什么是多模态
大模型的多模态指的是利用深度学习等技术,将不同类型的多模态数据结合起来训练的模型。这种模型通常使用多个模态的数据(例如图像、文本、语音、视频等)作为输入,并将它们融合在一起,以实现更全面、更准确的理解和推理。这种多模态模型的应用广泛,例如图像描述生成、视频分类、音频识别、语言翻译等领域。
大模型的多模态通常需要大量的训练数据和计算资源,以提高模型的性能和泛化能力。例如,OpenAI的DALL-E模型就是一种多模态的图像生成模型,使用了图像和文本的联合训练,并且使用了数百万张图片和文本对来训练。在这种大规模的训练过程中,需要使用分布式计算等技术来加速训练并提高模型的性能.
以BLIP 2为例介绍多模态
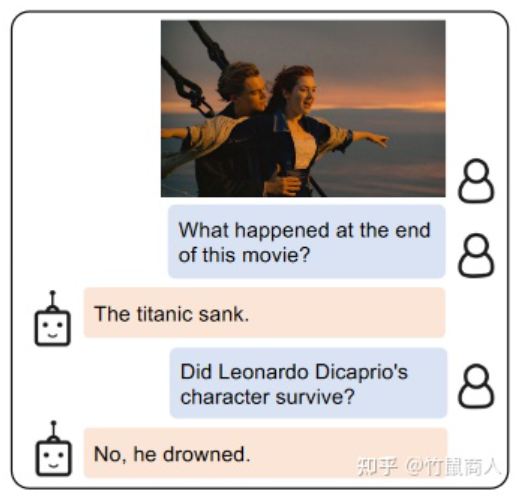
BLIP2模型的多模态问答
开始前介绍论文前我们先来讨论下,实现图片中的问答,需要什么能力呢?
-
图片里发生了什么:一位男士在船头搂着一位女士。(感知-CV模型的能力)
-
问题问的什么:电影的结尾是什么?(感知-NLP模型的能力)
-
图片和电影有什么关系:这是泰坦尼克号里的经典镜头。(对齐融合-多模态模型的能力)
-
电影的结尾是什么:泰坦尼克号沉没了。(推理-LLM模型的能力)
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17377482.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号