based on the random value. for (int i = 0; i < length; i++) { offset -= getWeight(invokers.get(i), invocation); if (offset < 0) { return invokers.get(i); } } } // If all invokers have the same weight value or totalWeight=0, return evenly. return invokers.get(random.nextInt(length)); }
代码很简单,计算总权重,然后随机数生成,之后一个个减掉权重,直到随机数小于零,就决定是落在哪个节点上。
2.LeastActiveLoadBalance 最小活跃度负载均衡
我们可以试想一下,如果随机算法生成的随机数非常集中在某些区间(因为计算机的随机数存在伪随机序列),那么我们是不是可以换一种思路,让最闲的机器跑到前头来接客?在客户端中,有一个类专门记录这写调用的数据com.alibaba.dubbo.rpc.RpcStatus,可以记录正在活跃中的调用(某些耗时操作),一旦发现某个节点活跃太高,它就是将节点后排,优先选用比较闲的节点,这样也是在系统层面考虑的比较全面的负载均衡算法,相当于考虑了系统的吞吐量。
@Override protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) { int length = invokers.size(); // Number of invokers int leastActive = -1; // The least active value of all invokers int leastCount = 0; // The number of invokers having the same least active value (leastActive) int[] leastIndexs = new int[length]; // The index of invokers having the same least active value (leastActive) int totalWeight = 0; // The sum of with warmup weights int firstWeight = 0; // Initial value, used for comparision boolean sameWeight = true; // Every invoker has the same weight value? for (int i = 0; i < length; i++) { Invoker<T> invoker = invokers.get(i); int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive(); // Active number int afterWarmup = getWeight(invoker, invocation); // Weight if (leastActive == -1 || active < leastActive) { // Restart, when find a invoker having smaller least active value. leastActive = active; // Record the current least active value leastCount = 1; // Reset leastCount, count again based on current leastCount leastIndexs[0] = i; // Reset totalWeight = afterWarmup; // Reset firstWeight = afterWarmup; // Record the weight the first invoker sameWeight = true; // Reset, every invoker has the same weight value? } else if (active == leastActive) { // If current invoker's active value equals with leaseActive, then accumulating. leastIndexs[leastCount++] = i; // Record index number of this invoker totalWeight += afterWarmup; // Add this invoker's weight to totalWeight. // If every invoker has the same weight? if (sameWeight && i > 0 && afterWarmup != firstWeight) { sameWeight = false; } } } // assert(leastCount > 0) if (leastCount == 1) { // If we got exactly one invoker having the least active value, return this invoker directly. return invokers.get(leastIndexs[0]); } if (!sameWeight && totalWeight > 0) { // If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight. int offsetWeight = random.nextInt(totalWeight) + 1; // Return a invoker based on the random value. for (int i = 0; i < leastCount; i++) { int leastIndex = leastIndexs[i]; offsetWeight -= getWeight(invokers.get(leastIndex), invocation); if (offsetWeight <= 0) return invokers.get(leastIndex); } } // If all invokers have the same weight value or totalWeight=0, return evenly. return invokers.get(leastIndexs[random.nextInt(leastCount)]); }
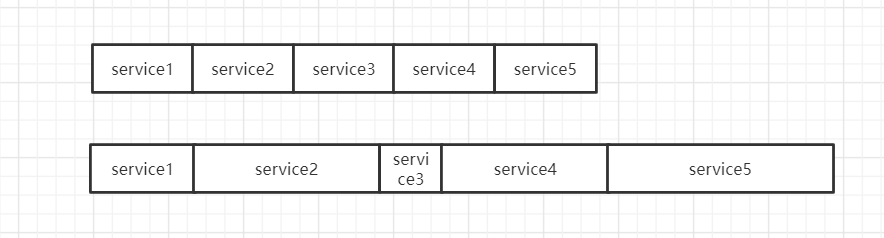
3.RoundRobinLoadBalance 加权轮询算法
