Pycharm图形化性能测试工具Profile
在部署模型的时候遇到一个需要加速的问题,为了搞清楚模型调用过程中最耗时的操作以定位优化,同事告诉了我一个调优的工具,叫
profile。搜集整理如下:
1. PyCharm图形化性能测试工具Profile
PyCharm提供了图像化的性能分析工具,使用方法见利用PyCharm的Profile工具进行Python性能分析。
另外,结合后面其他测试时间的python包以及pycharm打印出的log信息,可以知道,
运行时使用了
cprofile以及其中profiler这两个工具来记录运行时间,显示统计结果的时候使用了pstats这个工具来进行表格化显示。
可知profile工具使用有三个步骤:
A profiler runs in the following order: vmprof, yappi, cProfile.
1. 开启profiling会话
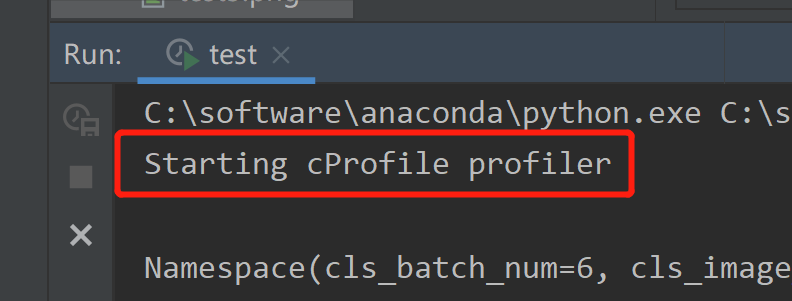
点击菜单栏中Run->Profile 'XXX脚本'或者脚本编辑器页面右击菜单栏中的Profile 'XXX脚本',然后在命令运行面板会出现类似下面的显示。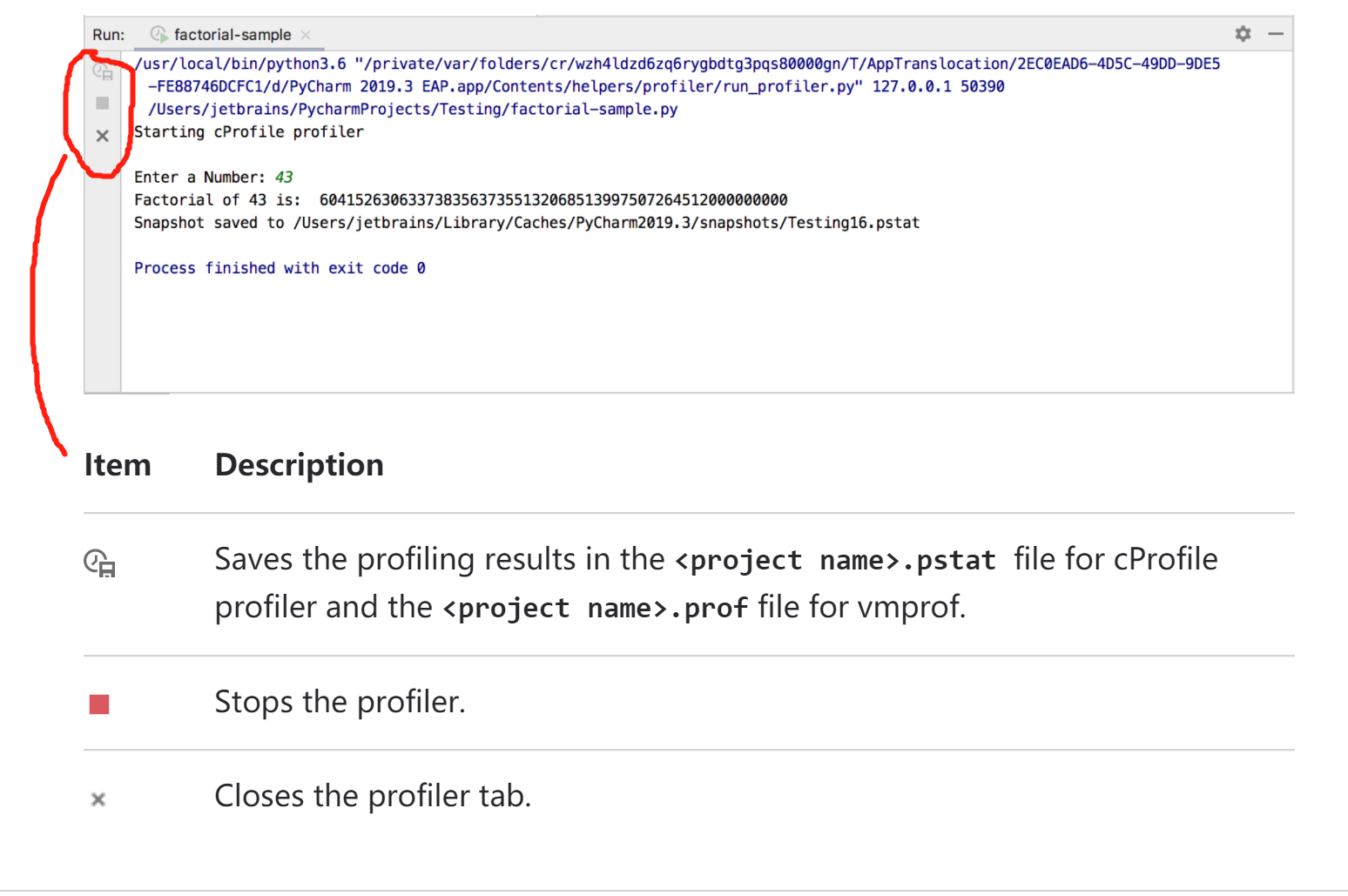
