长尾问题的在cv深度学习中的解决方案
本文方法,在LVIS challenge 2019比赛中获得第一名,整体ap比第二名高2.2个点,rare类别比第二名高7.1个点。在没有额外策略,仅使用本文方法的前提下,在rare类别上比baseline方法高4.1个点(加上各种策略后,再提升3.8个点)。
一、长尾问题的一般解决方案
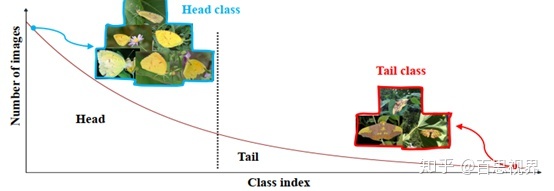
在实际的视觉相关任务中,数据都存在如上图所示的长尾分布,少量类别占据了绝大多少样本,如图中Head部分,大量的类别仅有少量的样本,如图中Tail部分。解决长尾问题的方案一般分为4种:
- Re-sampling:主要是在训练集上实现样本平衡,如对tail中的类别样本进行过采样,或者对head类别样本进行欠采样
- Re-weighting:主要在训练loss中,给不同的类别的loss设置不同的权重,对tail类别loss设置更大的权重
- Learning strategy:有专门为解决少样本问题涉及的学习方法可以借鉴,如:meta-learning、metric learning、transfer learing。另外,还可以调整训练策略,将训练过程分为两步:第一步不区分head样本和tail样本,对模型正常训练;第二步,设置小的学习率,对第一步的模型使用各种样本平衡的策略进行finetune。
- 综合使用以上策略
二、本文方案
本文介绍的方案属于第3种,来自论文“Equalization Loss for Long-Tailed Object Recognition”,出自商汤。下载链接:
Paper:https://arxiv.org/pdf/2003.05176.pdf
Code:https://github.com/tztztztztz/eql.detectron2
1,为什么说这个方案比较简洁呢?
- 出发点比较简单:减少梯度反向传播时对tail样本的惩罚
- 仅有1个超参需要人工调节。
- 可以嵌入到任何模型训练中
2,以检测任务为例,修改了检测任务中分类的loss:在交叉熵loss的基础上,增加了一个权重,如下式
其中wj计算方式如下:
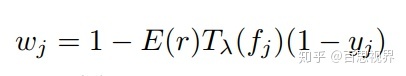
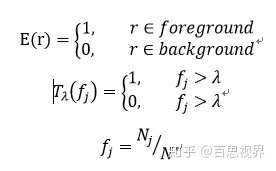
其中E(r)为二值,当r为前景类别时,为1,为背景类别时,为0。Tλ(fj)也为二值,当fj小于λ时为1,反之为0,λ为阈值,需要人工设定,fj为第j类样本的频率, Nj为第j类样本的图片数,N为训练集样本总数,yj为groundtruth。
3,结果
1)该方法在LVIS Challenge 2019比赛中,获得了第一名。
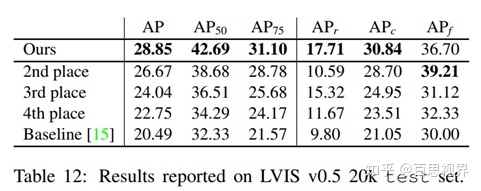
2)在没有其他balance策略的前提下,在LVIS v0.5的验证集上,应用在不同检测方法上,对检测结果有稳定3个点左右的涨幅。
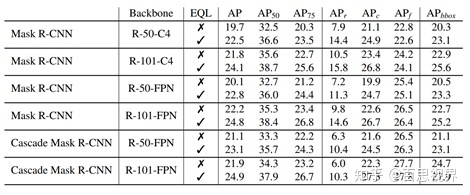
三、code
代码部分主要用来实现wj的计算即可,如下,增加了简单的注释:
def exclude_func(self):
# E(r)的实现
# instance-level weight
bg_ind = self.n_c
# 对背景类别置为0,非背景类别置为1
weight = (self.gt_classes != bg_ind).float()
weight = weight.view(self.n_i, 1).expand(self.n_i, self.n_c)
return weight
def threshold_func(self):
# T(x)实现
# class-level weight
weight = self.pred_class_logits.new_zeros(self.n_c)
# 对小于λ的置为1,其他为0
weight[self.freq_info < self.lambda_] = 1
weight = weight.view(1, self.n_c).expand(self.n_i, self.n_c)
return weight
def eql_loss(self):
# eql loss的实现
self.n_i, self.n_c = self.pred_class_logits.size()
def expand_label(pred, gt_classes):
target = pred.new_zeros(self.n_i, self.n_c + 1)
target[torch.arange(self.n_i), gt_classes] = 1
return target[:, :self.n_c]
target = expand_label(self.pred_class_logits, self.gt_classes)
# wj的实现
eql_w = 1 - self.exclude_func() * self.threshold_func() * (1 - target)
cls_loss = F.binary_cross_entropy_with_logits(self.pred_class_logits, target,
reduction='none')
return torch.sum(cls_loss * eql_w) / self.n_ifrom:https://zhuanlan.zhihu.com/p/127791648
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16542599.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号