MySQL总结
MySQL知识点汇总
[]包含的内容属于可选项 , | 任选其一
1. 常用命令
显示所有数据库:show databases;
进入指定的库:use 库名;
显示当前库中所有的表:show tables;
查看其他库中所有的表:show tables from 库名;
查看表的创建语句:show create table 表名;
查看表结构:desc 表名;
查看当前所在库:select database();
2. MySQL中数据类型介绍
2.1 SQL的语言分类
- DQL(Data Query Language):数据查询语言 select 相关语句
- DML(Data Manipulate Language):数据操作语言 insert 、update、delete 语句
- DDL(Data Define Languge):数据定义语言 create、drop、alter 语句
- TCL(Transaction Control Language):事务控制语言 set autocommit=0、start
transaction、savepoint、commit、rollback
2.2 整数类型
| 类型 | 字节数 | 有符号值范围 | 无符号值范围 |
|---|---|---|---|
| tinyint[(n)] [unsigned] | 1 | [- , -1] | [0, -1] |
| smallint[(n)] [unsigned] | 2 | [- , -1] | [0, -1] |
| mediumint[(n)] [unsigned] | 3 | [- , -1] | [0, -1] |
| int[(n)] [unsigned] | 4 | [- , -1] | [0, -1] |
2.3 浮点类型(容易懵,注意看)
| 类型 | 字节大小 | 范围(有符号) | 范围(无符号) | 用 途 |
|---|---|---|---|---|
| float[(m,d)] | 4 | (-3.402823466E+38,3.402823466351E+38) | [0,3.402823466E+38) | 单 精 度 浮 点 数 值 |
| double[(m,d)] | 8 | (-1.7976931348623157E+308,1.797693134 8623157E+308) | [0,1.797693134862315 7E+308) | 双 精 度 浮 点 数 值 |
| decimal[(m,d)] | 对DECIMAL(M,D) ,如 果M>D,为M+2否则为 D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小 数 |
2.4 日期类型
| 类型 | 字 节 大 小 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM DD | 日期 值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间 值或 持续 时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份 值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM DD HH:MM:SS | 混合 日期 和时 间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合 日期 和时 间 值, 时间 戳 |
2.5字符串类型
| 类型 | 范围 | 存储所需字 节 | 说明 |
|---|---|---|---|
| char(M) | [0,m],m的范围[0, -1] | m | 定产字符串 |
| varchar(M) | [0,m],m的范围[0, -1] | m | 0-65535 字节 |
| tinyblob | 0-255( -1)字节 | L+1 | 不超过 255 个字符的二进制字符 串 |
| blob | 0-65535( -1)字节 | L+2 | 二进制形式的长文本数据 |
| mediumblob | 0-16777215( -1)字节 | L+3 | 二进制形式的中等长度文本数据 |
| longblob | 0-4294967295( -1)字 节 | L+4 | 二进制形式的极大文本数据 |
| tinytext | 0-255( -1)字节 | L+1 | 短文本字符串 |
| text | 0-65535( -1)字节 | L+2 | 长文本数据 |
| mediumtext | 0-16777215( -1)字节 | L+3 | 中等长度文本数据 |
| longtext | 0-4294967295( -1)字 节 | L+4 | 极大文本数据 |
2.6 MySQL与Java中对应
| MySQL Type Name | Return value ofGetColumnClassName | Returned as Java Class |
|---|---|---|
| BIT(1) (new in MySQL-5.0) | BIT | java.lang.Boolean |
| BIT( > 1) (new in MySQL- 5.0) | BIT | byte[] |
| TINYINT | TINYINT | java.lang.Boolean if the configuration property tinyInt1isBit is set to true (the default) and the storage size is 1, or java.lang.Integer if not. |
| BOOL, BOOLEAN | TINYINT | See TINYINT, above as these are aliases forTINYINT(1), currently. |
| SMALLINT[(M)] [UNSIGNED] | SMALLINT [UNSIGNED] | java.lang.Integer (regardless if UNSIGNED or not) |
