

Python技术点
调试过程中遇到的问题,继上一篇博文!
(1)爬取第一个页面之后名字链接页面存在分页情况
解决方案:根据子网页,选择合适的正则表达式,获取页面数,根据页面数自动生成换页URL


(2)测试过程中某些网页数据存在编码问题。
解决方案:在获取信息时,使用pandas保存数据,它提供编码兼容

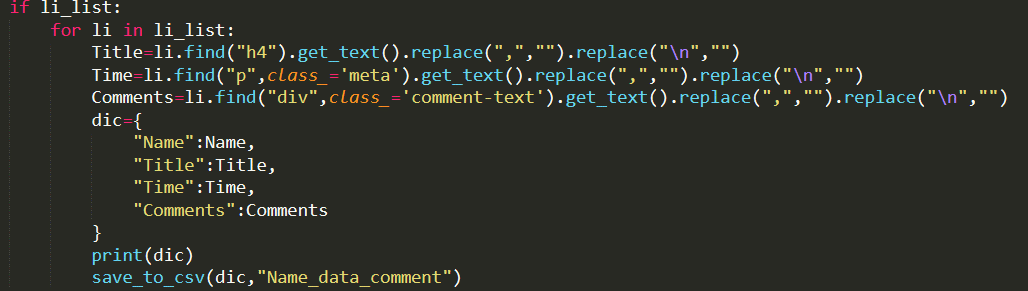
(3)测试过程中存在某些英文名没有用户评论
解决方案:在获取用户评论模块Comment时,设置判断Comment模块中的内容是否为空,不为空时,则进一步解析模块的具体内容,并保存数据。为空,则跳过。
(4)测试过程中存在访问次数过多和网络异常情况
解决方案:在发起网页请求时,设置异常捕获,请求时间超时,则退出循环,进行新一次网页请求,设置headers,仿造用户ID对网页进行请求。

关于转换伪ID,进行对网页的访问:
浏览器中打开页面,以edge为例,点击“查看源”或F12

第一步:点击上图中“网络”标签,然后刷新或载入页面
第二步:在右侧“标头”下方的“请求标头”中的所有信息都是headers内容,添加到requests请求中即可
代码如下:
headers = {'Accept': 'text/html, application/xhtml+xml, image/jxr, */*',
'Accept - Encoding':'gzip, deflate',
'Accept-Language':'zh-Hans-CN, zh-Hans; q=0.5',
'Connection':'Keep-Alive',
'Host':'zhannei.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
r = requests.get('http://zhannei.baidu.com/cse/search', params=keyword, headers=headers, timeout=3)

