SAM(segment-anything)解读-整理中
******************************2023年07月25日16:05:00*********************************
sam学习让人焦虑,很多参数概念不懂,无法领略全局,就像盲人摸象,边摸边想象,难受
SamAutomaticMaskGenerator(model: Sam, points_per_side: Optional[int] = 32, points_per_batch: int = 64, pred_iou_thresh: float = 0.88, stability_score_thresh: float = 0.95, stability_score_offset: float = 1.0, box_nms_thresh: float = 0.7, crop_n_layers: int = 2, crop_nms_thresh: float = 0.7, crop_overlap_ratio: float = 512 / 1500, crop_n_points_downscale_factor: int = 2, point_grids: Optional[List[np.ndarray]] = None, min_mask_region_area: int = 100, output_mode: str = "binary_mask", )
1.采用规则的点做为SAM的prompt,先将原图规则分割网格,得到32*32(points_per_side)个分割点;再将原图上crop2倍和4倍下采样(crop_n_layers)的小图片(裁剪的图片会有重叠),在裁剪的图片以同样分割网格的方式得到16*16,和8*8个(crop_n_points_downscale_factor=2,每次缩小2)分割点(相当有3种大小的图片)。
得到分割框存在重合,接下来会通过标准greedy nms 合并分割图,在一种大小的图片上,直接用预测的iou得分排序,在不同大小的图片上,优先小图片(4倍下采样大小)排序,通过nms计算的iou来过滤,阈值为0.7。
2.过滤。直接过滤掉预测的iou得分低于88;过滤不稳定的分割图,稳定的分割图含义是分割阈值在一定范围变化但是得到分割结果不变(也就是分割的置信度足够高);过滤掉超大的分割图(占原图尺寸的95%以上)
3.小目标的处理。如果几个分割目标相连为一组,其中小于100px的分割直接移除(min_mask_region_area)(最大的目标小于100px,移除整组分割结果);分割的结果如果有空洞(小于100px)直接填充,带入如下:
assert mode in ["holes", "islands"] correct_holes = mode == "holes" working_mask = (correct_holes ^ mask).astype(np.uint8) n_labels, regions, stats, _ = cv2.connectedComponentsWithStats(working_mask, 8) sizes = stats[:, -1][1:] # Row 0 is background label small_regions = [i + 1 for i, s in enumerate(sizes) if s < area_thresh] if len(small_regions) == 0: return mask, False fill_labels = [0] + small_regions if not correct_holes: fill_labels = [i for i in range(n_labels) if i not in fill_labels] # If every region is below threshold, keep largest if len(fill_labels) == 0: fill_labels = [int(np.argmax(sizes)) + 1] mask = np.isin(regions, fill_labels)
***********************************
sam的一个很重要的作用,用来寻找关注点
算法来源:meta
数据集:训练数据集一共1100万张,包含11亿个mask
训练gpu:256块(如果是个人特殊需求,就需要微调,而且也只能微调)
SAM(segment anything model)模型总体上分为3大块
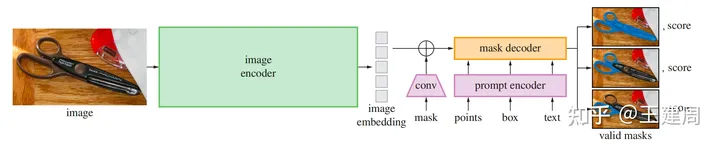
绿色的image encoder,将图像编码为向量。
紫色prompt encoder,将支持的prompt 内容编码为向量。
橙色的mask解码器,输出原图尺寸上的前后景概率以及iou score
三.图像编码器
SAM中的图像编码器采用标准的vit作为图像编码器,原始图像被等比和padding的缩放到1024大小,然后采用kernel size 为16,stride为16的卷积将图像离散化为64x64X768(W,H,C)的向量,向量在W和C上背顺序展平后再进入多层的transformer encoder,vit输出的向量再通过两层的卷积(kernel分别为1和3,每层输出接入layer norm2d)压缩到特征维度为256,如下代码
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
具体的图像编码器支持vit-h,vit-l,vit-b,vit经过了MAE方式的预训练,MAE属于图像中自监督学习的一种,如下图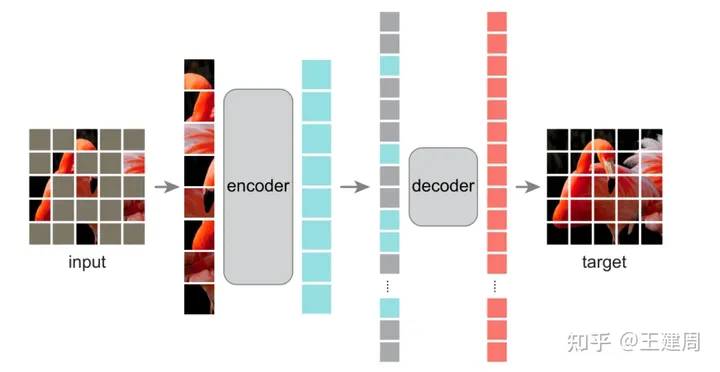
在MAE中原始图像如vit切割成不重叠的patch,保留部分patch进入vit架构的encoder进行学习patch的表示,学习到的patch表示和mask(灰色)的表示(所有的mask用统一的embedding,但是pos embedding不同)按照原始的patch顺序输入到vit架构的decoder,得到复原图像。loss为mask部分复原前后的l2 loss。训练完成后我们只使用encoder来提取图像特征(更多图像的自监督学习可以参考以前的博客 https://zhuanlan.zhihu.com/p/415675397)。从原始模型可以看出,图像的表征embedding是不变的,也就可以在已经编码好的图像embedding多次进行不同的prompt输入得到期望的结果,这个对交互式分割的场景是非常有用的。
四.prompt encoder
