int8量化过程中涉及到的原理
int8 量化是一种用于减少模型大小和计算复杂度的方法,特别是在深度学习模型中。它通过将浮点数(通常是 fp32)转换为 8 位整数 (int8),从而减少内存使用和提高计算效率。这在嵌入式设备和移动设备上特别有用。下面是 int8 量化的基本原理及其涉及的过程。
1. 为什么需要量化?
- 减少模型大小:浮点数(
fp32)使用 32 位,而整数(int8)仅使用 8 位,因此模型的权重和激活值在存储时所需的空间大大减少。 - 提高计算效率:整数运算通常比浮点运算快,特别是在一些硬件上,例如嵌入式设备中的 DSP 或专门的 AI 加速器。
2. 量化的基本原理
量化的核心是将浮点数映射到整数。常见的方法是线性量化,其中使用以下公式进行映射:
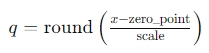
其中:
- ( q ) 是量化后的整数值。
- ( x ) 是原始的浮点值。
- scale 是一个比例因子,用于将浮点范围映射到整数范围。
- zero_point是一个零点偏移,用于对齐零值。
3. 量化过程
量化通常包括以下几个步骤:
a. 计算 scale 和 zero_point

b. 将浮点数转换为整数

c. 反量化(用于推理)
为了在推理过程中使用量化后的整数,需要将其转换回浮点数:

4. 量化后的推理
在量化后的推理过程中,卷积操作和矩阵乘法等基本操作可以直接在 int8 空间中进行,大大提高了计算效率。量化推理的流程如下:
- 输入数据量化:将输入的浮点数数据量化为
int8。 - 模型计算:在
int8范围内进行计算。 - 输出反量化:将计算结果反量化为浮点数进行输出。
5. 量化感知训练 (QAT)
为了减少量化带来的精度损失,可以使用量化感知训练 (Quantization-Aware Training, QAT)。在训练过程中模拟量化操作,使模型在训练时适应量化的影响,从而在推理时获得更好的性能。
6. 量化后精度
虽然量化可以显著提高计算效率和减少模型大小,但它可能会带来一些精度损失。选择合适的量化策略和参数可以减小这种损失,例如使用更复杂的量化方法如对称量化或非对称量化,以及对不同层采用不同的量化参数等。
7. 量化工具
常用的深度学习框架(如 TensorFlow、PyTorch)都提供了量化工具和支持,方便用户进行模型量化。例如,TensorFlow 提供了 TensorFlow Lite,用于移动和嵌入式设备的量化模型推理;PyTorch 提供了 torch.quantization 模块用于量化模型。
总之,int8 量化是一种有效的方法,用于在资源受限的设备上部署深度学习模型,同时保持较高的推理速度和节省存储空间。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/18315901,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号