profile工具运行后,下方的输出面板会有三个项目,分别是
- 保存性能分析结果
- 停止分析
- 关闭分析面板
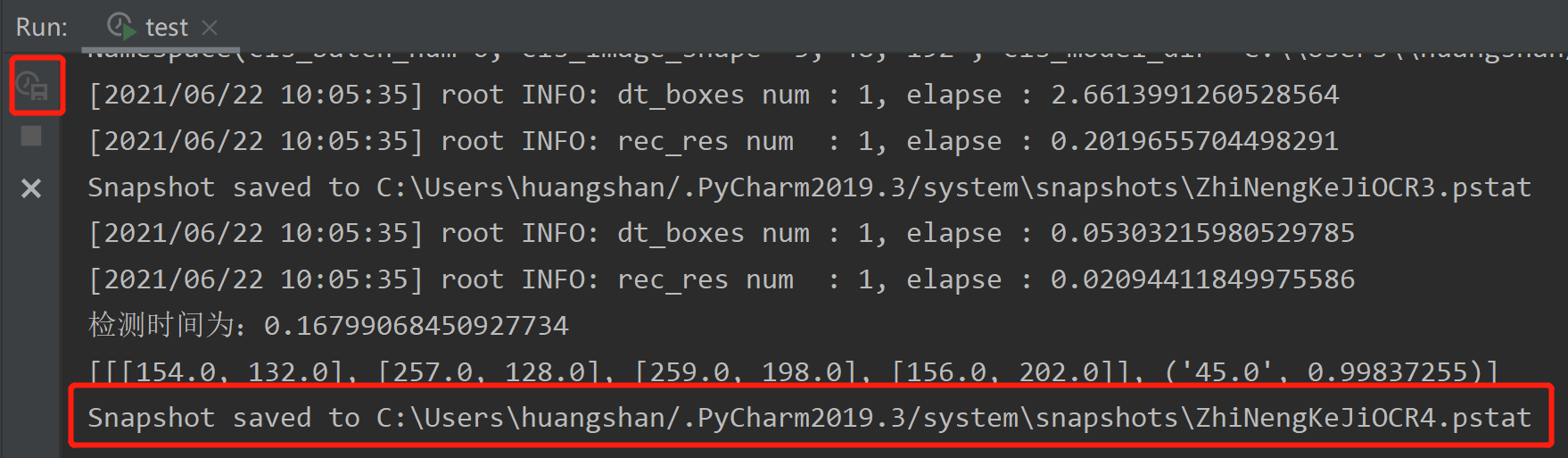
可以看到,点击第一个保存之后,保存的位置提示,对于windows来说默认保存的地方是在:<LOCALAPPDATAPATH>\JetBrains\<product><version>/snapshots,mac自己看,命名是当前项目(project name)的名称。
2. 查看profile结果
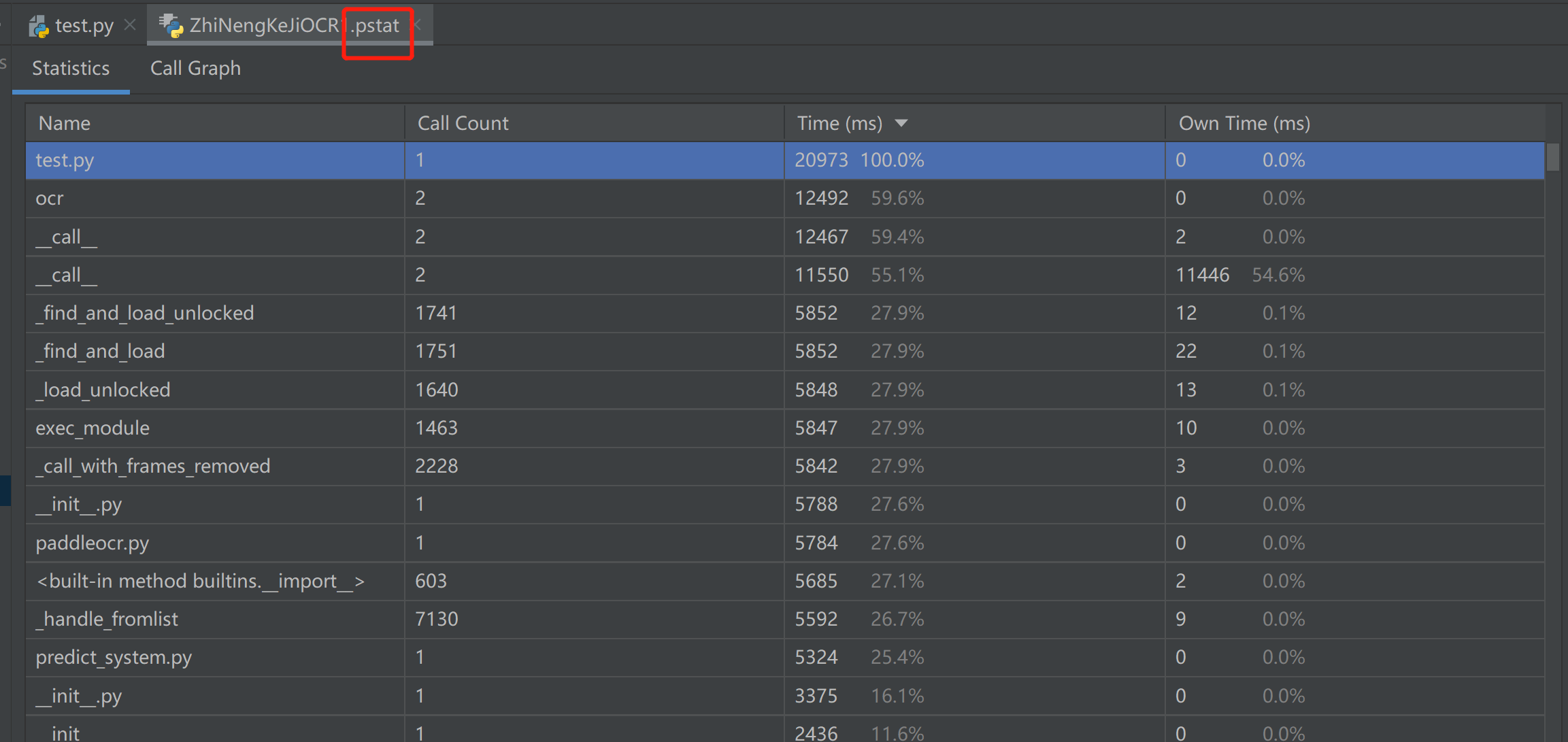
可以看到,使用pycharm的profile可视化工具之后,结果是一个XXX.pstat文件,其中有一部分是Statistics,另一部分是Call Graph。
2.1 Statistics面板
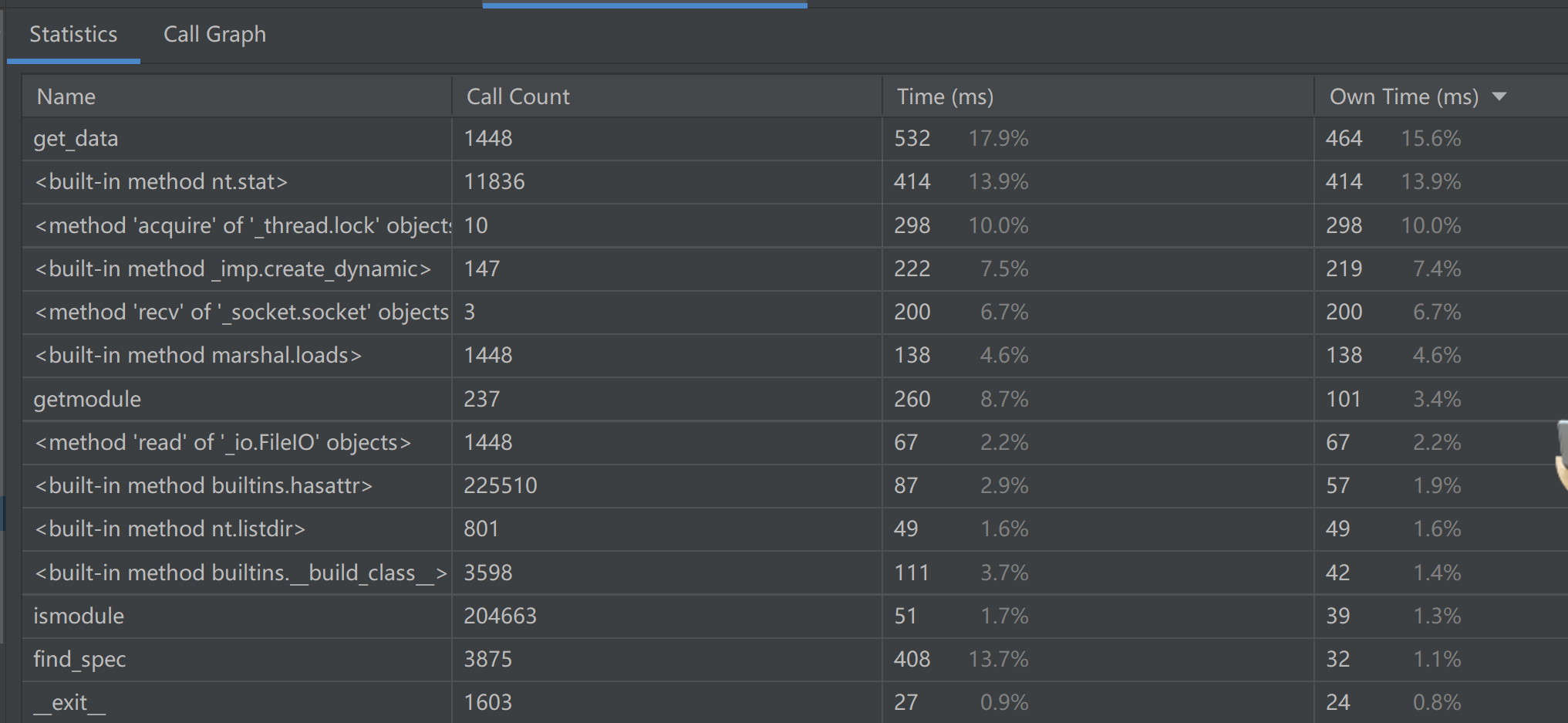
关于统计部分:
| 项目 | 描述 |
|---|---|
| Name | 函数名称 |
| Call Count | 当前函数被调用的次数 |
| Time(ms) | 这个函数及这个函数调用的函数总共花费的时间 |
