经典重塑-yolov5网络结构的故事
目录
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。YOLOv5融合了数千小时研发过程中学到的经验教训和最佳实践。
官方文档:Quick Start - YOLOv5 Documentation (ultralytics.com)
代码仓库:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
网络模型及网络结构
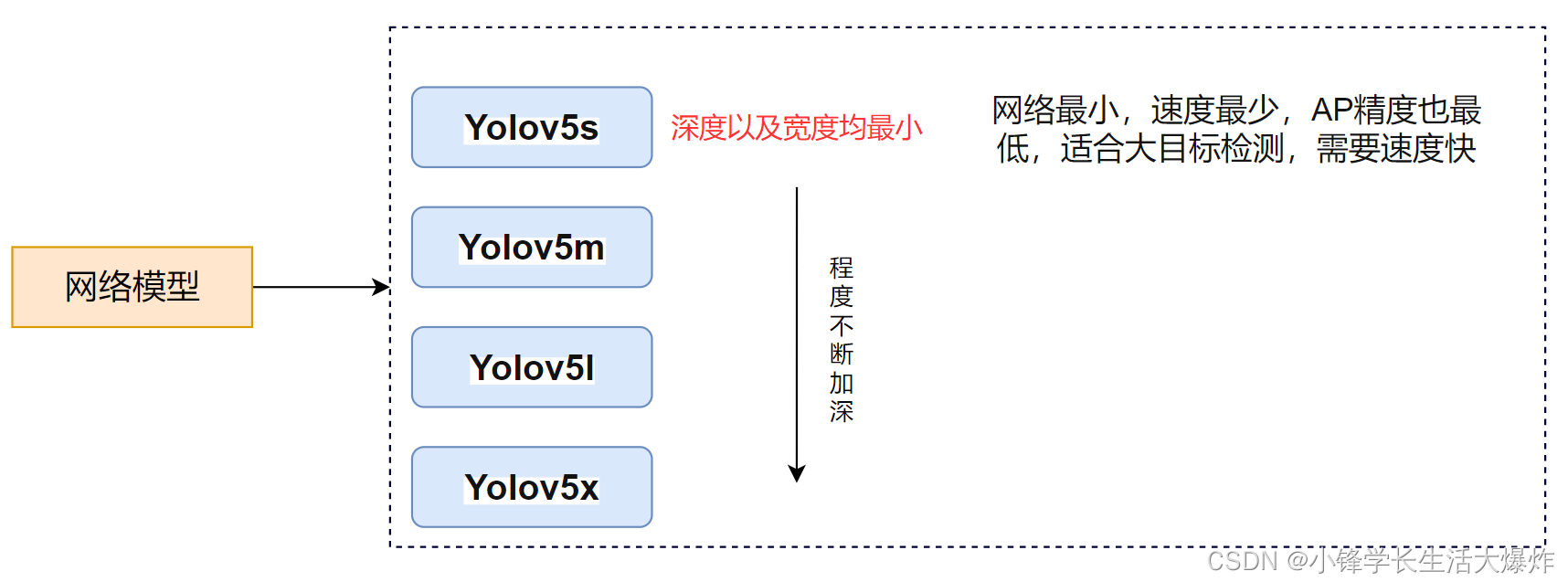

网络结构详情


代码的整体目录

代码detect.py测试

各个模块
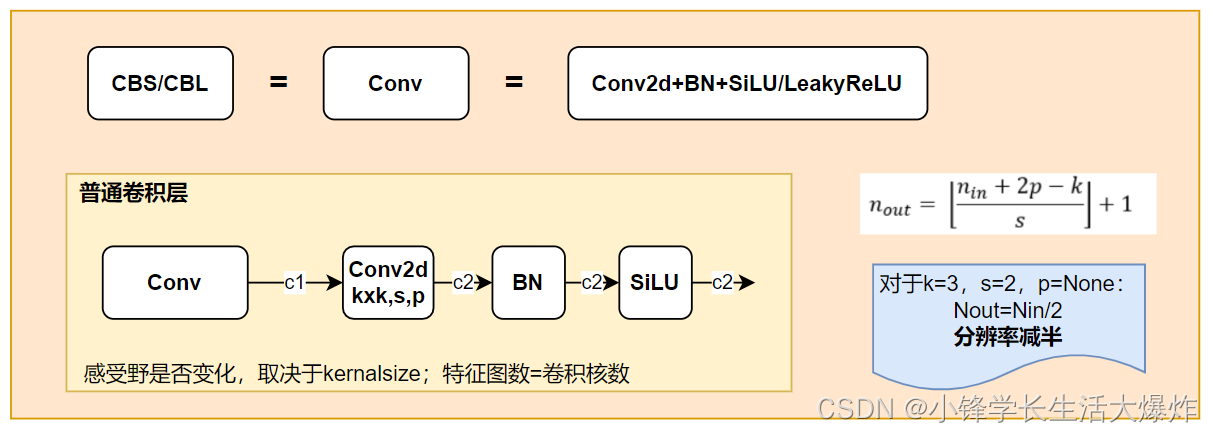
