Visual Genome数据集
Visual Genome(VG)是斯坦福大学李飞飞组于2016年发布的大规模图片语义理解数据集,他们希望该数据集能像ImageNet那样推动图片高级语义理解方面的研究。
在视觉关系检测(VRD)的研究中,VG几乎成了的标准数据集,然而,该数据集的许多缺陷也一直饱受诟病,当前的VRD研究者实在很有必要将该数据集的构建过程梳理清楚。
下面的介绍参考李飞飞组发表在IJCV上的论文Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations。
VG数据集包含了108077张图片,来自于MS-COCO的328000张和YFCC100M的100百万张的交集。这使得VG的标注可以和YFCC以及MS-COCO的分割以及全图caption一起使用。这些图片都是由用户上传到Flickrr的真实世界的、非图像符号的图片。这些图片的最小宽度为72像素,最长宽度为1280像素,平均为500像素。
数据集的组成
简单地概括,VG数据集主要由4个部分组成:
- Region Description:图片被划分成一个个region,每个region都有与其对应的一句自然语言描述。

- Region Graph:每个region中的object、attribute、relationship被提取出来,构成局部的“Scene Graph”。

- Scene Graph:把一张图片中的所有Region Graph合并成一个全局的Scene Graph。

- QA:每张图片会有多对QA,分为两种类型:region-based和freeform。前者基于Region Description提出,与局部region的内容直接相关;后者则基于整张图片来提出。
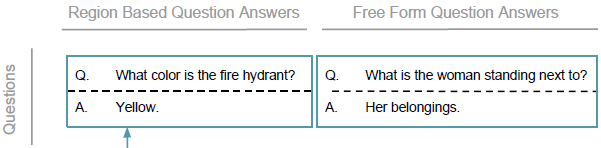
标注过程
这里我们主要关注VG数据集中的Region Graph标注过程。 与我一开始的设想不同,该数据集的标注员并不是一上来就直接标注relationship。因为作者们很敏锐地观察到,如果这样做的话,标注员往往倾向于标出一些高频而琐碎的关系,如wearing(man, shirt),而非聚焦于图片中最显眼的部分。 因此,标注员最终被要求先给出描述,再根据描述标注region bounding box、object、relationship等其他内容——当用自然语言描述图片时,人们更倾向于捕捉图片的主体部分。
数据集的统计分布
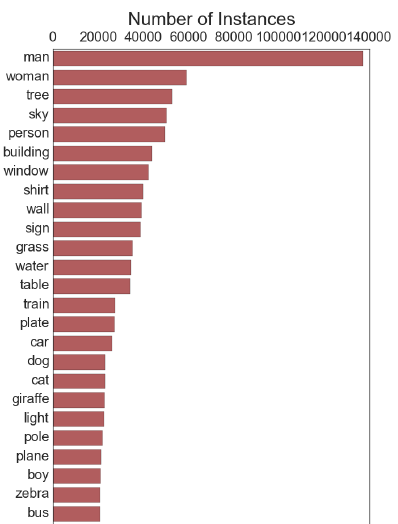
论文展示了数据集中最高频的一些object,其中大部分都与人类、动物、运动、场景有关,这也算是一种数据集的bias。
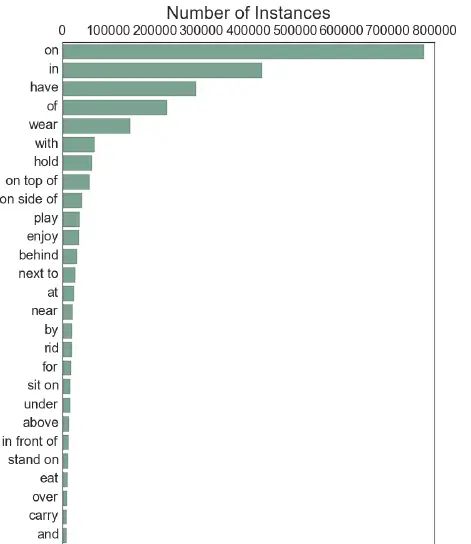
relationship(predicate)的统计则呈现出比较极端的长尾分布特点,on、in、have等少数简单的关系占据了绝大多数,我们在多篇论文中都能看到对此的讨论。
VG数据集的变种
VG150
虽然原始的VG数据规模很大,但是后人认为其中的object标注过于杂乱,存在命名模糊和bounding box重叠的问题。
