syncbn讲解(同步Batch Normalization)
目前网络的训练多为多卡训练,大型网络结构以及复杂任务会使得每张卡负责的batch-size小于等于1,若不进行同步BN,moving mean、moving variance参数会产生较大影响,造成BN层失效。
为简化inference过程,以及商业代码保密,通常进行BN融合操作。即把BN参数融合至conv层。
BN 的性能和 batch size 有很大的关系。batch size 越大,BN 的统计量也会越准。然而像检测这样的任务,占用显存较高,一张显卡往往只能拿较少的图片(比如 2 张)来训练,这就导致 BN 的表现变差。一个解决方式是 SyncBN:所有卡共享同一个 BN,得到全局的统计量。
PyTorch 的 SyncBN 分别在 torch/nn/modules/batchnorm.py 和 torch/nn/modules/_functions.py 做了实现。前者主要负责检查输入合法性,以及根据momentum等设置进行传参,调用后者。后者负责计算单卡统计量以及进程间通信。
class SyncBatchNorm(_BatchNorm): def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True, process_group=None): super(SyncBatchNorm, self).__init__(num_features, eps, momentum, affine, track_running_stats) self.process_group = process_group # gpu_size is set through DistributedDataParallel initialization. This is to ensure that SyncBatchNorm is used # under supported condition (single GPU per process) self.ddp_gpu_size = None def _check_input_dim(self, input): if input.dim() < 2: raise ValueError('expected at least 2D input (got {}D input)' .format(input.dim())) def _specify_ddp_gpu_num(self, gpu_size): if gpu_size > 1: raise ValueError('SyncBatchNorm is only supported for DDP with single GPU per process') self.ddp_gpu_size = gpu_size def forward(self, input): if not input.is_cuda: raise ValueError('SyncBatchNorm expected input tensor to be on GPU') self._check_input_dim(input) # exponential_average_factor is set to self.momentum # (when it is available) only so that it gets updated # in ONNX graph when this node is exported to ONNX. # 接下来这部分与普通BN差别不大 if self.momentum is None: exponential_average_factor = 0.0 else: exponential_average_factor = self.momentum if self.training and self.track_running_stats: self.num_batches_tracked = self.num_batches_tracked + 1 if self.momentum is None: # use cumulative moving average exponential_average_factor = 1.0 / self.num_batches_tracked.item() else: # use exponential moving average exponential_average_factor = self.momentum # 如果在train模式下,或者关闭track_running_stats,就需要同步全局的均值和方差 need_sync = self.training or not self.track_running_stats if need_sync: process_group = torch.distributed.group.WORLD if self.process_group: process_group = self.process_group world_size = torch.distributed.get_world_size(process_group) need_sync = world_size > 1 # 如果不需要同步,SyncBN的行为就与普通BN一致 if not need_sync: return F.batch_norm( input, self.running_mean, self.running_var, self.weight, self.bias, self.training or not self.track_running_stats, exponential_average_factor, self.eps) else: if not self.ddp_gpu_size: raise AttributeError('SyncBatchNorm is only supported within torch.nn.parallel.DistributedDataParallel') return