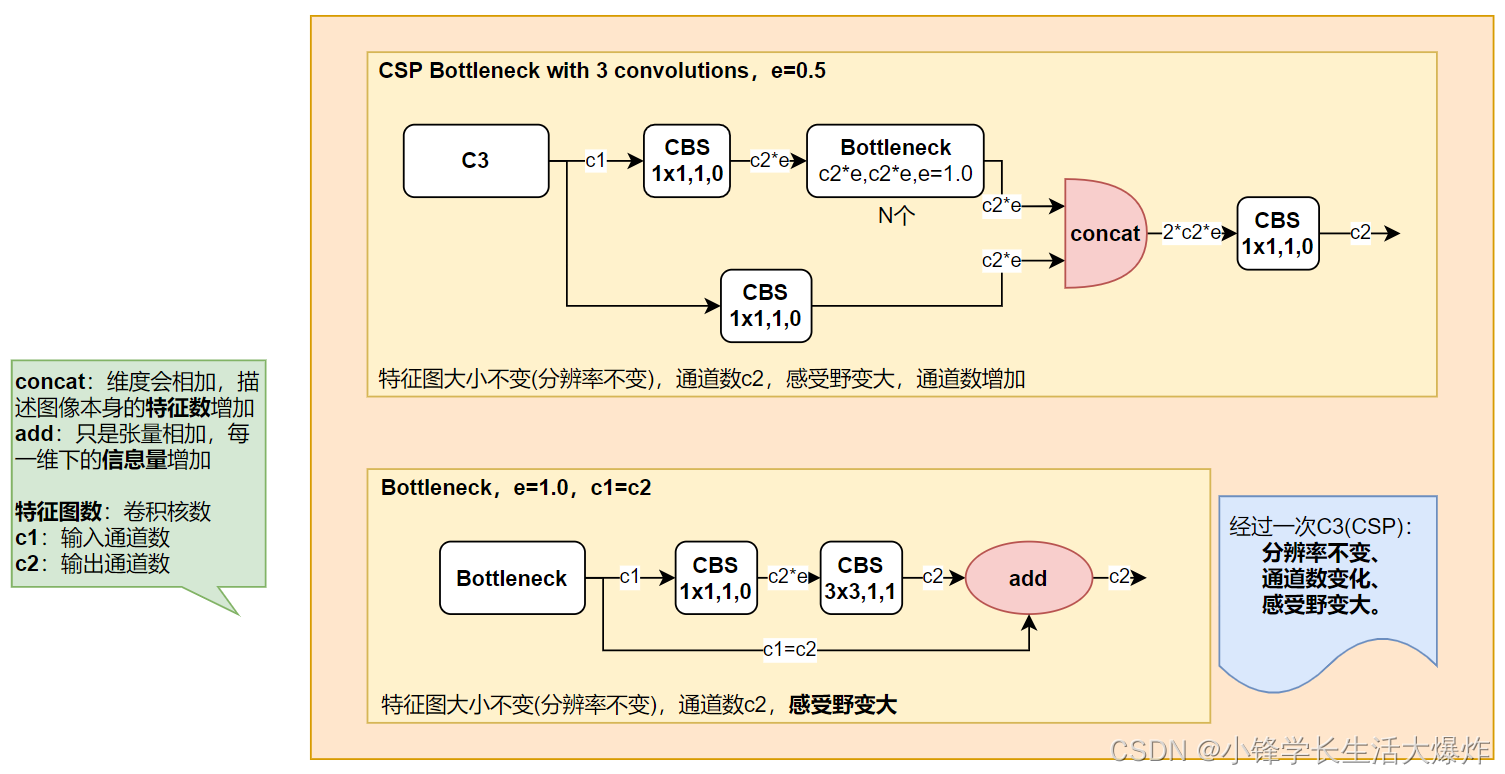
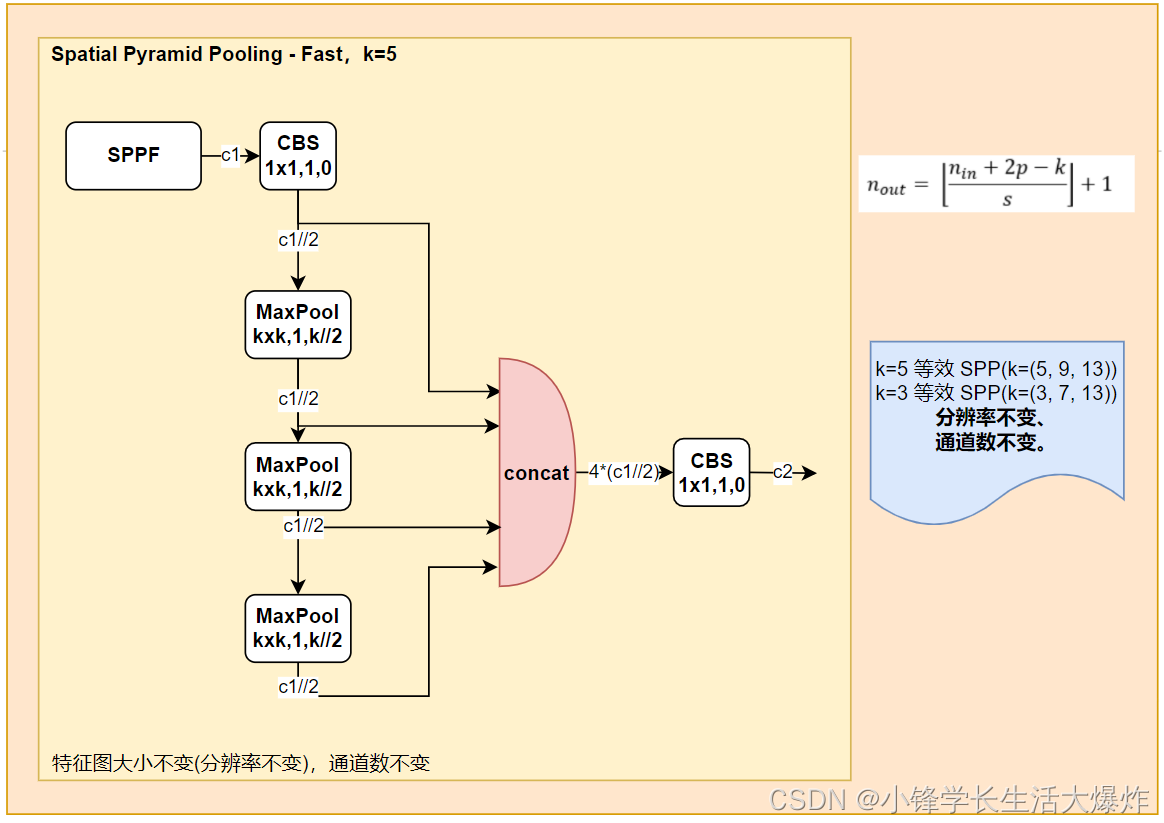
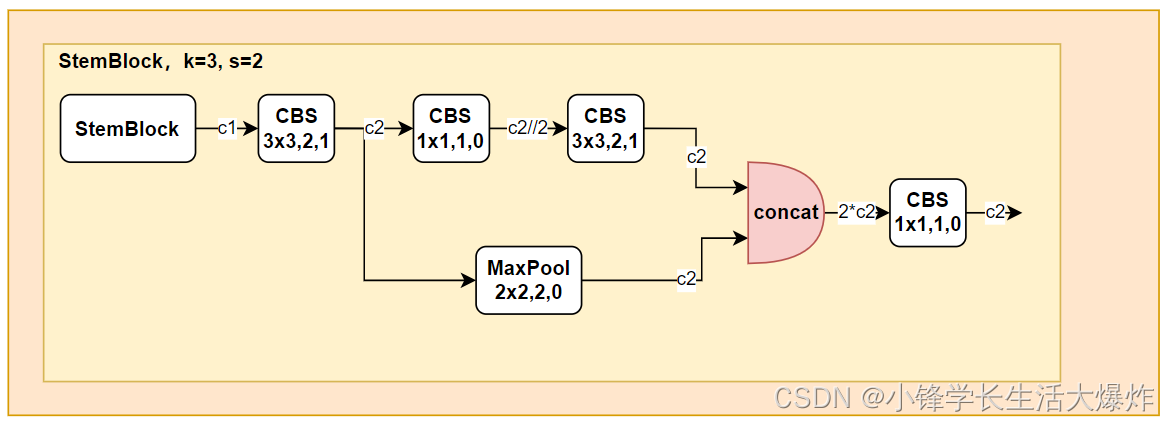
整体结构
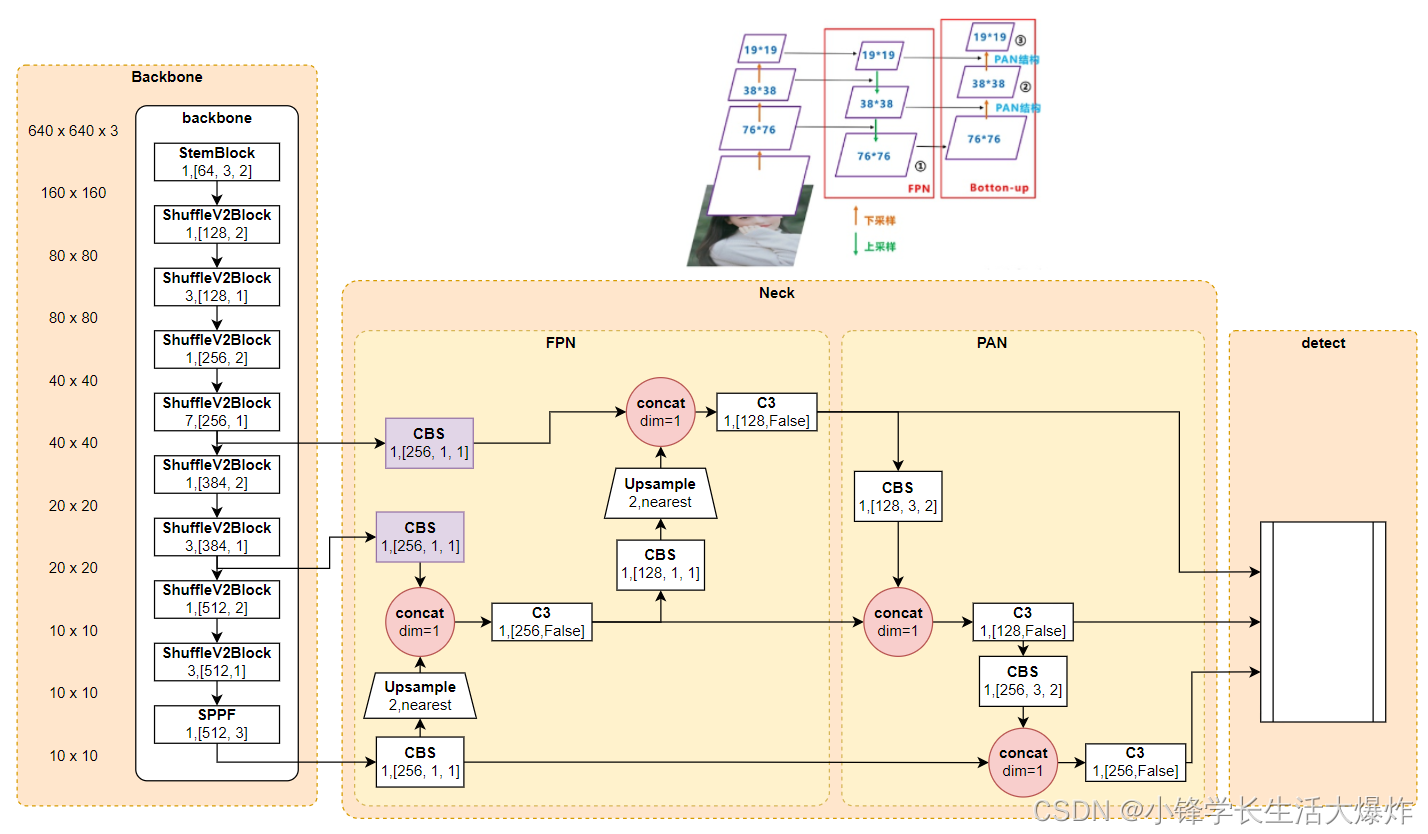
其他资料
来着江大白(官方一直在更新,图不一定准)和yolov5官方
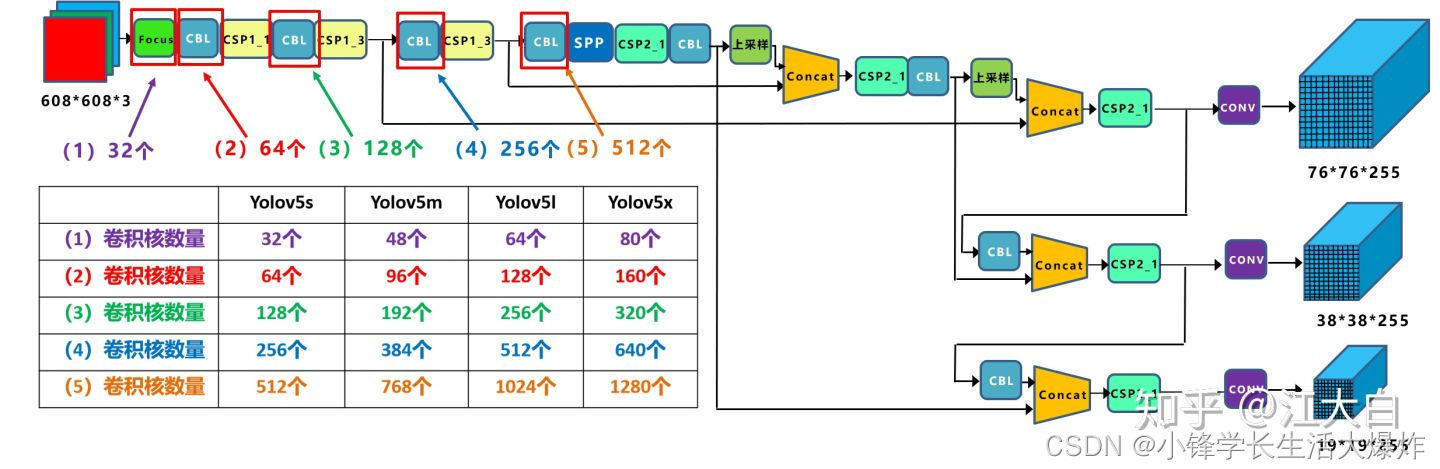
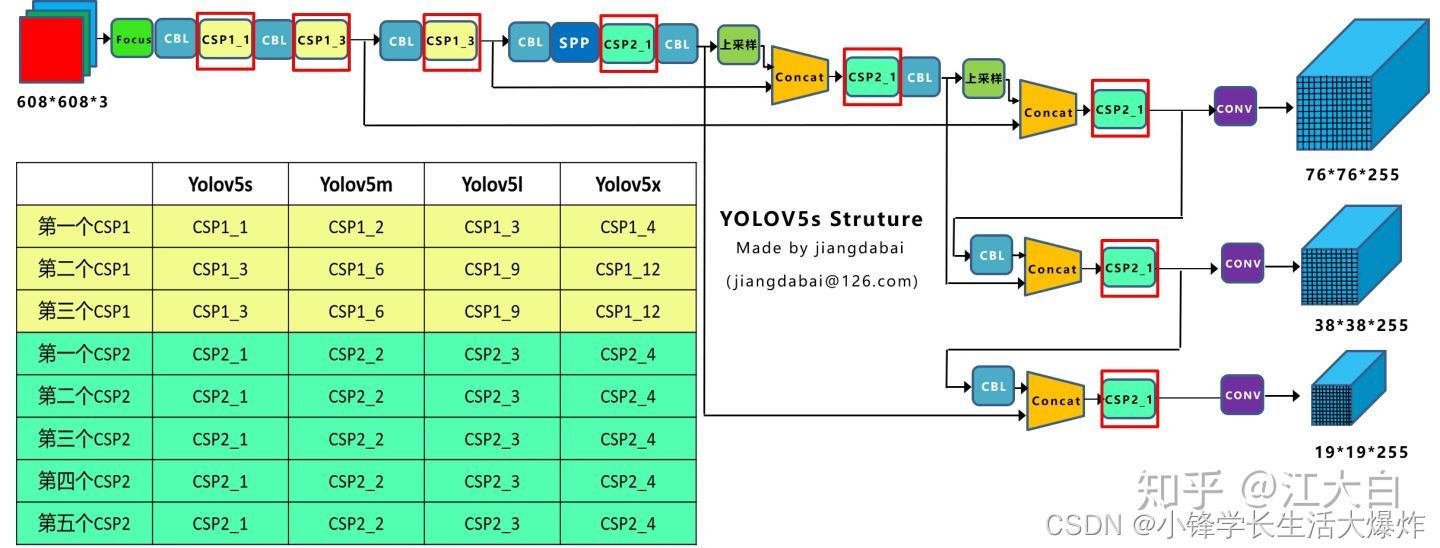
4种网络的宽度
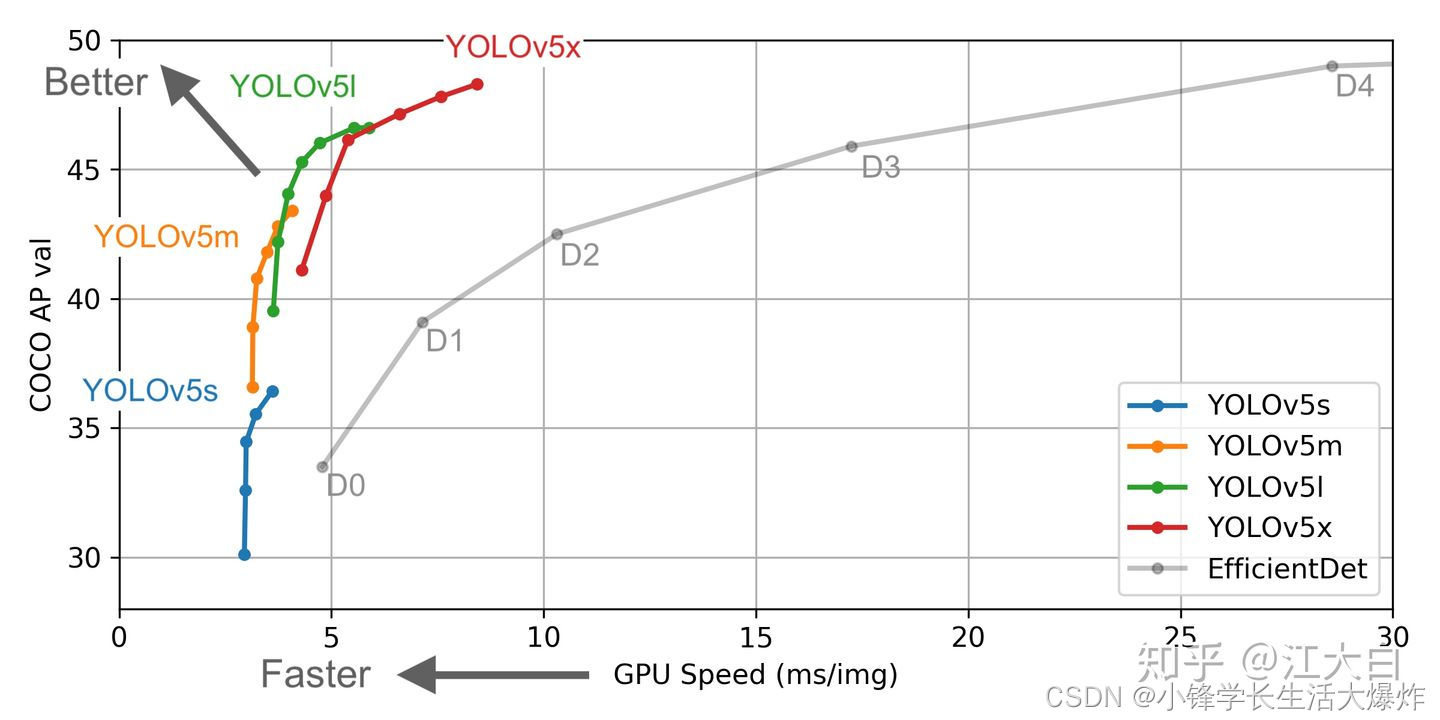
yolov5各个网络模型性能比较
