开源大模型(large language model, LLM)介绍
作为如今LLM圈内绝对的领头羊,OpenAI并没有遵从其创立初衷,无论是ChatGPT早期所使用的的GPT3、GPT3.5还是此后推出的GPT4模型,OpenAI都因“暂无法保证其不被滥用”为由拒绝了对模型开源,开启了订阅付费模式。
对于大型科技企业而言,不管是出于秀肌肉还是出于商业竞争目的,自研LLM都是一条几乎无可避免的道路。但对于缺少算力和资金的中小企业以及希望基于LLM开发衍生产品的开发者来说,选择开源显然是更理想的一条路线。
一 Meta:LLaMA,生态发展蓬勃
项目地址:github.com/facebookresearch/llama
注意上面这个项目地址是llama的推理代码,不是训练代,里面的模型下载可以直接在百度搜一下,不用按照meta的方式下载,太慢了,这里提供一个模型下载地址https://openai.wiki/llama-model-download.html
几周前,MetaAI推出了大语言模型LLaMA,其不同版本包括70亿、130亿、330亿和650亿的参数,虽然比GPT3还小,但LLaMA在许多任务上的性能都能够追平甚至超越GPT3。像我的3090的卡,最多智能运行70亿参数的模型,占用17g的显存,,整体模型占用25G磁盘空间
更值得注意的是,作为体量更小的模型,LLaMA不需要太多资源就能流畅运行,且LLaMA的训练成本及训练速度都要优于GPT3.5。
而有趣的是,LLaMA起初并未开源,但在发布后不久,模型便在4chan论坛上泄露了。然而这个乌龙事件却也使LLaMA因祸得福,在“被迫”开源后,LLaMA引发了大量开发者的关注,基于其构建的模型也如雨后春笋般诞生。这场本应是不幸的事情也使得LLaMA成为了如今LLM领域最具影响力的创新来源之一。
二 斯坦福大学:Alpaca,性价比拉满
项目地址:https://github.com/tatsu-lab/stanford_alpaca
Alpaca是斯坦福大学通过Meta的LLaMA 70亿微调而成的全新模型,仅使用了52k数据,但其性能却基本达到了GPT3.5的水平。而Alpaca的关键优势则在于低到出奇的训练成本——仅需不到600美元。
斯坦福大学的研究人员表示,Alpaca表现出了许多类似于OpenAI的GPT3模型的行为,但相比于GPT3,Alpaca的体积更小且各项能力更易于重现。
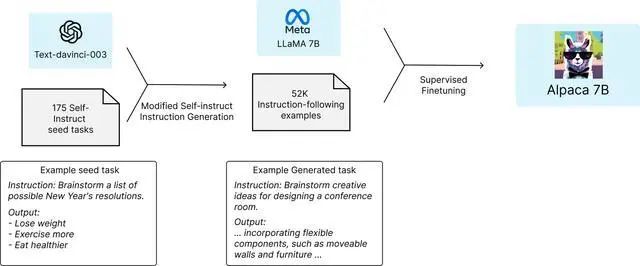
截至目前,斯坦福团队已在GitHub上开源了Alpaca模型微调所用到的数据集和代码,并提供了一个在线演示网站供用户体验。数据集包含了5.2万个由OpenAI API生成并人工筛选过后的问题-答案对。代码则基于华盛顿大学去年提出的Self-Instruct方法,让AI自己从种子任务中组合出新任务,并生成相应答案。
三 Databricks:Dolly2.0,全开源可商用
项目地址: https://huggingface.co/databricks/dolly-v2-12b
作为Dolly模型的升级版,Dolly2.0使用了基于 EleutherAI的Pythia模型家族中的120亿参数语言模型。虽然由于参数量和数据限制,Dolly2.0的综合性能表现略逊于同类型大模型,但对大部分开发者而言也已经足够了。并且Dolly2.0完全开源及可商用的属性,使其顺理成章的成为中小企业及个人开发者的福音。
四 Hugging Face:BLOOM,体量惊人
项目地址:huggingface.co/bigscience/bloom
BLOOM是去年由1000多名志愿者在一个名为BigScience的项目中创建的,该项目由AI初创公司Hugging Face利用法国政府的资金运作的。BLOOM拥有1760亿参数,研究人员表示它提供了与GPT3模型相似的准确性和有毒文本生成水平。
作为目前体量最大的开源大型语言模型之一,BLOOM的训练集包含45种自然语言(含中文)和12种编程语言,1.5TB的预处理文本转化为了350B的唯一token。实验证明BLOOM在各种基准测试中都取得了有竞争力的表现,在经过多任务提示微调后也取得了更好的结果。
五 阿卜杜拉国王科技大学MiniGPT4,图像对话能力可观
项目地址:github.com/Vision-CAIR/MiniGPT-4
MiniGPT4是近期由沙特阿拉伯阿卜杜拉国王科技大学研究团队推出的一款全新开源模型。据研究人员透露,MiniGPT4具有许多类似于GPT4的功能。除了可执行复杂的视觉语言任务外,MiniGPT4还拥有与GPT4相似的图片解析功能。
研究团队所发布的论文显示,为了构建MiniGPT4,研究人员使用了基于LLaMA所构建的Vicuna作为语言解码器,并使用BLIP-2视觉语言模型作为视觉解码器,且由于使用开源软件的缘故,MiniGPT可以用较少的数据和费用进行训练和微调。虽然由于模型发布较晚,该模型相关测评并未公布,但据GitHub显示,目前该研究团队已将MiniGPT的代码、预训练模型和数据集进行了开源。