| MEDIUMINT[(M)] [UNSIGNED] | MEDIUMINT [UNSIGNED] | java.lang.Integer, if UNSIGNED java.lang.Long |
| INT,INTEGER[(M)] [UNSIGNED] | INTEGER [UNSIGNED] | java.lang.Integer , if UNSIGNED java.lang.Long |
| BIGINT[(M)] [UNSIGNED] | BIGINT [UNSIGNED] | java.lang.Long , if UNSIGNED java.math.BigInteger |
| FLOAT[(M,D)] | FLOAT | java.lang.Float |
| DOUBLE[(M,B)] | DOUBLE | java.lang.Double |
| DECIMAL[(M[,D])] | DECIMAL | java.math.BigDecimal |
| DATE | DATE | java.sql.Date |
| DATETIME | DATETIME | java.sql.Timestamp |
| TIMESTAMP[(M)] | TIMESTAMP | java.sql.Timestamp |
| TIME | TIME | java.sql.Time |
| YEAR[(2|4)] | YEAR | If yearIsDateType configuration property is set to false, then the returned object type is java.sql.Short . If set to true (the default) then an object of type java.sql.Date (with the date set to January 1st, at midnight). |
| CHAR(M) | CHAR | java.lang.String (unless the character set for the column is BINARY, then byte[] is returned. |
| VARCHAR(M) [BINARY] | VARCHAR | java.lang.String (unless the character set for the column is BINARY, then byte[] is returned. |
| BINARY(M) | BINARY | byte[] |
| VARBINARY(M) | VARBINARY | byte[] |
| TINYBLOB | TINYBLOB | byte[] |
| TINYTEXT | VARCHAR | java.lang.String |
| BLOB | BLOB | byte[] |
| MySQL Type Name | Return value ofGetColumnClassName | Returned as Java Class |
|---|---|---|
| TEXT | VARCHAR | java.lang.String |
| MEDIUMBLOB | MEDIUMBLOB | byte[] |
| MEDIUMTEXT | VARCHAR | java.lang.String |
| LONGBLOB | LONGBLOB | byte[] |
| LONGTEXT | VARCHAR | java.lang.String |
| ENUM('value1','value2',...) | CHAR | java.lang.String |
| SET('value1','value2',...) | CHAR | java.lang.String |
2.7 数据类型选择的一些建议
- 选小不选大:一般情况下选择可以正确存储数据的最小数据类型,越小的数据类型通常更快,占用
磁盘,内存和CPU缓存更小。 - 简单就好:简单的数据类型的操作通常需要更少的CPU周期,例如:整型比字符操作代价要小得
多,因为字符集和校对规则(排序规则)使字符比整型比较更加复杂。 - 尽量避免NULL:尽量制定列为NOT NULL,除非真的需要NULL类型的值,有NULL的列值会使得
索引、索引统计和值比较更加复杂。 - 浮点类型的建议统一选择decimal
- 记录时间的建议使用int或者bigint类型,将时间转换为时间戳格式,如将时间转换为秒、毫秒,
进行存储,方便走索引
3. DDL常见操作汇总
3.1 库的管理
创建库 : create database [if not exists] 库名;
删除库 : drop databases [if exists] 库名;
**建库通用的写法 **
drop database if exists 旧库名;
create database 新库名;
3.2 表管理
创建表
create table 表名(
字段名1 类型[(宽度)] [约束条件] [comment '字段说明'],
字段名2 类型[(宽度)] [约束条件] [comment '字段说明'],
字段名3 类型[(宽度)] [约束条件] [comment '字段说明']
)[表的一些设置];
**注意: **
- 在同一张表中,字段名不能相同
- 宽度和约束条件为可选参数,字段名和类型是必须的
- 最后一个字段后不能加逗号
- 类型是用来限制 字段 必须以何种数据类型来存储记录
- 类型其实也是对字段的约束(约束字段下的记录必须为XX类型)
- 类型后写的 约束条件 是在类型之外的 额外添加的约束
约束说明 primary key:
not null:标识该字段不能为空
mysql> create table test1(a int not null comment '字段a');
default value:为该字段设置默认值,默认值为value
mysql> create table test2(
-> a int not null comment '字段a',
