Yolov4v5的模型结构与正负样本匹配
from:https://blog.csdn.net/weixin_44751294/article/details/124205979
国庆几天没有更新过博客,今天开张了,新的格局开始了。
如有错误,恳请指出。
以下内容是学习了参考资料作的笔记,仅供参考,详细内容见参考资料。这里我主要是对yolov4和v5的模型结构记录,及其了解其正负样本匹配的方式。
另外的就是介绍一下Albumentations工具包,这是专门用于计算机视觉中数据增强的一个工具包,提高的数据增强方式比较多,使用也比较方便。
1. Yolov4
1.1 Yolov4结构
yolov4的结构图:
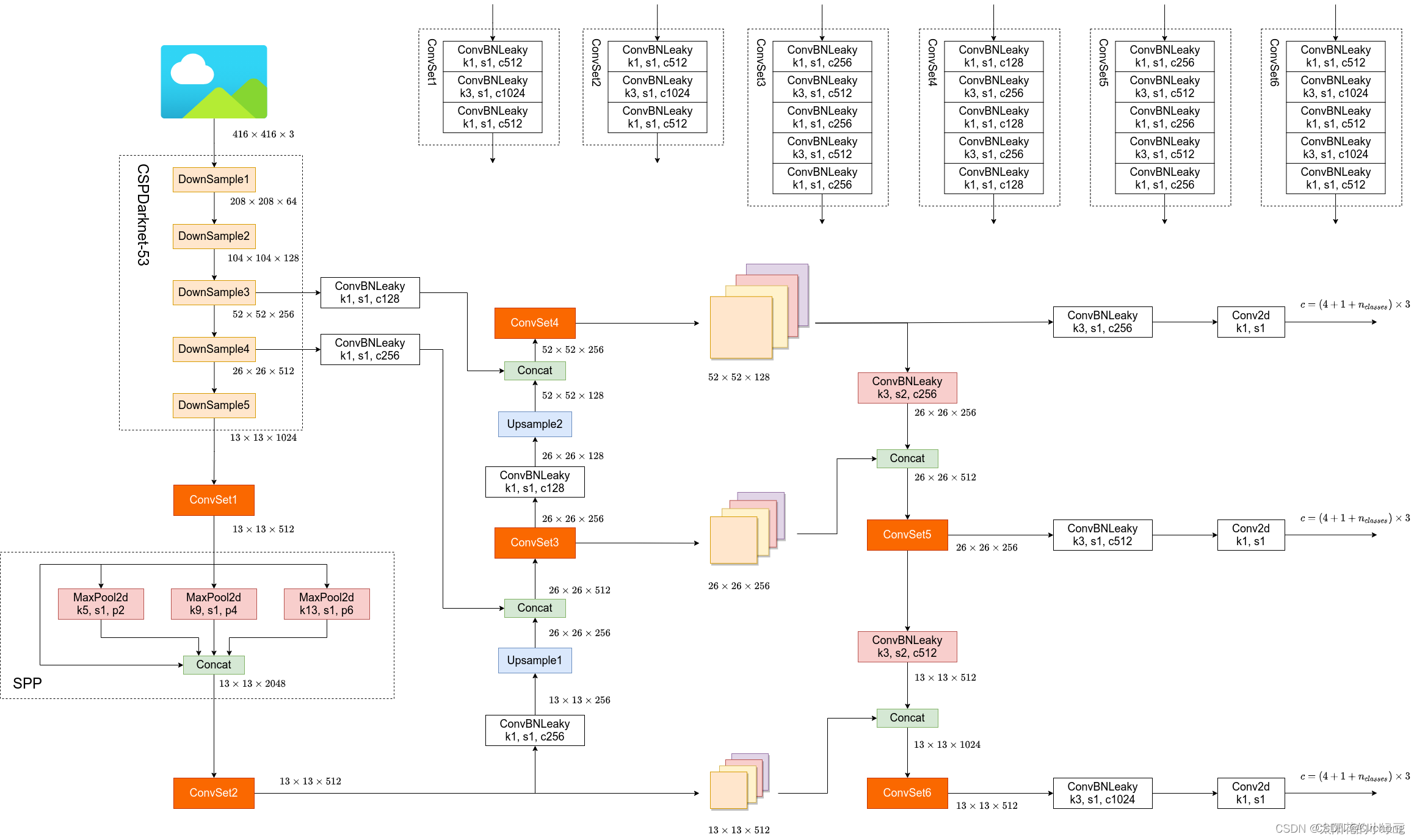
对于yolov4,之前已经看个了paper总结了一篇笔记,这里就跳过大体部分,之前的笔记见:目标检测算法——YOLOv4。
1.2 训练策略
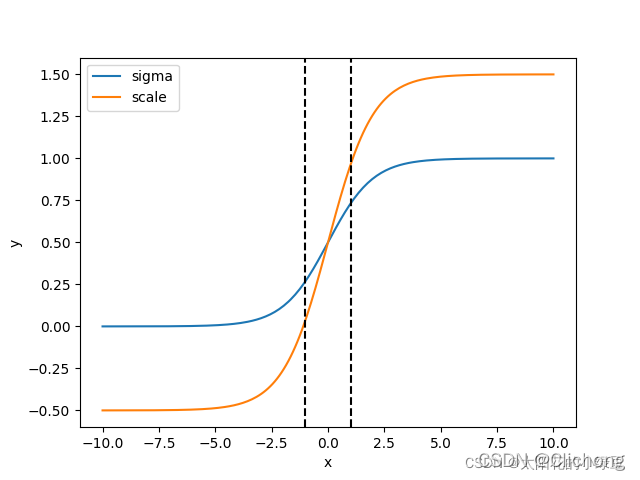
详细补充一下其消除网格信息(Eliminate grid sensitivity)的做法: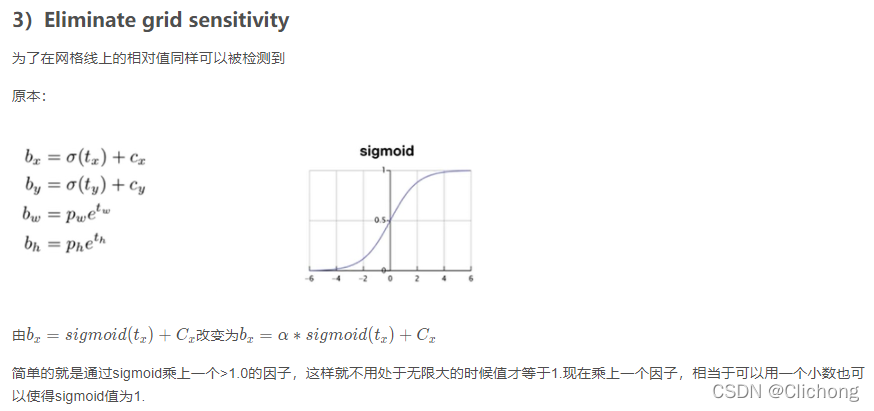
问题:当真实目标中心点非常靠近网格的左上角点(σ(tx)和σ(ty)应该趋近与0 或者右下角点(σ(tx))和σ(ty)应该趋近与1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。
对于具体的改变来说,作者是增加了一个缩放系数与偏移量,从而可以比较容易的接近0-1点,不需要无穷值才可以接近,具体公式为: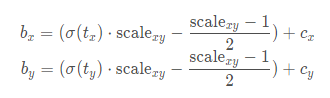
通过引入这个系数,网络的预测值能够很容易达到0或者1;一般讲scalexy设置为2,所以公式为:
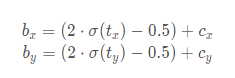
这样,通过引入1缩放系数scale之后,x在同样的区间内,y的取值范围更大,偏移的范围由原来的(0, 1)调整到了(-0.5, 1.5)
1.3 正负样本匹配
