Joblib介绍-常在机器学习中使用
joblib是一个用于Python的开源库,提供了一些用于并行计算和内存映射的工具。它是为了提高科学计算和数据分析的效率而设计的。
具体来说,joblib库提供了两个重要的功能:
-
并行计算:
joblib提供了一个高级的并行化工具,使您能够轻松地将计算任务分配到多个CPU核心上执行。它还提供了一些用于并行化内循环的工具,以提高数组操作的效率。 -
内存映射:
joblib提供了一些内存映射工具,使您能够将大型数组或数据集存储在磁盘上,并在需要时按需加载到内存中。这可以帮助您克服内存限制问题,同时还可以提高数据访问速度。
joblib库的主要特点是易于使用和高效性能。它是NumPy、SciPy和scikit-learn等其他Python科学计算库的常用工具,因为它可以使这些库的计算更快速、更简单。
一、并行计算
Joblib是一个可以简单地将Python代码转换为并行计算模式的软件包,它可非常简单并行我们的程序,从而提高计算速度。
Joblib是一组用于在Python中提供轻量级流水线的工具。 它具有以下功能:
- 透明的磁盘缓存功能和“懒惰”执行模式,简单的并行计算
- Joblib对numpy大型数组进行了特定的优化,简单,快速。
示例:
以下我们使用一个简单的例子来说明如何利用Joblib实现并行计算。 我们使用单个参数i定义一个简单的函数my_fun()。 此函数将等待1秒,然后计算i**2的平方根,也就是返回i本身。
from joblib import Parallel, delayed
import time, math
def my_fun(i):
""" We define a simple function here.
"""
time.sleep(1)
return math.sqrt(i**2)
这里我们将总迭代次数设置为10.我们使用time.time()函数来计算my_fun()的运行时间。 如果使用简单的for循环,计算时间约为10秒。
num = 10
start = time.time()
for i in range(num):
my_fun(i)
end = time.time()
print('{:.4f} s'.format(end-start))
》》》
10.0387 s使用Joblib中的Parallel和delayed函数,我们可以简单地配置my_fun()函数的并行运行。 其中我们会用到几个参数,n_jobs是并行作业的数量,我们在这里将它设置为2。 i是my_fun()函数的输入参数,依然是10次迭代。两个并行任务给节约了大约一半的for循环运行时间,结果并行大约需要5秒。
start = time.time()
# n_jobs is the number of parallel jobs
Parallel(n_jobs=2)(delayed(my_fun)(i) for i in range(num))
end = time.time()
print('{:.4f} s'.format(end-start))
5.6560 s就是这么简单! 如果我们的函数中有多个参数怎么办? 也很简单。 让我们用两个参数定义一个新函数my_fun_2p(i,j)。
def my_fun_2p(i, j):
""" We define a simple function with two parameters.
"""
time.sleep(1)
return math.sqrt(i**j)
j_num = 3
num = 10
start = time.time()
for i in range(num):
for j in range(j_num):
my_fun_2p(i, j)
end = time.time()
print('{:.4f} s'.format(end-start))
30.0778 s
start = time.time()
# n_jobs is the number of parallel jobs
Parallel(n_jobs=2)(delayed(my_fun_2p)(i, j) for i in range(num) for j in range(j_num))
end = time.time()
print('{:.4f} s'.format(end-start))
15.0622 s除了并行计算功能外,Joblib还具有以下功能:
- 快速磁盘缓存:Python函数的memoize或make-like功能,适用于任意Python对象,包括大型numpy数组。
- 快速压缩:替代pickle,使用joblib.dump和joblib.load可以提高大数据的读取和存储效率。
二、保存训练好的模型并快捷调用
用已知数据集训练出一个较为精准的模型是一件乐事,但当关机或退出程序后再次接到 “ 用新的格式相同的数据来进行预测或分类 ” 这样的任务时;又或者我们想把这个模型发给同事并让TA用于新数据的预测......
难道又要自己或他人重复运行用于训练模型的源数据和代码吗?[1]
大可不必!