-> b int not null default 0 comment '字段b'
-> );
**primary key **
标识该字段为该表的主键,可以唯一的标识记录,插入重复的会报错两种写法,如下:
方式1:跟在列后,如下:
mysql> create table test3(
-> a int not null comment '字段a' primary key
-> );
方式2:在所有列定义之后定义,如下:
mysql> create table test4(
-> a int not null comment '字段a',
-> b int not null default 0 comment '字段b',
-> primary key(a)
-> );
方式2支持多字段作为主键,多个之间用逗号隔开,语法:primary key(字段1,字段2,字段n),示例 :
mysql> create table test7(
-> a int not null comment '字段a',
-> b int not null comment '字段b',
-> PRIMARY KEY (a,b)
-> );
foreign key:为表中的字段设置外键
语法:foreign key(当前表的列名) references 引用的外键表(外键表中字段名称)
mysql> create table test6(
-> b int not null comment '字段b',
-> ts5_a int not null,
-> foreign key(ts5_a) references test5(a)
-> );
注意几点:
- 两张表中需要建立外键关系的字段类型需要一致
- 要设置外键的字段不能为主键
- 被引用的字段需要为主键
- 被插入的值在外键表必须存在,如上面向test6中插入ts5_a为2的时候报错了,原因:2的值
在test5表中不存在
3.2 表操作
**删除表 **
drop table [if exists] 表名;
**修改表名 **
alter table 表名 rename [to] 新表名;
**表设置备注 **
alter table 表名 comment '备注信息';
**复制表 **
只复制表结构
create table 表名 like 被复制的表名;
复制表结构+数据
create table 表名 [as] select 字段,... from 被复制的表 [where 条件];
3.3 表中列的管理
**添加列 **
alter table 表名 add column 列名 类型 [列约束];
**修改列 **
alter table 表名 modify column 列名 新类型 [约束];
或者
alter table 表名 change column 列名 新列名 新类型 [约束];
**2种方式区别:modify不能修改列名,change可以修改列名 **
**删除列 **
alter table 表名 drop column 列名;
4. DML常见操作
DML(Data Manipulation Language)数据操作语言,以INSERT、UPDATE、DELETE三种指令为核心,
分别代表插入、更新与删除,是必须要掌握的指令,DML和SQL中的select熟称CRUD(增删改查)。
4.1插入操作
插入单行2种方式 其一
insert into 表名[(字段,字段)] values (值,值);
说明:
值和字段需要一一对应
如果是字符型或日期类型,值需要用单引号引起来;如果是数值类型,不需要用单引号
字段和值的个数必须一致,位置对应
字段如果不能为空,则必须插入值
可以为空的字段可以不用插入值,但需要注意:字段和值都不写;或字段写上,值用null代替
表名后面的字段可以省略不写,此时表示所有字段,顺序和表中字段顺序一致
**方式2 **(推荐用1)
insert into 表名 set 字段 = 值,字段 = 值;
**批量插入2种方式 其一 **
insert into 表名 [(字段,字段)] values (值,值),(值,值),(值,值);
方式二
insert into 表 [(字段,字段)]
数据来源select语句;
说明:
数据来源select语句可以有很多种写法,需要注意:select返回的结果和插入数据的字段数量、顺
序、类型需要一致
4.2 数据更新
单表更新
update 表名 [[as] 别名] set [别名.]字段 = 值,[别名.]字段 = 值 [where条件];
有些表名可能名称比较长,为了方便操作,可以给这个表名起个简单的别名,更方便操作一些。 如果无别名的时候,表名就是别名。
**多表更新 **
多表更新
update 表1 [[as] 别名1],表名2 [[as] 别名2]
set [别名.]字段 = 值,[别名.]字段 = 值
[where条件]
**建议采用单表方式更新,方便维护。 **
4.5 删除数据操作
**使用delete删除 **(常用)
delete [别名] from 表名 [[as] 别名] [where条件];
注意:
如果无别名的时候,表名就是别名
如果有别名,delete后面必须写别名
如果没有别名,delete后面的别名可以省略不写。
-- 删除test1表所有记录
delete from test1;
-- 删除test1表所有记录
delete test1 from test1;
-- 有别名的方式,删除test1表所有记录
delete t1 from test1 t1;
-- 有别名的方式删除满足条件的记录
delete t1 from test1 t1 where t1.a>100;
**多表删除 **
可以同时删除多个表中的记录,语法如下 :
delete [别名1,别名2] from 表1 [[as] 别名1],表2 [[as] 别名2] [where条件];
说明:
别名可以省略不写,但是需要在delete后面跟上表名,多个表名之间用逗号隔开。
#### 4.6 使用truncate删除
使用truncate删除
drop,truncate,delete区别