| Own Time(ms) | 所选函数本身调用的时间 |
小技巧:
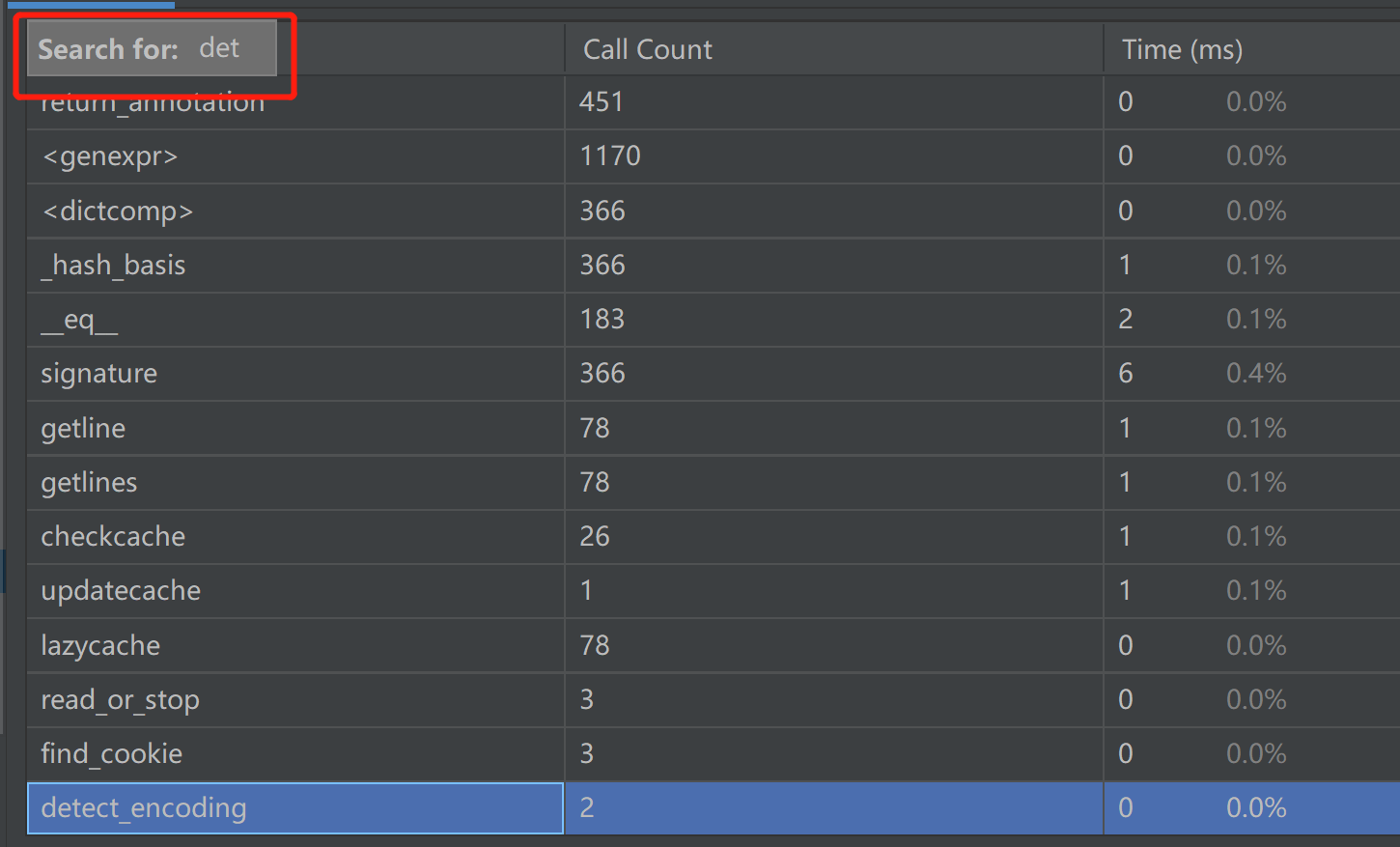
想在统计面板的Name列查找一个特定名称的函数/文件,可以任意点击一个cell,然后输入要搜索的东西。类似下面
另外,还可以右击每一行, Jump to the source code,跳转至源代码。函数对应的源代码就会出现在编辑框。
注意,不是所有的都可以跳转
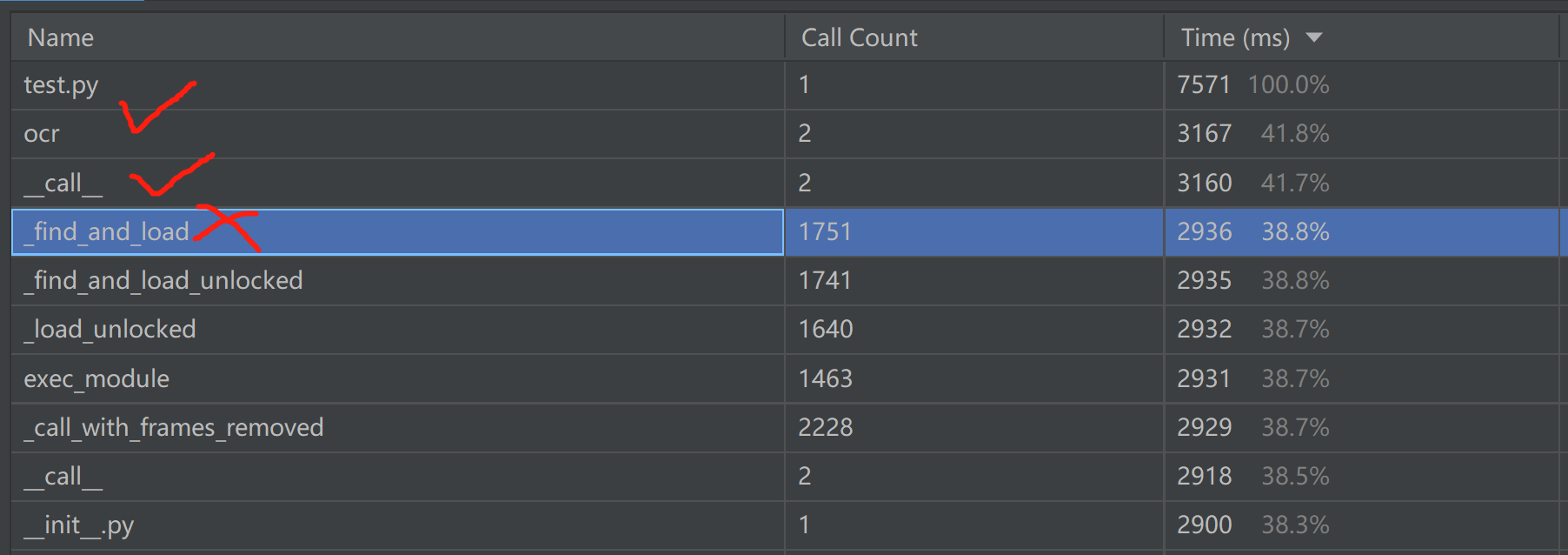
分析的时候,可以先按照Call Count进行耗时从大到小排序,然后理清楚哪个调用了哪个,调用多次的,比如上图中调用1k多次的一般都是系统类型的调用,其他才是我们自己的,从上到下,依次去观察哪个比较耗时。
2.2 Call Graph
可以直接点击Call Graph这个tab,查看所有函数的调用关系图,也可以在Statistics面板,某个函数行右击Show On Call Graph,就可以直接跳转到该函数在Call graph图中对应位置。
如果一开始显示一堆矩形,没事,拖动/放大。
随便点点下面这些按钮,放大就对了
这些按钮的功能为(其他不重要,自己看提示的label也可以理解):