基于分割的任务需求,SAM 支持的prompt可以分为以下两类:
1.稀疏类(sparse prompt)。
包含 point,bbox,free text。
在编码方式上,点、bbox(左上点,右下点)采用sincos的位置编码embedding+学习的类别的embedding(一共5种类别,前景和后景的点类别,非点类别、bbox的左上类别、右下类别)
比如点的编码方式如下:
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
# self.not_a_point_embed为待学习的embedding
point_embedding[labels == -1] += self.not_a_point_embed.weight
# self.point_embeddings为待学习的embedding
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight其中当prompt 不提供bbox时,会在提供point上再追加点[0,0],label=-1的哑point,使用的类别特征embedding为上边的代码的self.not_a_point_embed
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)bbox的编码方式和点的保持一致,代码如下
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding如果提供一个point作为prompt,因为原始的图像可能有多个部件组成,所以这个点会属于多个部件,这种情况下会默认返回三种mask结果(全部,部分,子部分)如下图,这个点(绿色五角星)属于全部的前开车窗玻璃,部分车窗玻璃,和汽车的子部分,
2.稠密类(dense prompt)
在SAM中使用粗略的分割结果作为稠密的prompt输入,这里通过卷积进行特征提取。粗略的分割结果的shape为原始图像shape的1/4大小,再通过两层的分别下采样2倍的卷积降低W和H为原始图像的1/16,再通过1x1的卷积把维度变成256,这样粗略分割prompt的特征shape和图像特征的shape保持一致,代码如下
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)如果不提供粗略分割的输入,会用默认可学习的embedding代表空分割prompt的特征。
五.mask decoder
mask decoder 架构图如下,但是这张图没有说明太多细节不容易看懂。,下边将会详细介绍
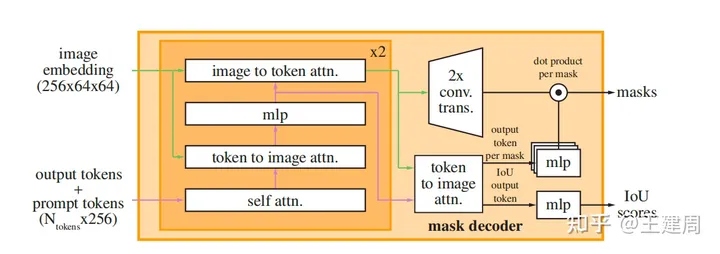
mask decoder的核心是用transformer 学习和prompt对齐后的image embedding 以及额外4个token的embedding。
这4个token embedding 分别是iou token embedding和3个分割结果 token的embedding(token类似自然语言整条文本的表征token [cls]),经过transformer 学习得到token 的embedding 会用于最终的任务头,得到目标结果。
transformer的输入有三个:
token embedding。前边4+1(1这个token 用于分离4目标token embedding和sparse prompt embedding,类似[sep])token embeding 拼接sparse prompt embedding。
# iou_token 1个;mask_tokens为4个,分别是3个输出结果对应的token,和一个分割sparse embedding的token
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
# BX(num_point+2*bbox+5) X256
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)src 。 image embedding 和dense prompt embedding的求和
# Expand per-image data in batch direction to be per-mask
# 对每一个token 都需要一个一样的image embedding
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)pos_src。 图像的位置编码,注意这里的位置编码类似DETR的,是二维编码,x和y方向分别编码再拼接,而不是传统vit将patch 拉成一维后编码,这样会损失y轴方向的信息,主要代码如下
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)在transformer中每层做以下四件事情
1.token embedding 做self attention 计算。
2.token embedding 和src 之间做cross attention 计算。
3.src 和token embedding 之间做cross attention 计算。
4.第2和3之间有前馈mlp网络;cross attention的结果通过残差方式相加并norm。
代码如下:
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
# query 为token embedding,会随着前向发生变化,query pe为最原始的token embedding
q = queries + query_pe
# keys 为src,key pe 为image pos embedding
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keystransform最终输出前,token embedding 还需要和src 做一次cross attention。
transform返回的3个mask token的embedding经过3层mlp后,与对齐后的图像embedding点击得到3个最终的分割结果;iou token 经过mlp得到3个分割结果置信度得分。
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out) 本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17550508.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号