在YOLOv3中针对每一个GT都只分配了一个Anchor。但在YOLOv4包括之前讲过的YOLOv3 SPP以及YOLOv5中一个GT可以同时分配给多个Anchor,它们是直接使用Anchor模板与GT Boxes进行粗略匹配,然后在定位到对应cell的对应Anchor。
- YOLOv3 SPP正负样本的匹配过程:
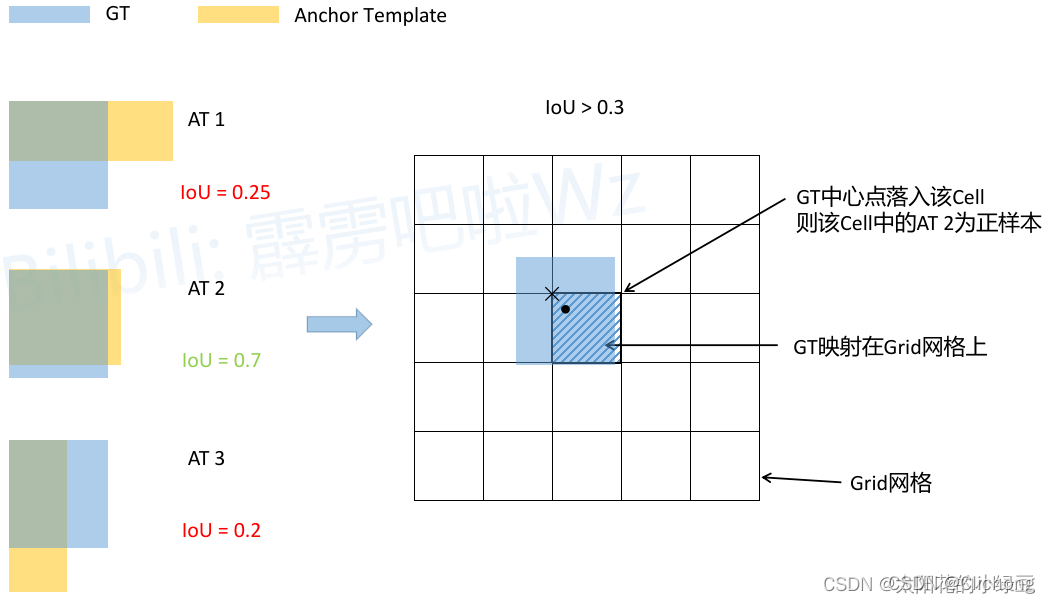
简要分析:
- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU)
- 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的AT 2
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应cell(图中黑色的× \times×表示cell的左上角)
- 则该cell对应的AT2为正样本
- YOLOv4v5正负样本的匹配过程:
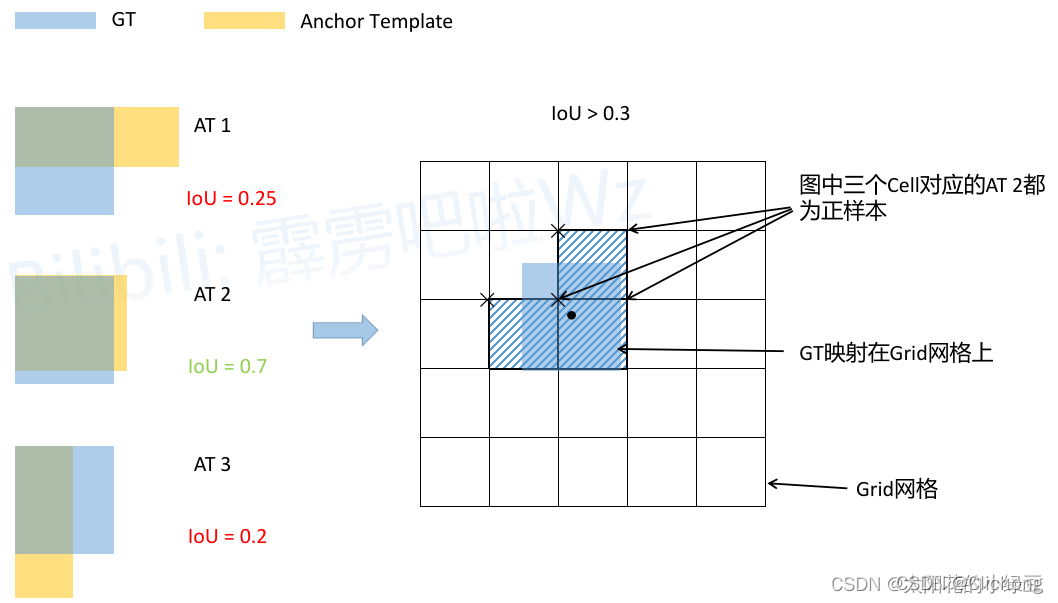
简要分析:
- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU,在YOLOv4中IoU的阈值设置的是0.213)
- 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的AT 2
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应cell(这是因为网格预测中心点的偏移范围已经调整了,不过扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展)
- 则这三个cell对应的AT2都为正样本
2. Yolov5
2.1 Yolov5结构
yolov5的结构图: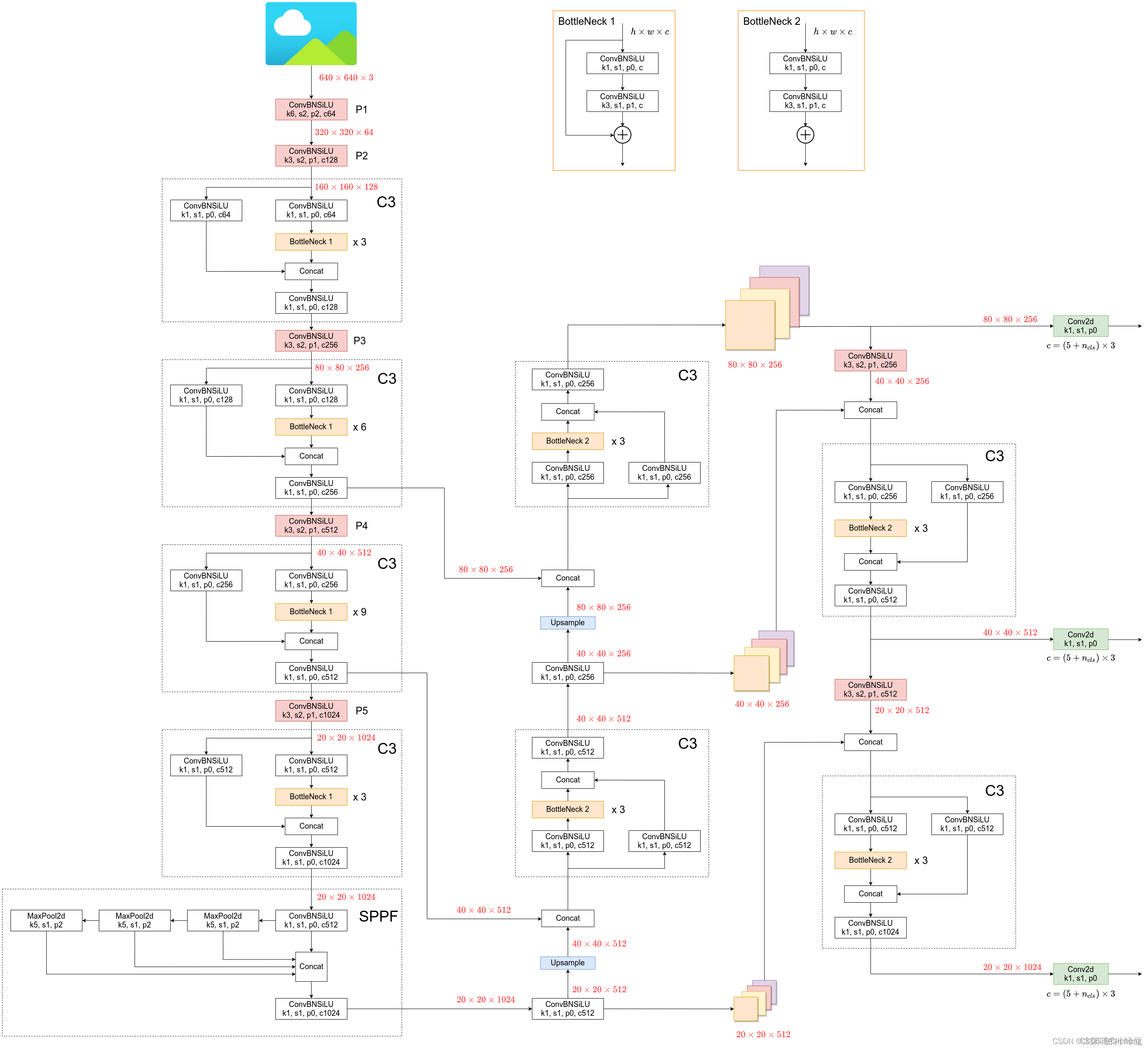
2.2 训练策略
Eliminate grid sensitivity同v4的做法,这里再记录一下yolov5的训练策略与其用到的一些数据增强:
- Yolov5用到的一些训练策略:
- Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 640 640 \times 640640×640,训练时采用尺寸是在0.5 × 640 ∼ 1.5 × 640 0.5 \times 640 \sim 1.5 \times 6400.5×640∼1.5×640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
- AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。
- Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
- EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
- Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
- Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
- Yolov5用到的一些数据增强:
- Mosaic,将四张图片拼成一张图片
- Copy paste,将部分目标随机的粘贴到图片中,前提是数据要有segments数据才行,即每个目标的实例分割信息
- Random affine(Rotation, Scale, Translation and Shear),随机进行仿射变换(旋转,缩放,平移,裁剪)
- MixUp,就是将两张图片按照一定的透明度融合在一起
- Albumentations,主要是做些滤波、直方图均衡化以及改变图片质量等等(
- Augment HSV(Hue, Saturation, Value),随机调整色度,饱和度以及透明度
- Random horizontal flip,随机水平翻转
ps:这里推荐一个数据增强的工具包:Albumentations 。
- github地址:https://github.com/albumentations-team/albumentations
- docs使用文档:https://albumentations.ai/docs
其涵盖了绝大部分的数据增强方式,如下:
简单的使用例子:
# 使用 Albumentations 为训练和验证数据集定义转换函数
class CatsVsDogsDataset(Dataset):
def __init__(self, images_filepaths, transform=None):
self.images_filepaths = images_filepaths
self.transform = transform
def __len__(self):
return len(self.images_filepaths)
def __getitem__(self, idx):
image_filepath = self.images_filepaths[idx]
image = cv2.imread(image_filepath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if os.path.normpath(image_filepath).split(os.sep)[-2] == "Cat":
label = 1.0
else:
label = 0.0
if self.transform is not None:
image = self.transform(image=image)["image"]
return image, label
train_transform = A.Compose(
[
A.SmallestMaxSize(max_size=160),
A.ShiftScaleRotate(shift_limit=0.05, scale_limit=0.05, rotate_limit=15, p=0.5),
A.RandomCrop(height=128, width=128),
A.RGBShift(r_shift_limit=15, g_shift_limit=15, b_shift_limit=15, p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2(),
]
)
