大模型文本数据集统计之探索如何创建自己的数据集
项目1
https://github.com/tatsu-lab/stanford_alpaca
羊驼数据集52k,基于llama模型训练
此数据集是是使用llama模型自己生成数据,然后对这些生成进行过滤,以删除低质量或类似的生成,并将生成的数据添加回任务池。这个过程可以重复多次,从而产生大量的教学数据,这些数据可以用来微调语言模型,以更有效地遵循指令。此创建数据集的方法其实和目标检测任务创建高质量训练数据相似,也是用模型去审核训练数据
数据集地址: https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
以上数据的创建方法: https://github.com/yizhongw/self-instruct(如果需要的话重点看下这个)
创建方法的论文: https://arxiv.org/abs/2212.10560
项目2
https://github.com/tloen/alpaca-lora
这是小羊驼项目,基于stanford_alpaca,但是训练速度和资源占用更小,且测试效果相当,适合定制化
该项目的训练数据是对stanford_alpaca的训练数据进行清洗的,其中数据存在的问题,清洗方式都在https://github.com/gururise/AlpacaDataCleaned,这个里面提到的数据问题还是很有帮助的,这些问题是所有大模型的通病,所以后面制作自己的数据集时也一定要参考这个项目去清洗自己的数据.
清洗后的数据地址:https://huggingface.co/datasets/yahma/alpaca-cleaned
此外,还有另外一个数据集databricks-dolly-15k,本项目中为了适配alpaca的训练数据格式,去掉了citations,
databricks-dolly-15k下载地址: https://huggingface.co/datasets/c-s-ale/dolly-15k-instruction-alpaca-format
关于数据集databricks-dolly-15k的介绍,可以看我的这篇博客https://www.cnblogs.com/chentiao/p/17390876.html
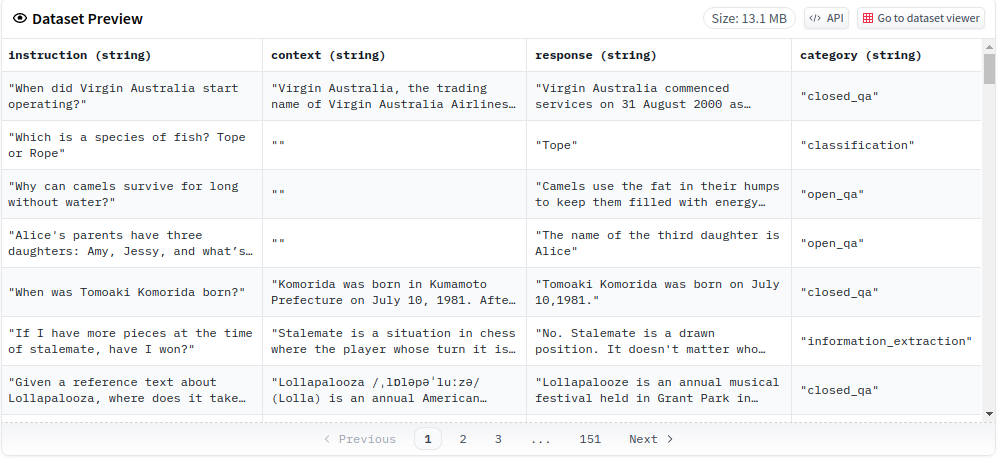
databricks-dolly-15k的原始数据格式为:
此外,该项目还使用了一个翻译数据集https://huggingface.co/datasets/HiTZ/alpaca_mt
该数据集由OpenAI的text-davinci-003引擎生成。这些指令数据可以用于对语言模型进行指令调优,使语言模型更好地遵循指令。该数据集还包括6种伊比利亚语言的机器翻译数据:葡萄牙语、西班牙语、加泰罗尼亚语、巴斯克语、加利西亚语和阿斯图里亚语。
项目3
https://github.com/LianjiaTech/BELLE
这个是链家的大模型项目,没错,就是租房买房链家.实在没有想到链家也有这样的研究,看来稍微有体量的公司都不愿意在下一代技术上失了先机.
这是一个中文项目,他的数据集也是中文的.而且他的数据都是由text-davinci-003产生的
具体的数据下载地址: https://github.com/LianjiaTech/BELLE/tree/main/data/1.5M
该数据集是1.5M中文数据集, 包含数个由BELLE项目产生的不同指令类型、不同领域的子集。
模型训练地址: https://github.com/LianjiaTech/BELLE/tree/main/train ,该训练环境提供了docker镜像,并且提供了单gpu训练方式
更多的训练数据可以直接关注链家的huggingface的主页,这里有最新的数据集: https://huggingface.co/BelleGroup
另外要注意,他的训练数据格式和alpaca是不一样的,如果后面要用到,要注意合并格式.

本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17386131.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号