- drop (删除表):删除内容和定义,释放空间,简单来说就是把整个表去掉,以后要新增数据是不
可能的,除非新增一个表。
drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index),依赖
于该表的存储过程/函数将被保留,但其状态会变为:invalid。
如果要删除表定义及其数据,请使用 drop table 语句。 - truncate (清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构),与drop不同
的是,只是清空表数据而已。
注意:truncate不能删除具体行数据,要删就要把整个表清空了 - delete (删除表中的数据):delete 语句用于删除表中的行。delete语句执行删除的过程是每次从表
中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存,以便进行进行回滚操作。
truncate与不带where的delete :只删除数据,而不删除表的结构(定义)
truncate table 删除表中的所有行,但表结构及其列、约束、索引等保持不变。
对于由foreign key约束引用的表,不能使用truncate table ,而应使用不带where子句的delete语
句。由于truncate table 记录在日志中,所以它不能激活触发器。
delete语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生
效;如果有相应的 trigger,执行的时候将被触发。
truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,
不能回滚,操作不触发 trigger。
如果有自增列,truncate方式删除之后,自增列的值会被初始化,delete方式要分情况(如果数
据库被重启了,自增列值也会被初始化,数据库未被重启,则不变) - 如果要删除表定义及其数据,请使用 drop table 语句
- 安全性:小心使用 drop 和 truncate,尤其没有备份的时候,否则哭都来不及
- 删除速度,一般来说: drop> truncate > delete
| drop | truncate | delete | |
|---|---|---|---|
| 条件删除 | 不支持 | 不支持 | 支持 |
| 删除表结构 | 支持 | 不支持 | 不支持 |
| 事务的方式删除 | 不支持 | 不支持 | 支持 |
| 触发触发器 | 否 | 否 | 是 |
5. select查基础篇
DQL(Data QueryLanguage):数据查询语言,通俗点讲就是从数据库获取数据的,按照DQL的语法给
数据库发送一条指令,数据库将按需求返回数据 .
5. 1基本语法
select 查询的列 from 表名;
注意:
select语句中不区分大小写,SELECT和select、FROM和from效果一样。
查询的结果放在一个表格中,表格的第1行称为列头,第2行开始是数据,类属于一个二维数组。
**查询常量 **
select 常量值1,常量值2,常量值3;
**查询表达式 **
select 表达式;
**查询函数 **
select 函数;
**查询指定的字段 **
select 字段1,字段2,字段3 from 表名;
**查询所有列 **
select * from 表名
说明:
*表示返回表中所有字段。
5.2 列别名
在创建数据表时,一般都会使用英文单词或英文单词缩写来设置字段名,在查询时列名都会以英文的形式显示,这样会给用户查看数据带来不便,这种情况可以使用别名来代替英文列名,增强阅读性。
语法:
select 列 [as] 别名 from 表;
使用双引号创建别别名
mysql> select a "列1",b "列2" from test1;
使用单引号创建别别名
select a '列1',b '列2' from test1;
不用引号创建别名 :
select a 列1,b 列2 from test1;
**使用as创建别名: **
select a as 列1,b as '列 2' from test1;
select a as 列1,b as '列 2' from test1;
5.3 表别名
select 别名.字段,别名.* from 表名 [as] 别名;
总结
建议别名前面跟上as关键字
查询数据的时候,避免使用select *,建议需要什么字段写什么字段
6. select条件查询
select 列名 from 表名 where 列 运算符 值
说明:
注意关键字where,where后面跟上一个或者多个条件,条件是对前面数据的过滤,只有满足
where后面条件的数据才会被返回。
6.1 条件查询运算符
| 操作符 | 描述 |
|---|---|
| = | 等于 |
| <> 或者 != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
6.2 逻辑查询运算符
当我们需要使用多个条件进行查询的时候,需要使用逻辑查询运算符。
| 逻辑运算符 | 描述 |
|---|---|
| AND | 多个条件都成立 |
| OR | 多个条件中满足一个 |
**AND(并且) **
select 列名 from 表名 where 条件1 and 条件2;
表示返回满足条件1和条件2的记录
**OR(或者) **
select 列名 from 表名 where 条件1 or 条件2;
满足条件1或者满足条件2的记录都会被返回
6.3 like(模糊查询)
select 列名 from 表名 where 列 like pattern;
pattern中可以包含通配符,有以下通配符:
%:表示匹配任意一个或多个字符
_:表示匹配任意一个字符。
示例
mysql> select * from stu a where a.name like '张%';
6.4 BETWEEN AND(区间查询)
操作符 BETWEEN ... AND 会选取介于两个值之间的数据范围,这些值可以是数值、文本或者日期,属
于一个闭区间查询.