train_dataset = CatsVsDogsDataset(images_filepaths=train_images_filepaths, transform=train_transform)
val_transform = A.Compose(
[
A.SmallestMaxSize(max_size=160),
A.CenterCrop(height=128, width=128),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2(),
]
)
val_dataset = CatsVsDogsDataset(images_filepaths=val_images_filepaths, transform=val_transform)
可以看见,使用方法类似于pytorch的transform。这里作一个简单的对比,下面的代码是之前自定义宝可梦数据集的例子,见博文:自定义宝可梦数据集
# 对图像进行预处理
transform = transforms.Compose([
# 转换为RGB图像
lambda x: Image.open(x).convert('RGB'),
# 重新确定尺寸
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
# 旋转角度
transforms.RandomRotation(15),
# 中心裁剪
transforms.CenterCrop(self.resize),
# 转换为Tensor格式
transforms.ToTensor(),
# 使数据分布在0附近
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
image = transform(image)所以,使用的方法是类似的。不过,在Albumentations提供的数据增强方式比pytorch官方的更多,使用也比较方便。
2.3 正负样本匹配
这样同样类似于v4的做法,但是主要的区别在于GT Box与Anchor Templates模板的匹配方式。在YOLOv4中是直接将每个GT Box与对应的Anchor Templates模板计算IoU,只要IoU大于设定的阈值就算匹配成功。但在YOLOv5中,作者先去计算每个GT Box与对应的Anchor Templates模板的高宽比例;然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小);接着统计宽度方向与高度方向的最大差异之间的最大值(二值取最大),即宽度和高度方向差异最大的值:

GT Box和对应的Anchor Template的rmax小于阈值anchor_t(在源码中默认设置为4.0),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。为了方便大家理解,可以看下画的图。假设对某个GT Box而言,其实只要GT Box满足在某个Anchor Template宽和高的× 0.25 \times 0.25×0.25倍和× 4.0 \times 4.0×4.0倍之间就算匹配成功。
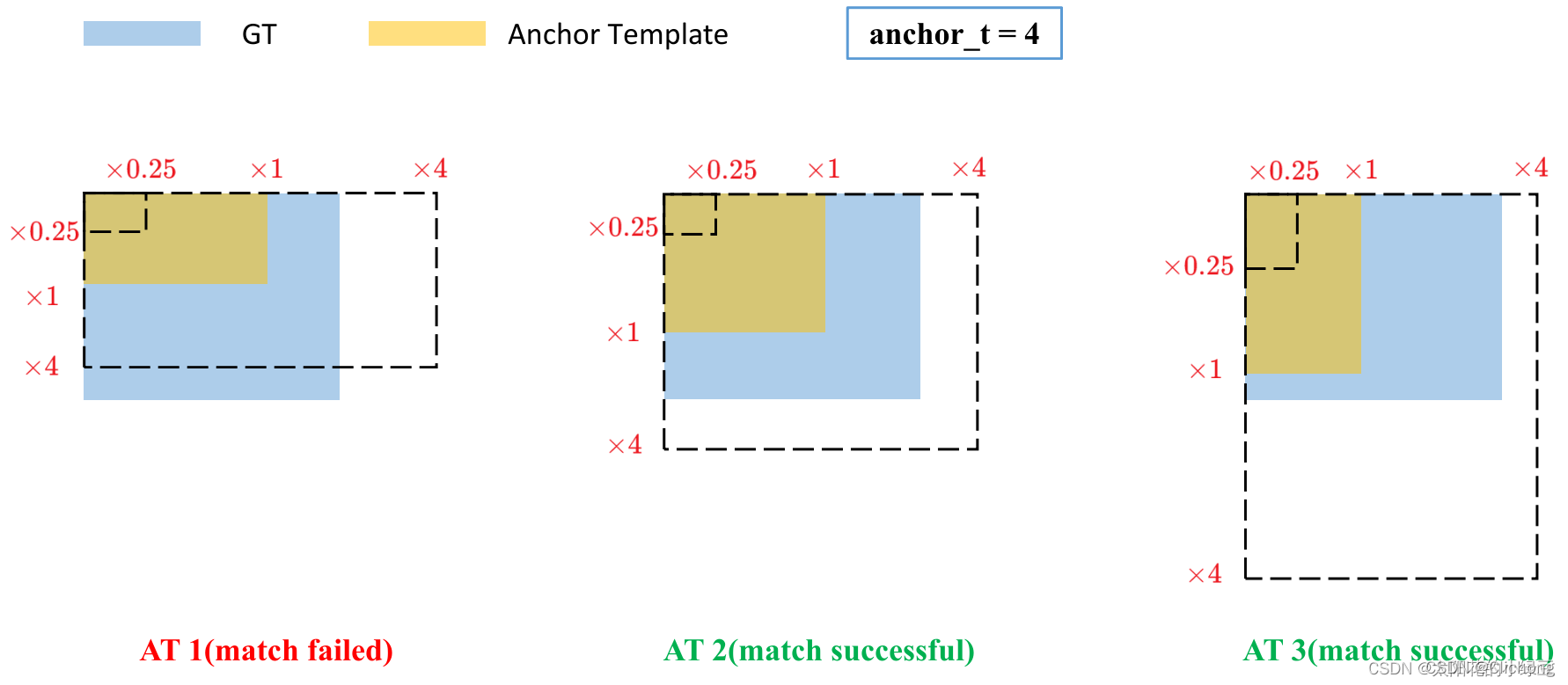
剩下的步骤和YOLOv4中一致: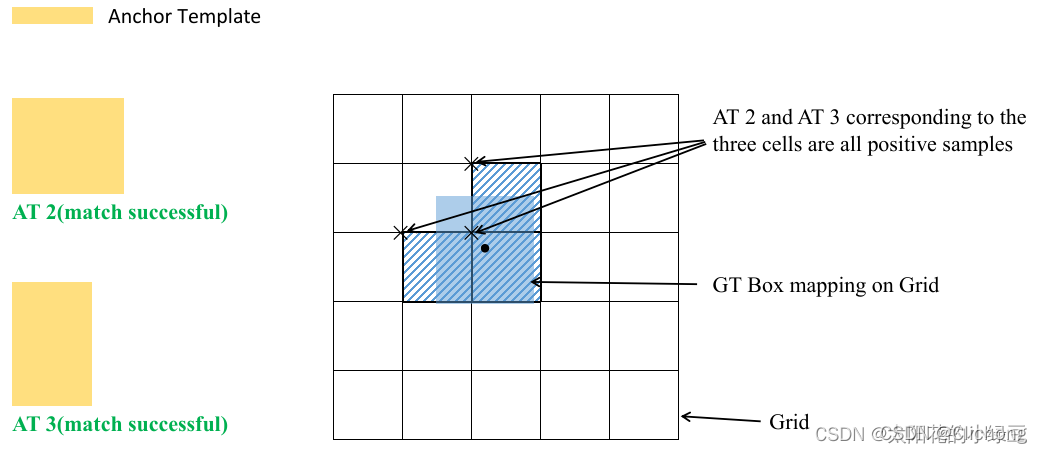
简要分析:
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了( − 0.5 , 1.5 ) (-0.5, 1.5)(−0.5,1.5),所以按理说只要Grid Cell左上角点距离GT中心点在( − 0.5 , 1.5 ) (−0.5,1.5)(−0.5,1.5)范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。
- 则这三个Cell对应的AT2和AT3都为正样本。
- Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展
参考资料:
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16772709.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号