多模态领域的开源图文数据集(持续更新中20230511)
Conceptual Caption
简称cc,minigpt4就使用这个数据集,一个大规模的图像文本配对数据集,包含超过30万个图像,每个图像都有5个人工描述。这个数据集的目的是为了促进计算机视觉和自然语言处理之间的研究交叉,可以用于图像检索、视觉问答等任务的训练和评估。
Conceptual Captions为从互联网获取的图文数据集。首先按格式、大小、内容和条件筛选图像和文本,根据文字内容能否较好地匹配图像内容过滤图文对,对文本中使用外部信息源的部分利用谷歌知识图谱进行转换处理,最后进行人工抽样检验和清理,获得最终数据集。Changpinyo等人(2021)基于Conceptual Captions将数据集的规模从330万增加到了1200万,提出了Conceptual12M。
下载地址: https://opendatalab.org.cn/Conceptual_Captions/download
SBU
一个用于图像标注的数据集,包含约1万张图片和每张图片5个描述。这个数据集中的描述是通过Amazon Mechanical Turk(一个众包平台)上的工人来收集的,可以用于图像标注、多模态数据集的训练等任务。
SBU(Ordonez等,2011)数据集: SBU是较为早期的大规模图像描述数据集。收集数据时,先使用对象、属性、动作、物品和场景查询词对图片分享网站Flickr进行查询,得到大量携带相关文本的照片,然后根据描述相关性和视觉描述性进行过滤,并保留包含至少两个拟定术语作为描述。
下载地址: https://opendatalab.org.cn/SBU_Captions_Dataset/download
LAION(Large-scale AI Open Network,“大规模人工智能开放网络”的简称)
项目链接:htttps://laion.ai/blog/laion-400-open-dataset/
论文标题:LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
论文链接:https://arxiv.org/abs/2111.02114
一个优秀的图文多模态数据集LAION,跟CLIP原始训练数据集就有相当体量,即400个million.
多模态语言-视觉模型通常是数亿个图文对(image-text pair)上训练出来的,比如CLIP、DALL-E。对于绝大部分研究者而言,要收集这样一个级别的数据集还是有相当难度的。这也是LAION团队收集并开源LAION-400M的原因。而且LAION-400M是用CLIP进行过滤的,所以理论上这个数据集质量会高于CLIP团队所用的400million的数据。
LAION-400M不仅给了这么大数量的图文对,还用CLIP把数据都推理了一遍,并且保存了embedding和kNN索引,咱们可以对这个大数据集高效索引。
索引网站:https://rom1504.github.io/clip-retrieval/
LAION-400M的概述如上。4亿个图片-文本对,并且附带4亿个URL和4亿个图片嵌入表示。一些kNN索引来支持快速搜索,以及一个数据处理库。
LAION-400M在收集数据时,做了一些过滤设定:
将文本短于5个字母或者图像小于5kb的图文对丢弃;
去重操作;
用CLIP计算图文相似性,抛弃掉相似性低于0.3的图文对;(重要)
筛除一些不合法的图文对,比如adult/violence/insulting等等。(love and peace化)
PS: 我在做实验的过程中,发现第三点尤为重要,之前团队收集过400M的某专用领域数据,一直训不到好结果。但用similarity 0.3过滤以后,哪怕数据量只有之前的1/10,训练效果却能达到非常好。
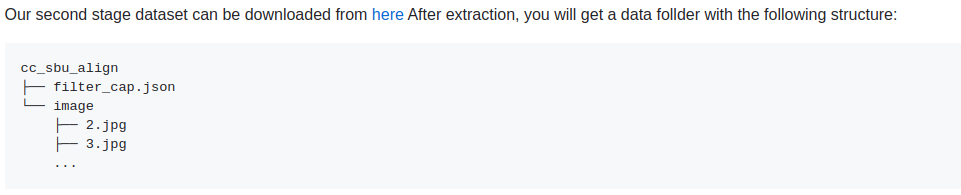
minigpt-4第二阶段微调高质量数据集
数据下载地址:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_2_STAGE.md
数据格式:
coco图像描述数据集(2014)
mscoco 2014的image caption数据集
包含image_id, caption, image等信息
下载地址:http://cocodataset.org/#home
多模态牧歌数据集(中文数据集)
MUGE(牧歌,Multimodal Understanding and Generation Evaluation)是业界首个大规模中文多模态评测基准,由达摩院联合浙江大学、阿里云天池平台联合发布,中国计算机学会计算机视觉专委会(CCF-CV专委)协助推出。目前包括: · 包含多模态理解与生成任务在内的多模态评测基准,其中包括图像描述、图文检索以及基于文本的图像生成。未来我们将公布更多任务及数据。 · 公开的评测榜单,帮助研究人员评估模型和追踪进展。 MUGE旨在推动多模态表示学习进展,尤其关注多模态预训练。具备多模态理解和生成能力的模型均可以参加此评测,欢迎各位与我们共同推动多模态领域发展。
包含image_id, label, image等信息。
数据集加载方式:
from modelscope.msdatasets import MsDataset ds = MsDataset.load("muge", namespace="modelscope", split="train") print(ds[0]) # {'query_id': '148144', 'query': 't恤 命运石之门', 'image_id': '797458', 'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=224x224 at 0x7FEB2F602278>} print(ds[0:2]) # {'query_id': ['148144', '87899'], 'query': ['t恤 命运石之门', '票登记'], 'image_id': ['797458', '56421'], 'image': [<PIL.PngImagePlugin.PngImageFile image mode=RGB size=224x224 at 0x7FEB2F602470>, <PIL.PngImagePlugin.PngImageFile image mode=RGB size=224x224 at 0x7FEB05822DA0>]}
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17381616.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号