六 Stability AIStableLM,万亿token训练
项目地址:github.com/Stability-AI/StableLM/issues
4月19日,Stability AI发布了一个新的开源语言模型——StableLM。该模型的Alpha版本有30亿和70亿参数,后续还会推出150亿和650亿参数的版本。根据CC BY-SA-4.0许可证的条款,开发人员可以出于商业或研究目的自由检查、使用和修改我们的StableLM基本模型。
据官方介绍,StableLM的构建基于非盈利研究中心EleutherAI所开源的多个语言模型,包括GPT-J,GPT-NeoX等,该模型在The Pile基础上构建的新数据集上进行训练,该数据集包含 1.5 万亿个token。可支持4096的上下文宽度,且RL调试模型可用。
但值得注意的是,该模型并为发布基准测试,也没有发布有关模型的详细信息,其基本型号上也存在一些限制性许可证。并且StableLM会抓取ChatGPT的输出内容,这会违反OpenAI的使用条款,OpenAI有权在收到通知后终止用户的访问。因此,在进行商用时,该模型依然存在一定的潜在风险。
七 元语智能ChatYuan,首个中文开源对话模型
作为首个中文版开源对话模型,元语智能ChatYuan大模型自发布以来便在人工智能社区引发了广泛的讨论。而在近期,元语智能团队再次开源了一个全新ChatYuan系列大模型:ChatYuan-large-v2。
据介绍,ChatYuan-large-v2支持在单张消费级显卡、PC甚至手机上进行推理使用。新版本支持中英双语、支持输入输出总长度最长4k,这也是继此前PromptCLUE-base、PromptCLUE- v1-5、ChatYuan-large-v1模型之后,元语智能的再一力作。
技术方面,ChatYuan-large-v2使用了和v1版本相同的方案,并在指令微调、人类反馈强化学习、思维链等方面进行了优化。作为ChatYuan系列模型中的代表,ChatYuan-large-v2仅通过7亿参数量可以实现业界100亿参数模型的基础效果。
项目地址:https://github.com/clue-ai/ChatYuan
八 清华大学ChatGLM,开辟小而精方向
项目地址:github.com/THUDM/ChatGLM-6B
ChatGLM是由清华技术成果转化的公司智谱AI开发的开源、支持中英双语的对话语言模型,基于General Language Model (GLM) 架构研发,拥有62亿参数,支持在单张消费级显卡上进行推理使用,在保障平民消费能力的情况下,具有小而精的特点。
ChatGLM当前版本模型的能力提升主要来源于独特的千亿基座模型GLM-130B。其不同于BERT、GPT-3以及T5架构,包含多目标函数的自回归预训练模型。研发团队参考了ChatGPT的设计思路,为ChatGLM在基座模型GLM-130B中注入了代码预训练,通过有监督微调等技术实现人类意图对齐。
从具体数据及测试表现来看,ChatGLM具备兼具双语能力;易微调、部署门槛低;支持长对话与应用以及内容输出格式简单等优势。但由于模型容量较小,ChatGLM也不可避免的存在着模型记忆和语言能力较弱;可能产生错误内容和多轮对话能力不足等一些缺点。
九 昆仑万维天工系列模型,新模型实现智能涌现
去年年底,昆仑万维发布了昆仑天工系列模型并宣布模型开源,包括天工巧绘SkyPaint、天工乐府SkyMusic、天工妙笔SkyText、天工智码SkyCode,分别涉及AI图像、AI音乐、AI文本、AI编程方面,目前已经有中国移动、咪咕等企业测试使用。
而就在近日,昆仑万维再次发布了最新迭代升级的大语言模型天工3.5。据官方表示,天工3.5是第一个实现智能涌现的国产大语言模型,已“非常接近ChatGPT的智能水平”,可满足文案创作、问答、代码生成、逻辑推理与数理推算等需求
十 大模型时代:开源vs闭源
PC时代,Linux打破了Wintel联盟的垄断;在iOS的封闭生态和Android的准封闭生态下,开源RISC-V实现了异军突起。开源从始至终都意味着自由开放、意味着全球开发者能够同时贡献和维护所带来的迭代效率与风险控制。
在大模型时代,开源与闭源的问题被再次搬上桌面。从短期角度讲,无论是出于安全性、版权问题还是商业竞争的考量,OpenAI或是其他拥有大模型的科技企业选择闭源都无可厚非。但从长期角度出发,对于每个大模型以及整个领域的发展而言,开源生态所带来的帮助势必将超越企业本身。
回首往昔,Linux的成功,并不是依靠技术的先进性击败了其他操作系统,而是借助蓬勃的开源生态在激烈的市场竞争中占据了主导地位。而这样的故事在今天或是未来是否依然会继续发生,就让我们一起拭目以待。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17353395.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号