因此李飞飞组后来的一个工作Scene Graph Generation by Iterative Message Passing对该数据集的object标注进行了清洗,同时,针对VRD任务,他们只取其中频率最大的150种object和50种predicate来做实验——为了便于区分,我们不妨把这个数据子集称为VG150。
后续的研究者纷纷在VG150上做实验,然而,VG150并没有改善relationship标注严重的bias问题。 在论文Neural Motifs: Scene Graph Parsing with Global Context中,作者提出了一个简单粗暴的baseline:利用object detector得到图上的object,针对每一对object,仅仅依据训练集的统计结果将出现最频繁的predicate作为预测结果。 然而,讽刺的是,这个很简单的baseline就已经比当时的许多模型效果好不少了。
VrR-VG
该数据集对应的论文VrR-VG: Refocusing Visually-Relevant Relationships发表在ICCV 2019上。 VrR的全称是Visually-Relevant Relationships,意思是,原VG数据集中的许多visual relationship实际上并不“visual”,即使不依靠视觉的信息也可以推断出来,而该数据集就旨在提炼出真正与视觉相关的relationship,与VG150的直观对比如下图所示(左图来自VG150,右图来自VrR-VG)。
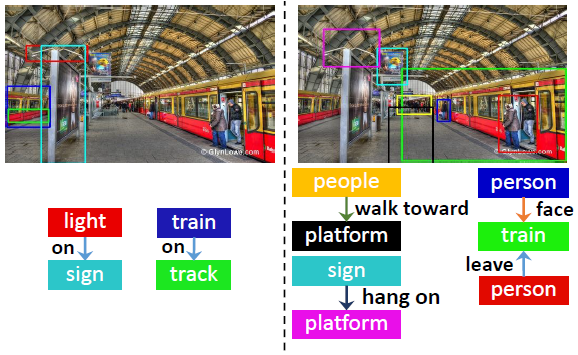
作者们构建这一数据集的思路实际上非常简单:训练一个很简陋的判别模型,仅仅以object的类别和bounding box位置作为输入,令其预测relationship,如果模型在这种不借助图像信息的设定下都能有效预测成功,则说明该relationship是与视觉无关的。 此外,针对原VG数据集中predicate冗余的情况,他们也通过词向量的聚类算法进行了提炼。 最终,VrR-VG与VG150的predicate分布对比如下:
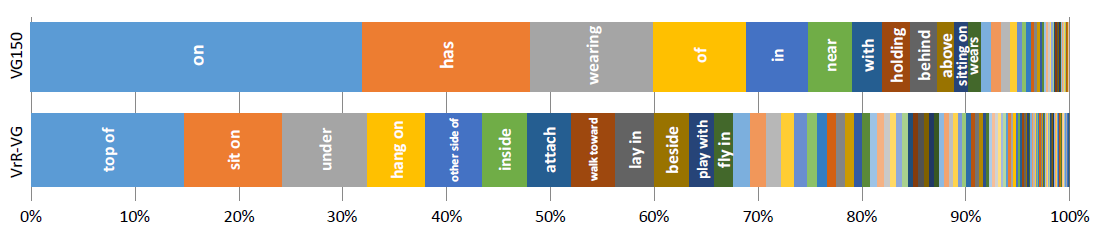
我们可以看到,对比VG150,VrR-VG的分布更加均匀和多样,predicate描述得也更加具体。
文章在此数据集上进行了一番实验,发现上述那种仅仅基于统计的“奇技淫巧”不再管用,说明VrR-VG显著改善了原来的bias问题。此外,从文章的另一个实验中也可以看到,与VG150相比,在VrR-VG上进行特征表示的预训练后,VQA和Image Captioning模型的性能普遍有了提升,说明VrR-VG中与视觉信息紧密相关的relationship更有助于推断复杂的视觉语义。
转自:https://zhuanlan.zhihu.com/p/102403048
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17960777,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号