NLP基础之one-hot编码
one-hot是一种传统NLP的高维、稀疏的表示法,因为首先他的维度是比较大的,其次有很多0表示,所以是比较稀疏的
1 one-hot编码概念
one-hot编码顾名思义,又称为独热编码表示,只有一位有效位,它的方法是使用N位状态寄存器来对这N位个状态进行编码,每个状态都有它独立的寄存位,并且在任意的时候其中只有一位有效,就是用一个很长的向量来表示一个词,向量长度为词典的大小N,每个向量只有一个维度是1,表示该词语在词典的位置,其余维度全部为0。
例如对六个状态进行编码:
自然顺序码为 000,001,010,011,100,101
独热编码则是 000001,000010,000100,001000,010000,100000
国家特征:["中国",“美国”,"日本"](这里N=3,三维数据):
中国=> 100
美国=> 010
日本=> 001
性别特征:["男","女"](这里N=2 二维数据)
男 => 10
女 => 01
2 one-hot编码文本表征
one-hot编码在提取文本表征上属于词袋模型(bag of words)。如何使用one-hot编码抽取文本特征向量我们可以通过具体的语料文本来详细的举个例子,加入我们是的语料库中有三段话:
(1)我爱中国。
(2)爸爸妈妈爱我。
(3)爸爸妈妈爱中国。
第一步需要对语料库进行分词,并且获取其中的所有的词,然后对分完的词进行编号。
1 我;2 爱;3 爸爸;4 妈妈;5 中路;
第二步使用one-hot对每段话提取特征向量;
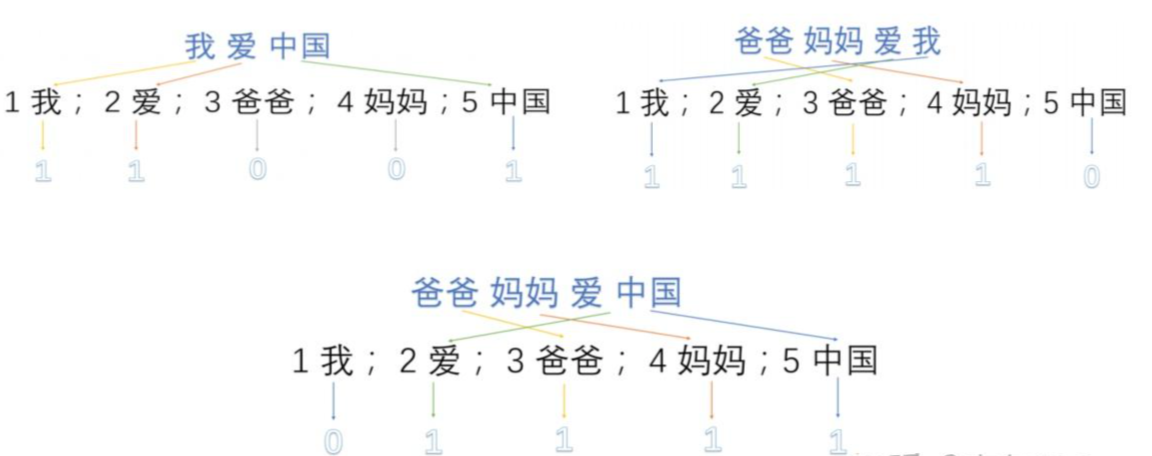
第三步得到最终的特征向量。
我爱中国=>(1,1,0,0,1)
爸爸妈妈爱我=>(1,1,1,1,0)
爸爸妈妈爱中国=>(0,1,1,1,1)
3 one-hot编码优缺点
3.1 优点
(1)解决了分类器不好处理离散数据的问题,能够处理非连续型数值特征。
(2)在一定程度上也起到了扩充特征的作用,比如性别本身是一个特征,经过one-hot编码以后,就变成了男或女两个特征。
3.2 缺点
(1)在文本表征表示上有些缺点非常突出,首先one-hot 编码是一个词袋模型,是不考虑词和词之间的顺序问题,它是假设词和词之间是相互独立的,但是在大部分情况下词和词之间是相互影响的。
(2)one-hot编码得到的特征是离散稀疏的,每个单词的one-hot编码维度是整个词汇表的大小,维度非常巨大,编码稀疏,会使得计算代价变大。
4 手动实现one-hot编码
详细代码如下:
第一步分词:
import jieba
import numpy as np
text_samples = {"我爱中国", "爸爸妈妈爱我", "爸爸妈妈爱中国"}
# 先中文进行分词
tokens_samples = []
for texts in text_samples:
jiebas = jieba.lcut(texts)
tokens_samples.append(jiebas)
print(tokens_samples) # ['爸爸 妈妈 爱 我', '爸爸 妈妈 爱 中国', '我 爱 中国']第二步构建词的索引:
tokens_samples = ['爸爸 妈妈 爱 我', '爸爸 妈妈 爱 中国', '我 爱 中国']
token_index = {} # 索引
for sample in tokens_samples:
for word in sample.split():
if word not in token_index:
token_index[word] = len(token_index) + 1
print(len(token_index)) # 5
print(token_index) # {'爸爸': 1, '妈妈': 2, '爱': 3, '我': 4, '中国': 5}
第三步构建one-hot编码矩阵:
# 构建one-hot编码矩阵
results = np.zeros(shape=(len(tokens_samples), max(token_index.values())+1))
for i, sample in enumerate(tokens_samples):
for _, word in list(enumerate(sample.split())):
index = token_index.get(word)
results[i, index] = 1
print(results)[[0. 1. 1. 1. 1. 0.]
[0. 1. 1. 1. 0. 1.]
[0. 0. 0. 1. 1. 1.]]
5 Keras中实现one-hot编码
详细代码如下:
#coding=utf-8
from keras.preprocessing.text import Tokenizer
tokens_samples = ['爸爸 妈妈 爱 我', '爸爸 妈妈 爱 中国', '我 爱 中国']
#构建单词索引
tokenizer = Tokenizer()
tokenizer.fit_on_texts(tokens_samples)
word_index = tokenizer.word_index
print(word_index) # {'爱': 1, '爸爸': 2, '妈妈': 3, '我': 4, '中国': 5}
print(len(word_index)) # 5
# 将词替换成索引
sequences = tokenizer.texts_to_sequences(tokens_samples)
print(sequences) # [[2, 3, 1, 4], [2, 3, 1, 5], [4, 1, 5]]
# 构建one-hot编码
one_hot_results = tokenizer.texts_to_matrix(tokens_samples)
print(one_hot_results)[[0. 1. 1. 1. 1. 0.]
[0. 1. 1. 1. 0. 1.]
[0. 1. 0. 0. 1. 1.]]
6 总结
本篇文章详细的从理论到实践带大家实现了one-hot编码的词向量表示,由于one-hot编码的缺点在实际做文本特征表示的时候现在不会再使用这种方法做文本特征表示,但是在做监督学习标签学习过程通常会把标签处理成one -hot表示,举个例子如果做多标签文本分类表示,用one-hot编码就可以很好地把每个标签表示出来,总之one-hot编码是最基本的文本特征表示大家还是要熟悉掌握的。下一篇文章我们将系统讲解word2vec词向量表示和短文本相似度实战任务。
由于知乎上面部分文章无法上传,想要获取更多文章关注微信公众号。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17967773,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号