joblib 下载/加载最佳模型
- 下载最佳模型
反复调优后,我们通常能够获得一个相对精准的模型。常见的做法是将其保存在一个变量中用于后续的预测。这里以往期推文为例:
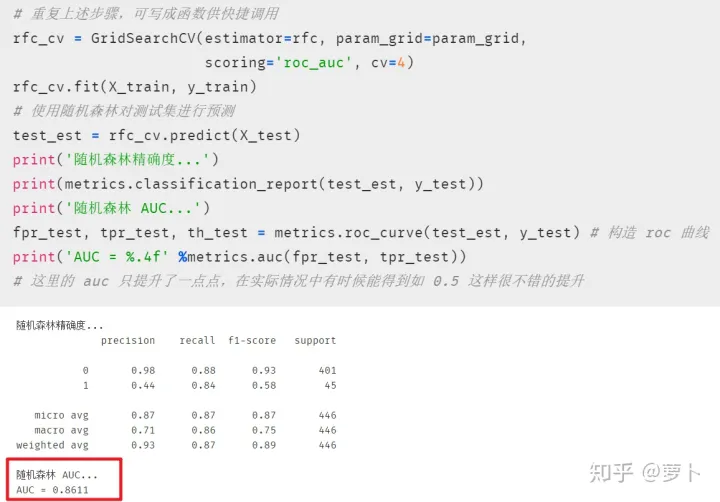
得到相对最优模型后,我们便可用变量将其存起来并进行预测
# 将最佳模型存储在变量 best_est 中 best_est = rfc_cv.best_estimator_
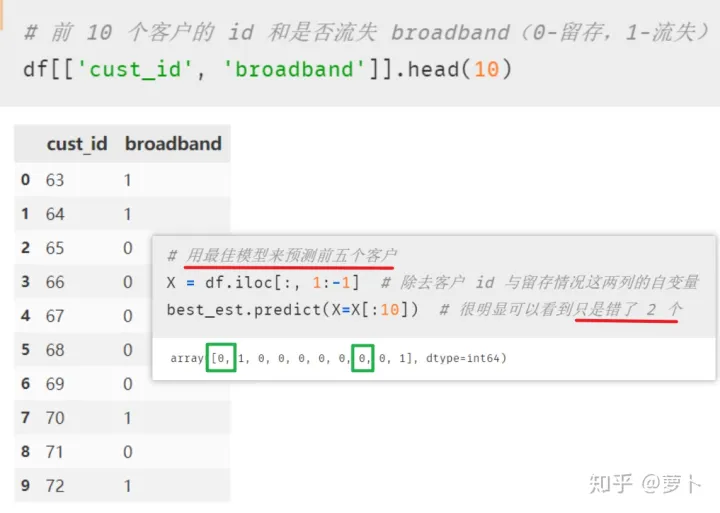
当出现文章开头的问题时,重新运行一遍"best_est = rfc_cv.best_estimator_"这行前的所有代码显然是很不明智的。这个时候我们便可以通过 sklearn 的 joblib 包来把我们训练好的模型下载成可执行的代码文件(拓展名为 .m)供后续使用。
from sklearn.externals import joblib
# joblib 中的 dump 函数用于下载模型
joblib.dump(value=best_est, filename='mybest_dt_model.m')仅仅两行就搞定,接着我们便能看到当前目录出现后缀为 .m 的文件~
- 加载模型并用于预测
现在楼上的运营部那个懂一点点 Python 的同事已经收到了我发给TA的 m 文件,现在TA只需要一行代码就可将其加载出来,而后便可愉快的使用我训练好的模型了
# 加载模型 model = joblib.load(filename='mybest_dt_model.m')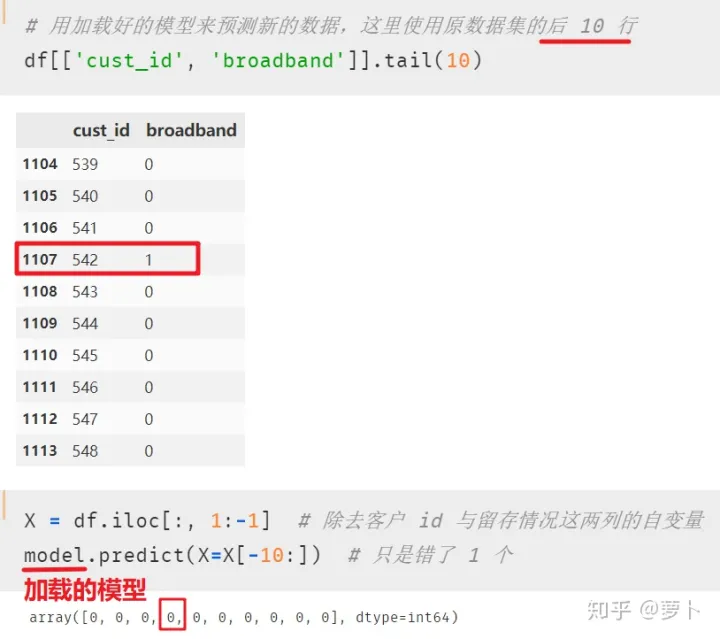
小结&注意
本文展示了如何通过 joblib 的短短三行代码便将自己的心血下载成可执行文件供自己或别人后续使用,但这其中也有一些值得注意的地方:
- 加载下载好的模型用于预测时,用到的数据的格式应与训练该模型时的一致(变量个数、名称与格式等)。
- 在从sklearn.externals引入joblib函数时,常会出现如下报错:from klearn.externals import joblib ImportError: cannot import name 'joblib',通常joblib导入不成功时主要是sklearn版本的问题,我们可以先卸载原有的sklearn,pip uninstall joblibscikit-leran sklearn,再安装指定版本的sklearn,pip install Scikit-learn==0.20.4 即可。
参考
- ^作者:萝卜 链接:https://zhuanlan.zhihu.com/p/271699794 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/17126777.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号