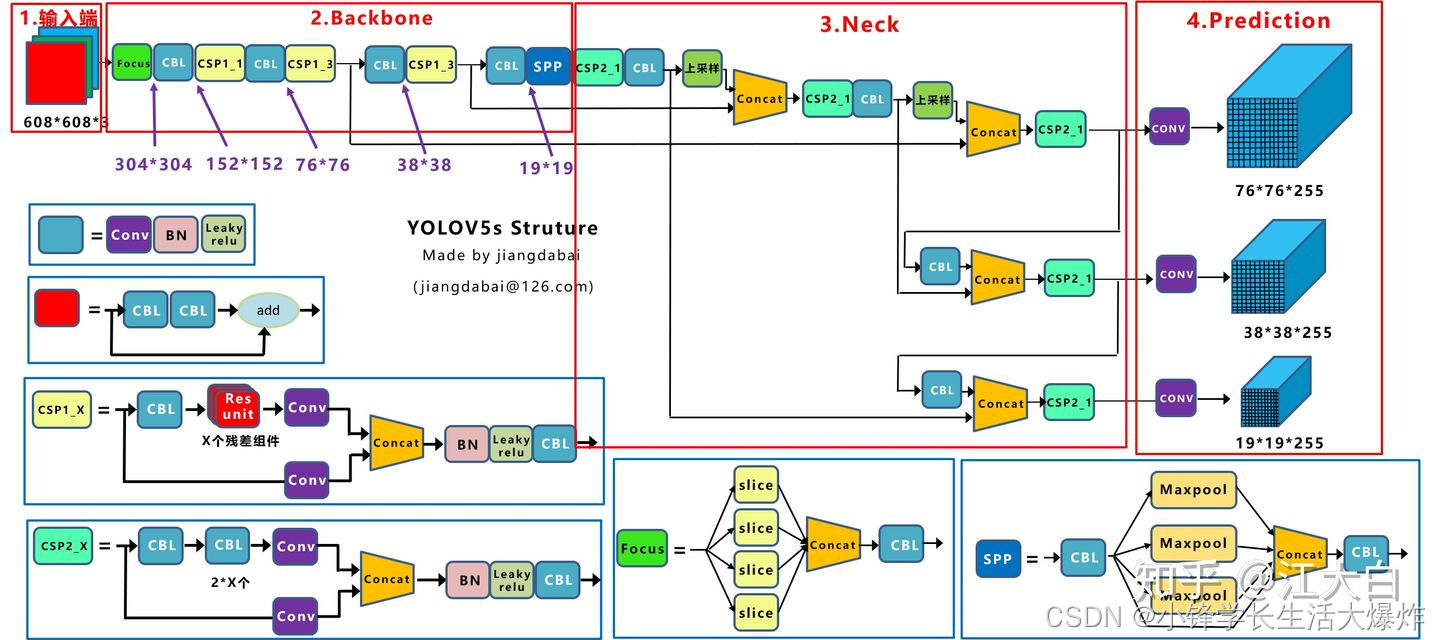
yolov5结构
yolov5四种网络的深度
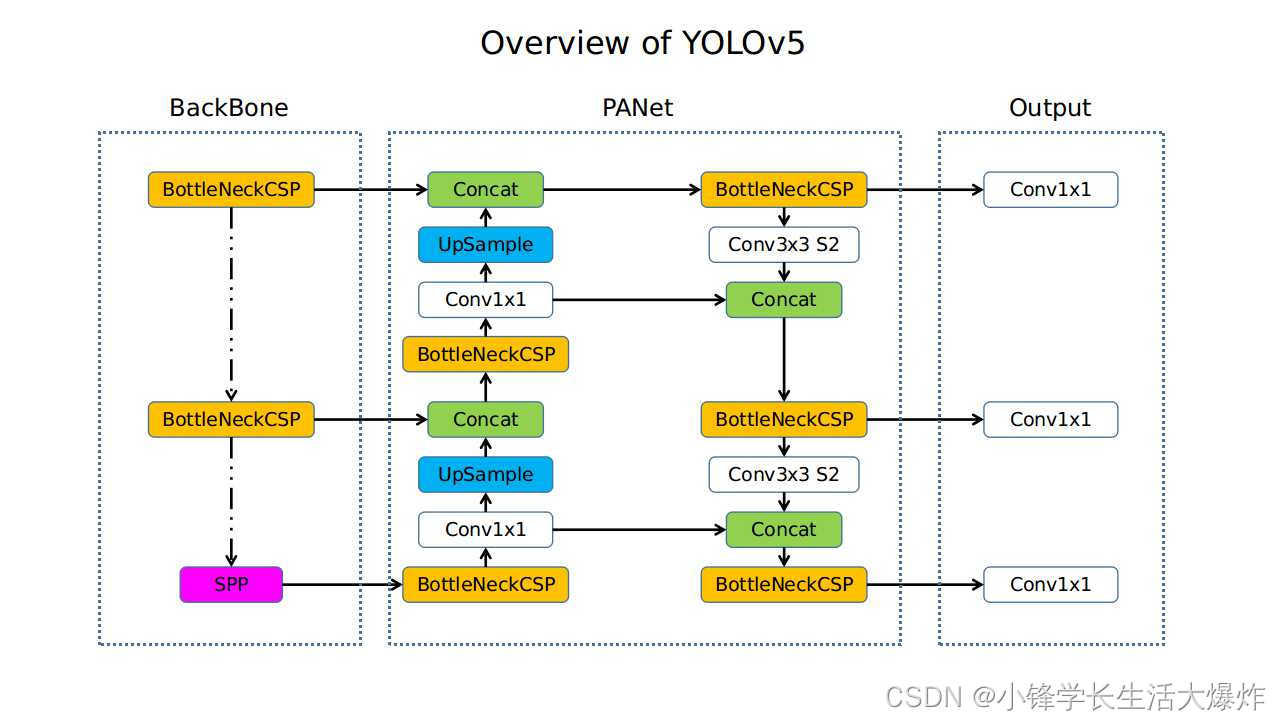
yolov5网络结构图
一些工具代码
voc2yolo.py
from os import getcwd import glob classes = ["face", "face_mask"] def convert(size, box): dw = 1.0 / size[0] dh = 1.0 / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_name): in_file = './val/xmls/' + image_name[:-3] + 