图像预处理的数据精度问题报出的Nan
问题描述:git上的一个官方项目,图像预处理操作,使用torch进行处理,包含Resize,ToTensor,Nomalize,处理后的结果输入到trt-fp16精度的模型中,可以正常输出。我对图像预处理进行了修改,使用opencv进行resize,numpy进行totensor,nomalize操作,处理后的结果输出到trt-fp16的模型中,发现输出结果都是Nan。
问题解决:通过数据对比,发现torch处理的结果数据类型是fp32,而numpy处理的结果是fp64(pytorch对于浮点类型默认为float32,而numpy的默认类型是float64),这就是问题的原因,说明fp64输入到trt-fp16中超过了精度表示,因为只有超出精度表示基本才会出现nan,但是不清楚fp64到fp16这个过程发生了什么样的类型转换
关于上面的问题,我们先来说一说精度的问题:
fp32、fp16、bf16分别称为单精度浮点数、半精度浮点数、半精度浮点数,其中fp16是intel提出的,bf16是nvidia提出的,fp16和bf16所占存储空间是fp32的一半。
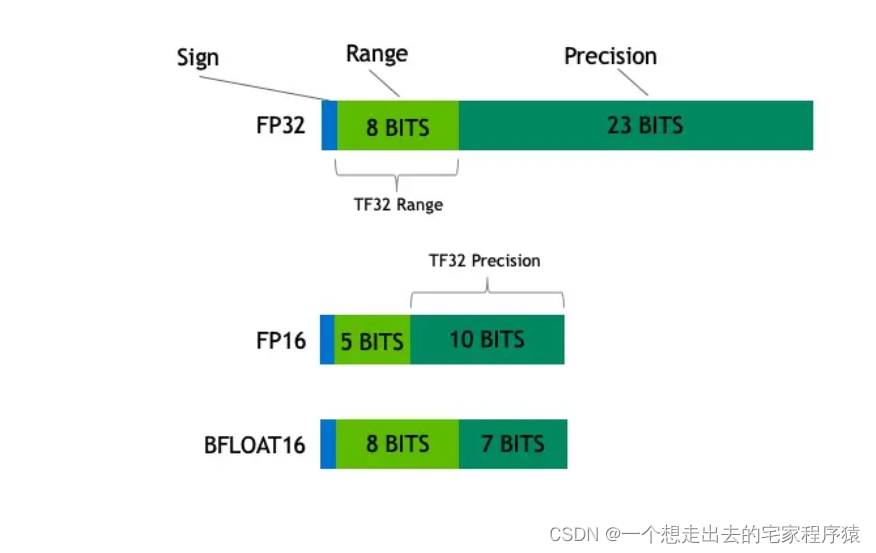
fp16的动态范围是5.96E−8~ 65504,bf16的动态范围是9.2E−41~3.38E38,fp32的动态范围是1.4E-45 ~ 3.40E38,可以看出bf16的数值范围几乎和fp32的范围一样大,这样可以避免fp16容易上、下溢的问题。但是其损失了精度,因为它有8个指数位、尾数位只有7位,而fp16有5个指数位,10个尾数位(也叫小数位)。所以我们常说的超出精度表示范围有两个情况,一种是超出数值范围,一种是超出精度范围,例如超出小数点位数
而fp64称为双精度浮点类型
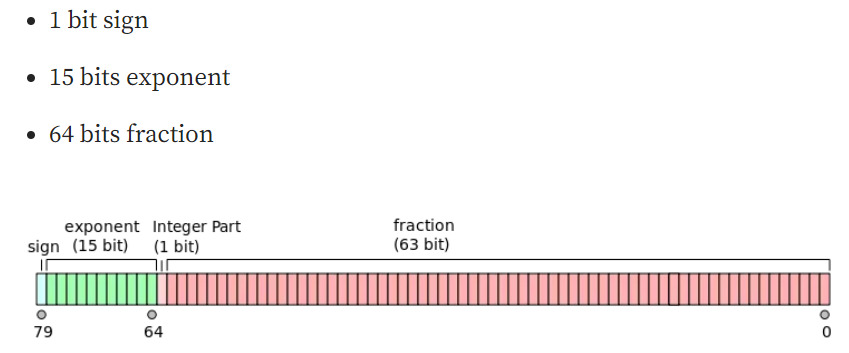
用64位二进制表示,其中1位用于sign,11位用于exponent,52位用于fraction。它的数值范围大约是2.23e-308到1.80e308,精度大约是15到17位有效数字。它通常用于科学计算中对精度要求较高的场合,但在深度学习中不常用,因为它占用的内存和计算资源较多。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/18130458,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号