经典重塑-yolov3的正负样本选择和损失函数的故事
2022年09月27日09:38:07更新
yolov3的损失函数中,计算坐标的损失时,是使用预测值(未解码)和目标值(已编码)来计算损失,这一点很重要,因为很多博客上的讲解其实是反过来了;而iou损失,则是使用预测值(已解码)+目标值(未编码),详细的可以参考https://github.com/chentiao/PyTorch-YOLOv3/blob/802b81265383144b6e9fbd861f3c493c6afd11ae/pytorchyolo/utils/loss.py#L58中的具体实现
----------------------------------------------------------------------------------------------------------分割线------------------------------------------------------------------------------------------------------
先讲一下正负样本选择,因为必须要先选择正负样本才能计算损失,毕竟坐标误差,iou误差和分类误差都是和正样本相关的。
然后再来讲一下损失函数的计算方式
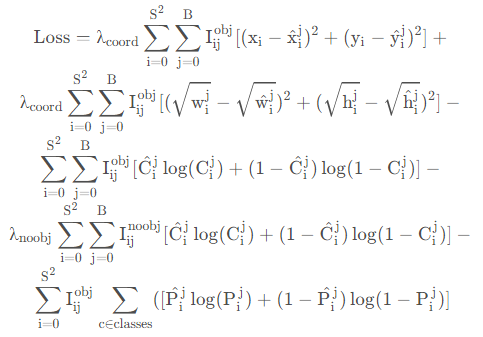

我个人理解上包括三个损失:坐标损失,就是计算输出中心点、高宽的损失,采用的均方差;还有一个是目标置信度损失,也就是框内存在目标的概率,这个采用的是二值交叉熵损失;还有一个是分类损失,也就是数据的类别
最大的变动是分类损失换成了二分交叉熵,这是由于yolov3中剔除了softmax改用logistic。
注意在计算iou并取其中最大值时,比较的是9个bounding box,并不是3个
loss需要对三个特征层进行处理,这里以最小的特征层为例
利用y_true取出该特征层中真实存在目标的点的位置(m,13,13,3,1)及其对应的种类(m,13,13,3,80)
将yolo_outputs的预测值输出进行处理,得到reshape后的预测值y_pre,shape分别为(m,13,13,3,85),(m,26,26,3,85),(m,52,52,3,85)。还有解码后的xy,wh
获取真实框编码后的值,后面用于计算loss,编码后的值其含义与y_pre相同,可用于计算loss
对于每一幅图,计算其中所有真实框与预测框的IOU,取出每个网络点中IOU最大的先验框,如果这个最大的IOU都小于ignore_thresh,则保留,一般来说ignore_thresh取0.5,该步的目的是为了平衡负样本
计算xy和wh上的loss,其计算的是实际上存在目标的,利用第三步真实框编码后的的结果和未处理的预测结果进行对比得到loss
计算置信度的loss,其有两部分构成,第一部分是实际上存在目标的,预测结果中置信度的值与1对比;第二部分是实际上不存在目标的,在第四步中得到其最大IOU的值与0对比
计算预测种类的loss,其计算的是实际上存在目标的,预测类与真实类的差距
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16726968.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号