selec 列名 from 表名 where 列名 between 值1 and 值2;
返回对应的列的值在[值1,值2]区间中的记录
使用between and可以提高语句的简洁度两个临界值不要调换位置,只能是大于等于左边的值,并且小于等于右边的值。
6.5 IN查询
select 列名 from 表名 where 字段 in (值1,值2,值3,值4);
in 后面括号中可以包含多个值,对应记录的字段满足in中任意一个都会被返回
in列表的值类型必须一致或兼容
in列表中不支持通配符
6.6 NOT IN查询
select 列名 from 表名 where 字段 not in (值1,值2,值3,值4);
NULL存在的坑
查询运算符、like、between and、in、not in对NULL值查询不起效
6.7 IS NULL/IS NOT NULL(NULL值专用查询)
**IS NULL(返回值为空的记录) **
select 列名 from 表名 where 列 is null;
查询指定的列的值为NULL的记录。
**IS NOT NULL(返回值不为空的记录) **
select 列名 from 表名 where 列 is not null;
6.8 总结
- like中的%可以匹配一个到多个任意的字符,_可以匹配任意一个字符
- 空值查询需要使用IS NULL或者IS NOT NULL,其他查询运算符对NULL值无效
- 建议创建表的时候,尽量设置表的字段不能为空,给字段设置一个默认值
- <=>(安全等于)玩玩可以,建议少使用
7.排序和分页(order by 、limit)
7.1 排序查询(order by)
select 字段名 from 表名 order by 字段1 [asc|desc],字段2 [asc|desc];
需要排序的字段跟在 order by 之后;
asc|desc表示排序的规则,asc:升序,desc:降序,默认为asc;
支持多个字段进行排序,多字段排序之间用逗号隔开
7.2 按函数排序
示例: 方式一(第一种是在order by中使用了函数 )
SELECT id 编号,birth 出生日期,year(birth) 出生年份,name 姓名 from student
ORDER BY year(birth) asc,id asc;
方式二:(第一种是在order by中使用了函数 )
SELECT id 编号,birth 出生日期,year(birth) 出生年份,name 姓名 from student
ORDER BY 出生年份 asc,id asc;
7.3 limit介绍
limit用来限制select查询返回的行数,常用于分页等操作。
select 列 from 表 limit [offset,] count;
说明:
offset:表示偏移量,通俗点讲就是跳过多少行,offset可以省略,默认为0,表示跳过0行;范
围:[0,+∞)。count:跳过offset行之后开始取数据,取count行记录;范围:[0,+∞)。
limit中offset和count的值不能用表达式。
**获取前n行记录 **
select 列 from 表 limit 0,n;
或者
select 列 from 表 limit n;
7.4 分页查询
分页我们经常使用,分页一般有2个参数:
page:表示第几页,从1开始,范围[1,+∞)
pageSize:每页显示多少条记录,范围[1,+∞)
如:page = 2,pageSize = 10,表示获取第2页10条数据。
limit 实现分页
select 列 from 表名 limit (page - 1) * pageSize,pageSize;
示例
/*查询第1页2条数据*/
mysql> select a.id 订单编号,a.price 订单金额 from t_order a order by a.price desc
limit 0,2;
/*查询第2页2条数据*/
mysql> select a.id 订单编号,a.price 订单金额 from t_order a order by a.price desc
limit 2,2;
7.5 避免踩坑
limit中不能使用表达式
limit后面只能够跟明确的数字。
limit后面的2个数字不能为负数
7.6 总结
排序中存在相同的值时,需要再指定一个排序规则,通过这种排序规则不存在二义性
order by ... [asc|desc]用于对查询结果排序,asc:升序,desc:降序,asc|desc可以省略,默认为asc
limit用来限制查询结果返回的行数,有2个参数(offset,count),offset:表示跳过多少行,
count:表示跳过offset行之后取count行
limit中offset可以省略,默认值为0
limit中offset 和 count都必须大于等于0
limit中offset和count的值不能用表达式
分页排序时,排序不要有二义性,二义性情况下可能会导致分页结果乱序,可以在后面追加一个主键排序
8. 分组查询(group by、having)
语法
SELECT column, group_function,... FROM table
[WHERE condition]
GROUP BY group_by_expression
[HAVING group_condition];
说明:
group_function:聚合函数。
group_by_expression:分组表达式,多个之间用逗号隔开。
group_condition:分组之后对数据进行过滤。
分组中,select后面只能有两种类型的列:
出现在group by后的列
或者使用聚合函数的列
8.1 聚合函数
| 函数名称 | 作用 |
|---|---|
| max | 查询指定列的最大值 |