'xml' # xml文件路径 out_file = open('./val/labels/' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径 with open(in_file) as f: try: import xml.etree.cElementTree as ET except ImportError: import xml.etree.ElementTree as ET tree = ET.parse(f) # <class 'xml.etree.ElementTree.ElementTree'> root = tree.getroot() # 获取根节点 <Element 'data' at 0x02BF6A80> # # xml_text = f.read() # root = ET.fromstring(xml_text) size = root.find('size') if size is not None: w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): cls = obj.find('name').text if cls not in classes: # print(cls) continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) if w != 0 and h != 0: bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() if __name__ == '__main__': for image_path in glob.glob("./val/images/*.jpg"): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径 image_name = image_path.split('\\')[-1] convert_annotation(image_name)
总结
YOLOv5(You Only Look Once)是由 UitralyticsLLC公司发布的一种单阶段目标检测算
法,YOLOv5 相比YOLOv4 而言,在检测平均精度降低不多的基础上,具有均值权重文件更
小,训练时间和推理速度更短的特点。YOLOv5 的网络结构分为输入端、BackboneNeck、
Head 四个部分。
输入端主要包括 Mosaic 数据增强、图片尺寸处理以及自适应锚框计算三部分。Mosaic
数据增强将四张图片进行组合,达到丰富图片背景的效果;图片尺寸处理对不同长宽的原始图
像自适应的添加最少的黑边,统一缩放为标准尺寸;自适应锚框计算在初始锚框的基础上,将
输出预测框与真实框进行比对,计算差距后再反向更新,不断迭代参数来获取最合适的锚框
值。
Backbone 主要包含了 BottleneckCSP和 Focus 模块。BottleneckCSP 模块在增
强整个卷积神经网络学习性能的同时大幅减少了计算量;Focus 模块对图片进行切片操作,将
输入通道扩充为原来的 4 倍,并经过一次卷积得到下采样特征图,在实现下采样的同时减少了
计算量并提升了速度。
Neck 中采用了 FPN 与 PAN 结合的结构,将常规的 FPN 层与自底向上的特征金字塔进行结
合,将所提取的语义特征与位置特征进行融合,同时将主干层与检测层进行特征融合,使模型
获取更加丰富的特征信息。
Head 输出一个向量,该向量具有目标对象的类别概率、对象得分和该对象边界框的位置。检
测网络由三层检测层组成,不同尺寸的特征图用于检测不同尺寸的目标对象。每个检测层输出
相应的向量,最后生成原图像中目标的预测边界框和类别并进行标记。
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16736871.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号