| 项目 | 描述 |
|---|---|
| + / - | 用来放大/减小这个图的,也可以直接按键盘的加号键/减号键(不需要按住shift) |
然后就可以看到函数调用关系图,一般最下面一行是python脚本文件,从下往上看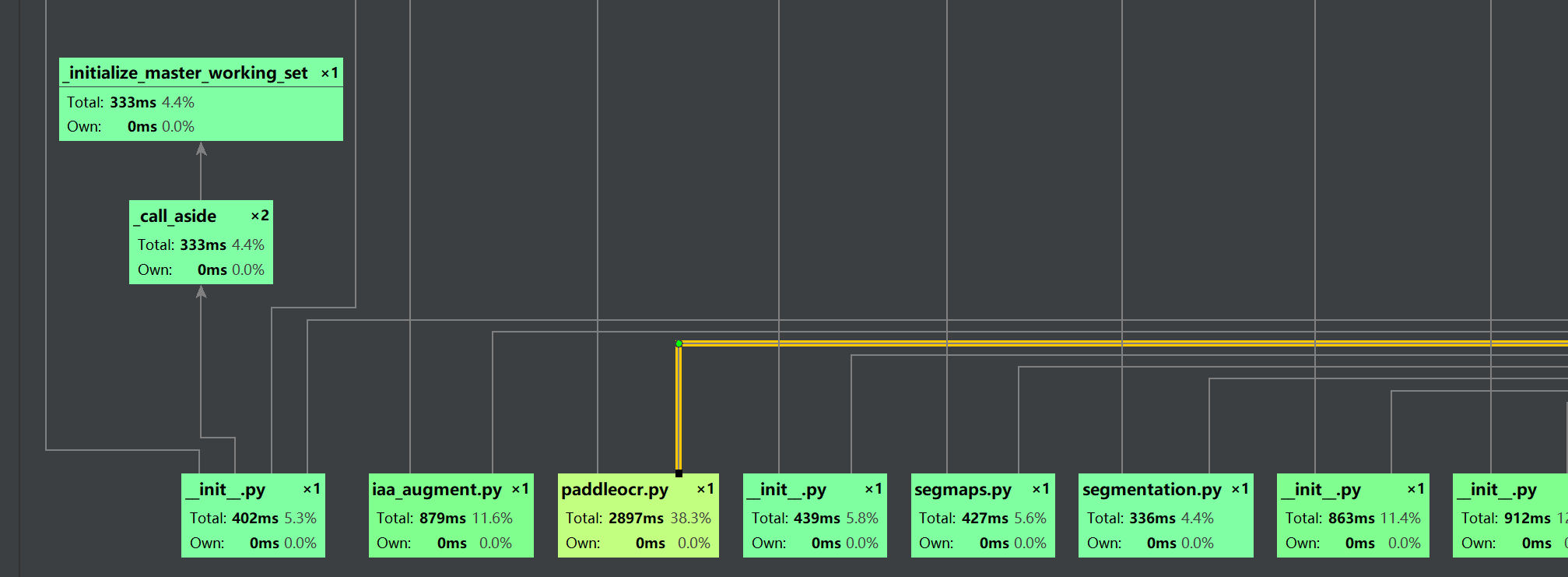
最底层可能会有多个脚本,无所谓,点击线条可以highlight,继续往下点就好了
2. 其他测试时间的python库
主要参考:Python的7种性能测试工具:timeit、profile、cProfile、line_profiler、memory_profiler、PyCharm图形化性能测试工具、objgraph
我这里只列举自己可能会用到的几个及相关注意事项
2.1 itemit
python内置库,不需要额外安装
>>> import timeit
>>> def fun():
for i in range(100000):
a = i * i
>>> timeit.timeit('fun()', 'from __main__ import fun', number=1)
0.02922706632834235
>>>timeit只输出被测试代码的总运行时间,单位为秒,没有详细的统计。