| min | 查询指定列的最小值 |
| count | 统计查询结果的行数 |
| sum | 求和,返回指定列的总和 |
| avg | 求平均值,返回指定列数据的平均值 |
分组时,可以使用使用上面的聚合函数。
示例
mysql> SELECT
user_id 用户id, the_year 年份, COUNT(id) 下单数量
FROM
t_order
GROUP BY user_id , the_year;
8.2 分组前筛选数据
分组前筛选数据
需求:需要查询2018年每个用户下单数量,输出:用户id、下单数量,如下:
mysql> SELECT
user_id 用户id, COUNT(id) 下单数量
FROM
t_order t
WHERE
t.the_year = 2018
GROUP BY user_id;
8.3 分组后筛选数据
分组后筛选数据
需求:查询2018年订单数量大于1的用户,输出:用户id,下单数量,如下:
方式1 :
mysql> SELECT
user_id 用户id, COUNT(id) 下单数量
FROM
t_order t
WHERE
t.the_year = 2018
GROUP BY user_id
HAVING count(id)>=2;
**方式2: **
mysql> SELECT
user_id 用户id, count(id) 下单数量
FROM
t_order t
WHERE
t.the_year = 2018
GROUP BY user_id
HAVING 下单数量>=2;
8.4 where和having的区别
where是在分组(聚合)前对记录进行筛选,而having是在分组结束后的结果里筛选,最后返回整个
sql的查询结果。
可以把having理解为两级查询,即含having的查询操作先获得不含having子句时的sql查询结果表,然
后在这个结果表上使用having条件筛选出符合的记录,最后返回这些记录,因此,having后是可以跟聚合函数的,并且这个聚集函数不必与select后面的聚集函数相同。
#### 8.5 分组后排序
需求:获取每个用户最大金额,然后按照最大金额倒序,输出:用户id,最大金额,如下:
mysql> SELECT
user_id 用户id, max(price) 最大金额
FROM
t_order t
GROUP BY user_id
ORDER BY 最大金额 desc;
8.6 where & group by & having & order by & limit 一起协作
where、group by、having、order by、limit这些关键字一起使用时,先后顺序有明确的限制,语法如 下:
select 列 from
表名
where [查询条件]
group by [分组表达式]
having [分组过滤条件]
order by [排序条件]
limit [offset,] count;
注意:
写法上面必须按照上面的顺序来写
示例
需求:查询出2018年,下单数量大于等于2的,按照下单数量降序排序,最后只输出第1条记录,显 示:用户id,下单数量,如下:
mysql> SELECT
user_id 用户id, COUNT(id) 下单数量
FROM
t_order t
WHERE
t.the_year = 2018
GROUP BY user_id
HAVING count(id)>=2
ORDER BY 下单数量 DESC
LIMIT 1;
8.7 mysql分组中的坑
本文开头有介绍,分组中select后面的列只能有2种:
-
出现在group by后面的列
-
使用聚合函数的列
oracle、sqlserver、db2中也是按 照这种规范来的。
示例
需求:获取每个用户下单的最大金额及下单的年份,输出:用户id,最大金额,年份,写法如下
/*第一种*/
/*1. 先查每个用户,下单最大金额,然后再在订单里面找订单年份*/
mysql> SELECT
user_id 用户id,
price 最大金额,
the_year 年份
FROM
t_order t1
WHERE
(t1.user_id , t1.price)
IN
(SELECT
t.user_id, MAX(t.price)
FROM
t_order t
GROUP BY t.user_id);
/*第二种*/
/*分开查询各个数据,最后通过where and 把符合条件的留下*/
mysql> SELECT
user_id 用户id,
price 最大金额,
the_year 年份
FROM
t_order t1,
(SELECT t.user_id uid, MAX(t.price) pc
FROM
t_order t
GROUP BY t.user_id) t2
WHERE
t1.user_id = t2.uid
AND t1.price = t2.pc;
**在写分组查询的时候,最好按照标准的规范来写,select后面出现的列必须在group by中或者必
须使用聚合函数。 **
总结
- 在写分组查询的时候,最好按照标准的规范来写,select后面出现的列必须在group by中或者必
须使用聚合函数 - select语法顺序:select、from、where、group by、having、order by、limit,顺序不能搞错
了,否则报错。 - in多列查询的使用,下去可以试试
9 深入了解连接查询及原理
当我们查询的数据来源于多张表的时候,我们需要用到连接查询,连接查询使用率非常高,希望大家都务必掌握。
9.1 笛卡尔积
笛卡尔积简单点理解:有两个集合A和B,笛卡尔积表示A集合中的元素和B集合中的元素任意相互关联
产生的所有可能的结果。
假如A中有m个元素,B中有n个元素,A、B笛卡尔积产生的结果有m*n个结果,相当于循环遍历两个集合中的元素,任意组合 .
