目标检测中分析训练数据来进行anchor_ratio的设置
有关目标检测的更多tricks点击下面链接:
以cascade_rcnn_r50为例:默认参数是anchor_ratio=[0.5, 1.0, 2.0]
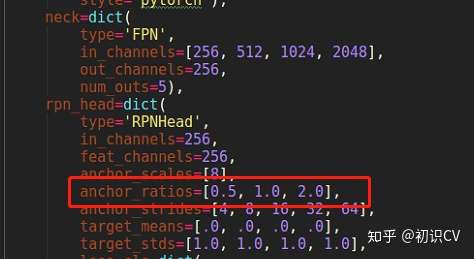 anchor_ratio默认参数
anchor_ratio默认参数
如何去修改这一部分参数呢?
这个参数的含义是长边和短边的比例,一般都是成对出现的(乘积为1),比如 。详细解析请自行查找anchor机制,本篇重点是对特定的数据集如何去选取anchor_ratio。
要想解决这一部分问题,首先要对你训练的数据进行可视化分析,可视化内容是所有种类的长边和短边的比例,代码如下:
# -*- coding: utf-8 -*-
# @Time : 20-2-13 下午5:03
# @Author : wusaifei
# @FileName: Vision_data.py
# @Software: PyCharm
import pandas as pd
import seaborn as sns
import numpy as np
import json
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family']='sans-serif'
plt.rcParams['figure.figsize'] = (10.0, 10.0)
# 读取数据
ann_json = 'instances_train2017.json'
with open(ann_json) as f:
ann=json.load(f)
#################################################################################################
#创建类别标签字典
category_dic=dict([(i['id'],i['name']) for i in ann['categories']])
counts_label=dict([(i['name'],0) for i in ann['categories']])
for i in ann['annotations']:
counts_label[category_dic[i['category_id']]]+=1
# 标注长宽高比例
box_w = []
box_h = []
box_wh = []
categorys_wh = [[] for j in range(10)]
for a in ann['annotations']:
if a['category_id'] != 0:
box_w.append(round(a['bbox'][2],2))
box_h.append(round(a['bbox'][3],2))
wh = round(a['bbox'][2]/a['bbox'][3],0)
if wh <1 :
wh = round(a['bbox'][3]/a['bbox'][2],0)
box_wh.append(wh)
categorys_wh[a['category_id']-1].append(wh)
# 所有标签的长宽高比例
box_wh_unique = list(set(box_wh))
box_wh_count=[box_wh.count(i) for i in box_wh_unique]
# 绘图
wh_df = pd.DataFrame(box_wh_count,index=box_wh_unique,columns=['宽高比数量'])
wh_df.plot(kind='bar',color="#55aacc")
plt.show()结果如下:
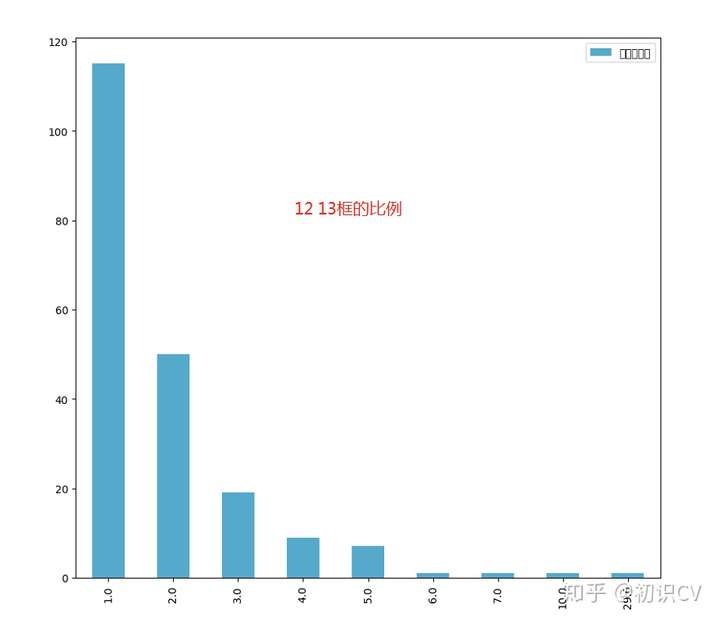
分析:
由上图中我们可知长边和短边的比例为:1.0、2.0、3.0、4.0、5.0、6.0、7.0、10.0、29.0,此时anchor_ratios可选择为anchor_ratios=[0.1, 0.2, 0.5, 1.0, 2.0, 5.0, 10]。
有人该问为什么不选择3.0、4.0、6.0、7.0、29.0呢?
选取时得保证一个原则:不能选择极端比例。意思就是,不是有什么比例就选择什么比例,而是用一个近似比例代替其他的比例。就好像3.0可以近似的看做2.0,4.0、6.0、7.0可以近似的看为5.0,29.0可以近似的看为10.0。
转载:https://zhuanlan.zhihu.com/p/108885033
本文来自博客园,作者:海_纳百川,转载请注明原文链接:https://www.cnblogs.com/chentiao/p/16335948.html,如有侵权联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号