2.2 profile库
python内置库,不需要额外安装。
纯Python实现的性能测试模块,接口和cProfile一样。
用的时候直接把要测试的部分包在一个函数里,使用profile.run("XX()")即可,默认使用标准名称排序
>>> import profile
>>> def fun():
for i in range(100000):
a = i * i
>>> profile.run('fun()')
5 function calls in 0.031 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(AddPath)
1 0.000 0.000 0.000 0.000 :0(Execute)
1 0.000 0.000 0.000 0.000 :0(POINTER)
38 0.000 0.000 0.016 0.000 :0(__build_class__)
1 0.000 0.000 0.000 0.000 :0(__deepcopy__)
14/6 0.000 0.000 0.016 0.003 :0(__import__)
5 0.000 0.000 0.000 0.000 :0(__new__)
4 0.016 0.004 0.016 0.004 :0(_abc_init)
25 0.000 0.000 0.000 0.000 :0(_fix_co_filename)
2 0.000 0.000 0.000 0.000 :0(_getframe)
7 0.000 0.000 0.000 0.000 :0(acquire)
130 0.000 0.000 0.000 0.000 :0(acquire_lock)
18 0.000 0.000 0.000 0.000 :0(add)
52 0.000 0.000 0.000 0.000 :0(allocate_lock)
>>>- ncall:函数运行次数
- tottime: 函数的总的运行时间,减去函数中调用子函数的运行时间
- 第一个percall:percall = tottime / nclall
- cumtime:函数及其所有子函数调整的运行时间,也就是函数开始调用到结束的时间。
- 第二个percall:percall = cumtime / nclall
但是这里排序是按照函数名称排序的,如果希望按照运行时间排序,可以使用
# 查看被调用次数最多的
profile.run('fun()',sort="cumulative")
# 查看耗时最长的
profile.run('fun()',sort="tottime")可以使用的sort参数的取值有:
‘calls’ call count
‘cumulative’ cumulative time
‘cumtime’ cumulative time
‘file’ file name
‘filename’ file name
‘module’ file name
‘ncalls’ call count
‘pcalls’ primitive call count
‘line’ line number
'name’function name
'nfl’name/file/line
'stdname’standard name
'time’internal time
'tottime’internal time
参考:
相对于 timeit 的细粒度,:mod:profile 和 pstats 模块提供了针对更大代码块的时间度量工具。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/18158450,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号