for(Object eleA : A){
for(Object eleB : B){
System.out.print(eleA+","+eleB);
}
}
过程:拿A集合中的第1行,去匹配集合B中所有的行,然后再拿集合A中的第2行,去匹配集合B
中所有的行,最后结果数量为m*n。
9.2 sql中笛卡尔积语法
select 字段 from 表1,表2[,表N];
或者
select 字段 from 表1 join 表2 [join 表N];
9.3 内连接
select 字段 from 表1 inner join 表2 on 连接条件;
或 select 字段 from 表1 join 表2 on 连接条件;
或 select 字段 from 表1, 表2 [where 关联条件];
内连接相当于在笛卡尔积的基础上加上了连接的条件。
当没有连接条件的时候,内连接上升为笛卡尔积。
过程用java伪代码如下:
for(Object eleA : A){
for(Object eleB : B){
if(连接条件是否为true){
System.out.print(eleA+","+eleB);
}
}
}
示例1:有连接条件
查询员工及所属部门
mysql> select t1.emp_name,t2.team_name from t_employee t1 inner join t_team t2
on t1.team_id = t2.id;
上面相当于获取了2个表的交集,查询出了两个表都有的数据
示例2:无连接条件
无条件内连接,上升为笛卡尔积,如下:
mysql> select t1.emp_name,t2.team_name from t_employee t1 inner join t_team t2;
示例3: 组合条件
查询架构组的员工,3种写法
mysql> select t1.emp_name,t2.team_name from t_employee t1 inner join t_team t2
on t1.team_id = t2.id and t2.team_name = '架构组';
上面3中方式解说。
方式1:on中使用了组合条件。
方式2:在连接的结果之后再进行过滤,相当于先获取连接的结果,然后使用where中的条件再对连接
结果进行过滤。
方式3:直接在where后面进行过滤
总结
内连接建议使用第3种语法,简洁:
内连接建议使用第3种语法,简洁:
9.4 外连接
外连接涉及到2个表,分为:主表和从表,要查询的信息主要来自于哪个表,谁就是主表。
外连接查询结果为主表中所有记录。如果从表中有和它匹配的,则显示匹配的值,这部分相当于内连接查询出来的结果;如果从表中没有和它匹配的,则显示null。
最终:外连接查询结果 = 内连接的结果 + 主表中有的而内连接结果中没有的记录。
外连接分为2种:
左外链接:使用left join关键字,left join左边的是主表。
右外连接:使用right join关键字,right join右边的是主表。
9.5 左连接
select 列 from 主表 left join 从表 on 连接条件;
**示例1: **
查询所有员工信息,并显示员工所在组,如下:
mysql> SELECT
t1.emp_name,
t2.team_name
FROM
t_employee t1
LEFT JOIN
t_team t2
ON
t1.team_id = t2.id;
**示例2 : **
查询员工姓名、组名,返回组名不为空的记录,如下:
mysql> SELECT
t1.emp_name,
t2.team_name
FROM
t_employee t1
LEFT JOIN
t_team t2
ON
t1.team_id = t2.id
WHERE
t2.team_name IS NOT NULL;
上面先使用内连接获取连接结果,然后再使用where对连接结果进行过滤
9.6右连接
select 列 from 从表 right join 主表 on 连接条件;
9.7扩展
表连接中还可以使用前面学过的 group by 、 having 、 order by 、 limit 。
10. 子查询(本篇非常重要,高手必备)
出现在select语句中的select语句,称为子查询或内查询。
外部的select查询语句,称为主查询或外查询。
10.1 子查询分类
**按结果集的行列数不同分为4种 **
- 标量子查询(结果集只有一行一列)
- 列子查询(结果集只有一列多行)
- 行子查询(结果集有一行多列)
- 表子查询(结果集一般为多行多列)
**按子查询出现在主查询中的不同位置分 **
- select后面:仅仅支持标量子查询。
- from后面:支持表子查询。
- where或having后面:支持标量子查询(单列单行)、列子查询(单列多行)、行子查询(多列
多行) - exists后面(即相关子查询):表子查询(多行、多列)
10.2 select后面的子查询
子查询位于select后面的,仅仅支持标量子查询。
**示例1 **
查询每个部门员工个数
SELECT
a.*,
(SELECT count(*)
FROM employees b
WHERE b.department_id = a.department_id) AS 员工个数
FROM departments a;
**示例2 **
查询员工号=102的部门名称
SELECT (SELECT a.department_name
FROM departments a, employees b
WHERE a.department_id = b.department_id
AND b.employee_id = 102) AS 部门名;
10.3 from后面的子查询
将子查询的结果集充当一张表,要求必须起别名,否者这个表找不到。
然后将真实的表和子查询结果表进行连接查询 .