既然要实现平均,那么我们挨个来一遍吧。轮询可以实现真正的雨露均沾,加权轮询,意味着某些机器可以占更多的流量,是一种更灵活的负载均衡算法。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) { String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName(); int length = invokers.size(); // 总个数 int maxWeight = 0; // 最大权重 int minWeight = Integer.MAX_VALUE; // 最小权重 for (int i = 0; i < length; i++) { int weight = getWeight(invokers.get(i), invocation); maxWeight = Math.max(maxWeight, weight); // 累计最大权重 minWeight = Math.min(minWeight, weight); // 累计最小权重 } if (maxWeight > 0 && minWeight < maxWeight) { // 权重不一样 AtomicPositiveInteger weightSequence = weightSequences.get(key); if (weightSequence == null) { weightSequences.putIfAbsent(key, new AtomicPositiveInteger()); weightSequence = weightSequences.get(key); } int currentWeight = weightSequence.getAndIncrement() % maxWeight; List<Invoker<T>> weightInvokers = new ArrayList<Invoker<T>>(); for (Invoker<T> invoker : invokers) { // 筛选权重大于当前权重基数的Invoker if (getWeight(invoker, invocation) > currentWeight) { weightInvokers.add(invoker); } } int weightLength = weightInvokers.size(); if (weightLength == 1) { return weightInvokers.get(0); } else if (weightLength > 1) { invokers = weightInvokers; length = invokers.size(); } } AtomicPositiveInteger sequence = sequences.get(key); if (sequence == null) { sequences.putIfAbsent(key, new AtomicPositiveInteger()); sequence = sequences.get(key); } // 取模轮循 return invokers.get(sequence.getAndIncrement() % length); }
weightSequence是一个本地的map,存有方法级的缓存,value是一个原子Int,每次都是递增的,通过取模映射到权重区间从而决定是调用哪一台机子。
4.ConsistentHashLoadBalance 一致性哈希负载均衡
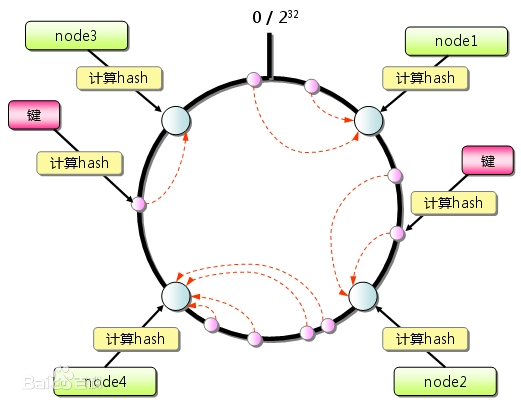
哈希算法的原理,是指相同的入参,可以计算出固定的一个哈希值,这个算法极大地提升了计算机分布式系统的效率,有诸多场景应用。而使用普通的哈希算法来设计lb,最大的弊端是rehash的过程产生的副作用。以HashMap为例,当集合中添加过多的节点的时候,节点冲突的概率就会变高,这时候需要扩充计算集合的上界,如果是数据结构的扩充场景还算简单,加入是服务器rehash,还涉及到一些数据迁移的问题,这种时候就变得非常麻烦了。一致性hash,就是指计算出来的哈希值,通过区间的方式定义节点,比如[0,10000]内都是一个节点管理,类似redis的slot,为了更好的健壮性,还可以采用虚拟节点。
@Override protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) { String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName(); int identityHashCode = System.identityHashCode(invokers); ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key); if (selector == null || selector.getIdentityHashCode() != identityHashCode) { selectors.put(key, new ConsistentHashSelector<T>(invokers, invocation.getMethodName(), identityHashCode)); selector = (ConsistentHashSelector<T>) selectors.get(key); } return selector.select(invocation); }
public ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) { this.virtualInvokers = new TreeMap<Long, Invoker<T>>(); this.identityHashCode = System.identityHashCode(invokers); URL url = invokers.get(0).getUrl();
// 默认160个节点 this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160); String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0")); argumentIndex = new int[index.length]; for (int i = 0; i < index.length; i ++) { argumentIndex[i] = Integer.parseInt(index[i]); }
// 构造哈希节点 for (Invoker<T> invoker : invokers) {
// 这里我理解是构造了虚拟节点,一个invoker默认映射40个,就是url+i作为md5的入参 for (int i = 0; i < replicaNumber / 4; i++) { byte[] digest = md5(invoker.getUrl().toFullString() + i);
// 再对同一个url+i md5后的结果取哈希,依然是构造4个虚拟节点 for (int h = 0; h < 4; h++) { long m = hash(digest, h); virtualInvokers.put(m, invoker); } } } }
-
结尾
本次总结了四种LB算法,只能是粗浅的学习,真正有价值的是应用经验,什么场景下应用什么样的策略,主要的目的是一个,让分布式系统效率提升并且降低有可能的风险。应用经验和系统原理之间紧密结合,我们需要在真正应用场景下多思考,多实验,才能达到知行合一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号