sync_batch_norm.apply( input, self.weight, self.bias, self.running_mean, self.running_var, self.eps, exponential_average_factor, process_group, world_size) # 把普通BN转为SyncBN, 主要做一些参数拷贝 @classmethod def convert_sync_batchnorm(cls, module, process_group=None): module_output = module if isinstance(module, torch.nn.modules.batchnorm._BatchNorm): module_output = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum, module.affine, module.track_running_stats, process_group) if module.affine: with torch.no_grad(): module_output.weight.copy_(module.weight) module_output.bias.copy_(module.bias) # keep requires_grad unchanged module_output.weight.requires_grad = module.weight.requires_grad module_output.bias.requires_grad = module.bias.requires_grad module_output.running_mean = module.running_mean module_output.running_var = module.running_var module_output.num_batches_tracked = module.num_batches_tracked for name, child in module.named_children(): module_output.add_module(name, cls.convert_sync_batchnorm(child, process_group)) del module return module_output
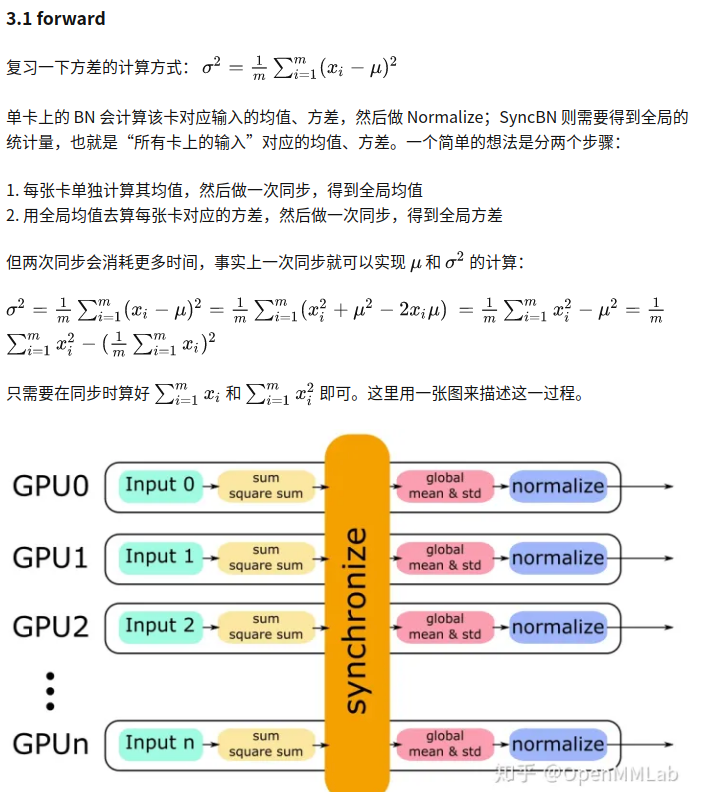
实现时,batchnorm.SyncBatchNorm 根据自身的超参设置、train/eval 等设置参数,并调用_functions.SyncBatchNorm,接口是def forward(self, input, weight, bias, running_mean, running_var, eps, momentum, process_group, world_size): 首先算一下单卡上的均值和方差:
# 这里直接算invstd,也就是 1/(sqrt(var+eps))
mean, invstd = torch.batch_norm_stats(input, eps)然后同步各卡的数据,得到mean_all和invstd_all,再算出全局的统计量,更新running_mean,running_var:
# 计算全局的mean和invstd
mean, invstd = torch.batch_norm_gather_stats_with_counts(
input,
mean_all,
invstd_all,
running_mean,
running_var,
momentum,
eps,
count_all.view(-1).long().tolist()
)
由于不同的进程共享同一组 BN 参数,因此在 backward 到 BN 前、后都需要做进程的通信,在_functions.SyncBatchNorm中实现:
# calculate local stats as well as grad_weight / grad_bias
sum_dy, sum_dy_xmu, grad_weight, grad_bias = torch.batch_norm_backward_reduce(
grad_output,
saved_input,
mean,
invstd,
weight,
self.needs_input_grad[0],
self.needs_input_grad[1],
self.needs_input_grad[2]
)
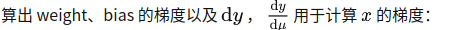
# all_reduce 计算梯度之和
sum_dy_all_reduce = torch.distributed.all_reduce(
sum_dy, torch.distributed.ReduceOp.SUM, process_group, async_op=True)
sum_dy_xmu_all_reduce = torch.distributed.all_reduce(
sum_dy_xmu, torch.distributed.ReduceOp.SUM, process_group, async_op=True)
# ...
# 根据总的size,对梯度做平均
divisor = count_tensor.sum()
mean_dy = sum_dy / divisor
mean_dy_xmu = sum_dy_xmu / divisor
# backward pass for gradient calculation
grad_input = torch.batch_norm_backward_elemt(
grad_output,
saved_input,
mean,
invstd,
weight,
mean_dy,
mean_dy_xmu
)本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16787543.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号