经典重塑-yolov3的框编解码的故事
边框预测:
预测tx ty tw th
对tx和ty进行sigmoid,并加上对应的offset(下图Cx, Cy)
对th和tw进行exp,并乘以对应的锚点值
对tx,ty,th,tw乘以对应的步幅,即:416/13, 416 ⁄ 26, 416 ⁄ 52
最后,使用sigmoid对Objectness和Classes confidence进行sigmoid得到0~1的概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值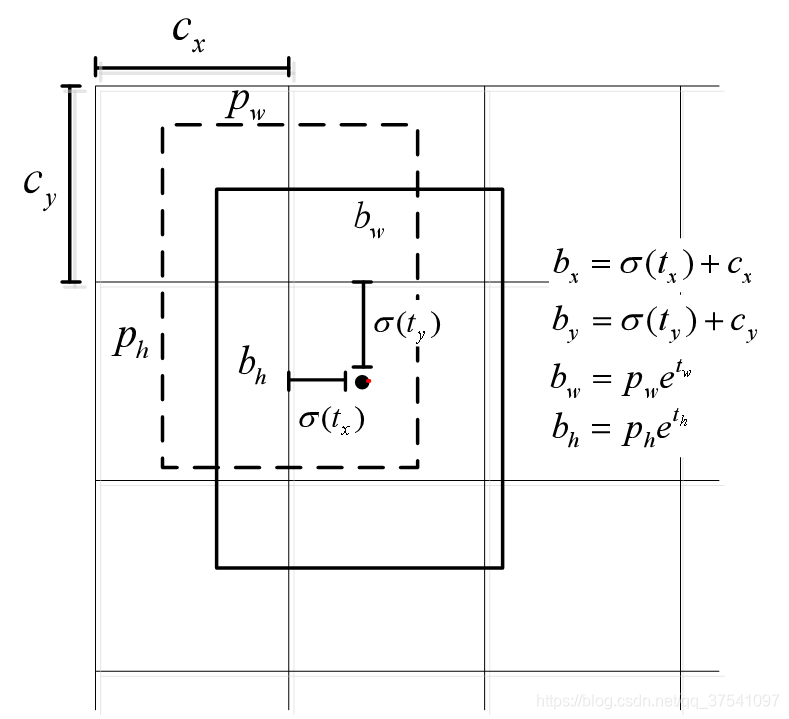
(tx,ty) :目标中心点相对于该点所在网格左上角的偏移量,经过sigmoid归一化。即值属于【0,1】。如图约(0.3 , 0.4)
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。如图(1,1)
(pw,ph):anchor box 的边长
(tw,th):预测边框的宽和高,这里使用e为底数一个是为了控制大于0,第二个是为了便于反向传播容易计算
PS:最终得到的边框坐标值是bx,by,bw,bh.而网络学习目标是tx,ty,tw,th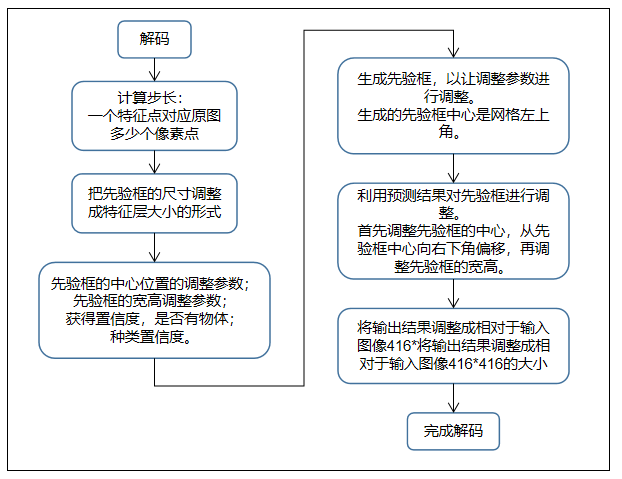
首先,yolov3要先build target,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的每个anchor与ground truth的IOU值,计算IOU值时不考虑坐标,只考虑形状(因为anchor没有坐标xy信息),所以先将anchor与ground truth的中心点都移动到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框anchor与ground truth匹配作为正样本参与训练,对应的预测框用来预测这个ground truth。那么正样本应该如何找?label中存放着[image,class,x(归一化),y,w(归一化),h],我们可以用这些坐标在对应13×13 Or 26×26 or 52×52的map中分别于9个anchor算出iou,找到符合要求的,把索引与位置记录好。用记录好的索引位置找到predict的anchor box。
xywh是由均方差来计算loss的,其中预测的xy进行sigmoid来与lable xy求差,label xy是grid cell中心点坐标,其值在0-1之间,所以predict出的xy要sigmoid。
分类用的多类别交叉熵,置信度用的二分类交叉熵。只有正样本才参与class,xywh的loss计算,负样本只参与置信度loss
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16725146.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号