一文读懂COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
当在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
COCO数据集的下载
官网地址:http://cocodataset.org/#download
1、2014年数据集的下载
train2014:http://images.cocodataset.org/zips/train2014.zip
val2014:http://images.cocodataset.org/zips/val2014.zip
http://msvocds.blob.core.windows.net/coco2014/train2014.zip
2、2017的数据集的下载
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
http://images.cocodataset.org/zips/test2017.zip
http://images.cocodataset.org/annotations/image_info_test2017.zip
| train2017 |
train2017:http://images.cocodataset.org/zips/train2017.zip |
| val2017 |
val2017:http://images.cocodataset.org/zips/val2017.zip |
| test2017 |
test2017:http://images.cocodataset.org/zips/test2017.zip |

COCO数据集概述
COCO的全称是Common Objects in Context,是微软团队提供的一个可以用来进行图像识别的数据集。MS COCO数据集中的图像分为训练、验证和测试集。其行业地位就不再多少了,本文主要梳理一下该数据集包含的内容。下图是官网给出的可下载的数据集(更新时间2020年01月09日),从这里可看出其数据集主要包括有标注的和无标注的数据:
- 2014:训练集 + 验证集 + 测试集
- 2015:测试集
- 2017:训练集 + 验证集 + 测试集
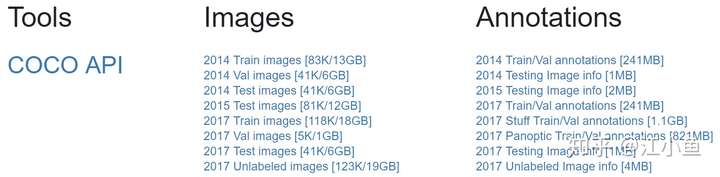
PK的内容包括:目标检测与实例分割、人体关键点检测、材料识别、全景分割、图像描述

目标检测/实例分割数据标注文件解析
以“2014 Train/Val annotations”标注文件为例,下图是下载下来后其包括的注释文件内容,包括三类文件:captions为图像描述的标注文件、instances为目标检测与实例分割的标注文件、person_keypoints为人体关键点检测的标注文件。建议下载下来后可以自行打开查看,因为注释文件比较大,因此建议用专业软件打开,速度快且不丢数据,例如:Dadroit Viewer软件是我所使用的。

其注释文件中的内容就是一个字典数据结构,包括以下5个key-value对。其中info、images、licenses三个key是三种类型标注文件共享的,最后的annotations和categories按照不同的任务有所不同,下面详细介绍一下每个key字段的含义。

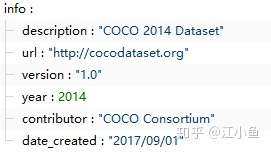
(一)info字段:包括下图中的内容,很好理解,这里就不赘述了。
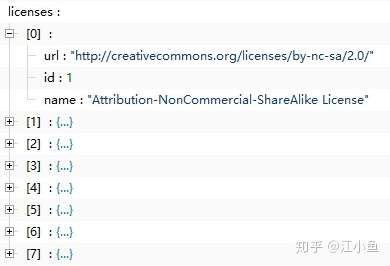
(二)licenses字段:包括下图中的内容,里面集合了不同类型的licenses,并在images中按照id号被引用,基本不参与到数据解析过程中。
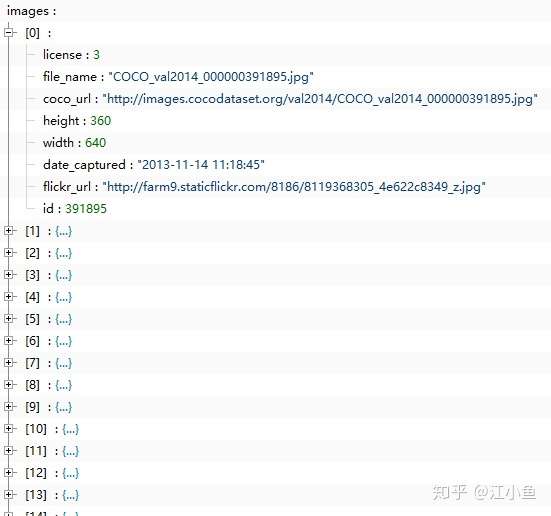
(三)images字段:包括下图中的内容,对应了每张图片的详细信息,其中的id号是被分配的唯一id
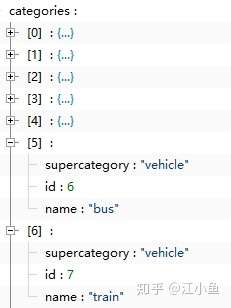
(四)categories字段:包括下图中的内容。其中supercategory是父类,name是子类,id是类别id(按照子类统计)。比如下图中所示的。coco数据集共计有80个类别(按照name计算的)
(五)annotations字段:包括下图中的内容,每个序号对应一个注释,一张图片上可能有多个注释。
- category_id:该注释的类别id;
- id:当前注释的id号
- image_id:该注释所在的图片id号
- area:区域面积
- bbox:目标的矩形标注框
- iscrowd:0或1。0表示标注的单个对象,此时segmentation使用polygon表示;1表示标注的是一组对象,此时segmentation使用RLE格式。
- segmentation:
- 若使用polygon标注时,则记录的是多边形的坐标点,连续两个数值表示一个点的坐标位置,因此此时点的数量为偶数
- 若使用RLE格式(Run Length Encoding(行程长度压缩算法))
RLE算法概述
将图像中目标区域的像素值设定为1,背景设定为0,则形成一个张二值图,该二值图可以使用z字形按照位置进行
编码,例如:0011110011100000……
但是这样的形式太复杂了,可以采用统计有多少个0和1的形式进行局部压缩,因此上面的RLE编码形式为:
2-0-4-1-2-0-3-1-5-0……(表示有2个0,4个1,2个0,3个1,5个0)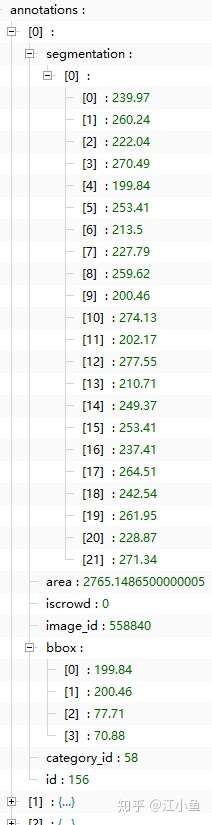
参考:
https://zhuanlan.zhihu.com/p/101984674
https://blog.csdn.net/u014297502/article/details/124846561
http://www.360doc.com/content/12/0121/07/77158047_997502625.shtml
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16351187.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号