**示例1 **
查询每个部门平均工资的工资等级
-- 查询每个部门平均工资
SELECT
department_id,
avg(a.salary)
FROM employees a
GROUP BY a.department_id;
-- 薪资等级表
SELECT *
FROM job_grades;
-- 将上面2个结果连接查询,筛选条件:平均工资 between lowest_sal and highest_sal;
SELECT
t1.department_id,
sa AS '平均工资',
t2.grade_level
FROM (SELECT
department_id,
avg(a.salary) sa
FROM employees a
GROUP BY a.department_id) t1, job_grades t2
WHERE
t1.sa BETWEEN t2.lowest_sal AND t2.highest_sal;
10.4 where和having后面的子查询
where或having后面,可以使用
- 标量子查询(单行单列行子查询)
- 列子查询(单列多行子查询)
- 行子查询(一行多列 )
特点
- 子查询放在小括号内。
- 子查询一般放在条件的右侧。
- 标量子查询,一般搭配着单行单列操作符使用 >、<、>=、<=、=、<>、!=
- 列子查询,一般搭配着多行操作符使用
in(not in):列表中的“任意一个”
any或者some:和子查询返回的“某一个值”比较,比如a>some(10,20,30),a大于子查询中
任意一个即可,a大于子查询中最小值即可,等同于a>min(10,20,30)。
all:和子查询返回的“所有值”比较,比如a>all(10,20,30),a大于子查询中所有值,换句话
说,a大于子查询中最大值即可满足查询条件,等同于a>max(10,20,30);
- 子查询的执行优先于主查询执行,因为主查询的条件用到了子查询的结果
10.5 mysql中的in、any、some、all
in,any,some,all分别是子查询关键词之一。
in:in常用于where表达式中,其作用是查询某个范围内的数据
any和some一样: 可以与=、>、>=、<、<=、<>结合起来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的任何一个数据。
all:可以与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等
于、不等于其中的其中的所有数据。
10.6 标量子查询
一般标量子查询,示例
查询谁的工资比Abel的高?
/*①查询abel的工资【改查询是标量子查询】*/
SELECT salary
FROM employees
WHERE last_name = 'Abel';
/*②查询员工信息,满足salary>①的结果*/
SELECT *
FROM employees a
WHERE a.salary > (SELECT salary
FROM employees
WHERE last_name = 'Abel');
多个标量子查询,示例
返回job_id与141号员工相同,salary比143号员工多的员工、姓名、job_id和工资
/*返回job_id与141号员工相同,salary比143号员工多的员工、姓名、job_id和工资*/
/*①查询141号员工的job_id*/
SELECT job_id
FROM employees
WHERE employee_id = 141;
/*②查询143好员工的salary*/
SELECT salary
FROM employees
WHERE employee_id = 143;
/*③查询员工的姓名、job_id、工资,要求job_id=① and salary>②*/
SELECT
a.last_name 姓名,
a.job_id,
a.salary 工资
FROM employees a
WHERE a.job_id = (SELECT job_id
FROM employees
WHERE employee_id = 141)
AND
a.salary > (SELECT salary
FROM employees
WHERE employee_id = 143);
10.7 子查询+分组函数,示例
查询最低工资大于50号部门最低工资的部门id和其最低工资【having】
/*查询最低工资大于50号部门最低工资的部门id和其最低工资【having】*/
/*①查询50号部门的最低工资*/
SELECT min(salary)
FROM employees
WHERE department_id = 50;
/*②查询每个部门的最低工资*/
SELECT
min(salary),
department_id
FROM employees
GROUP BY department_id;
/*③在②的基础上筛选,满足min(salary)>①*/
SELECT
min(a.salary) minsalary,
department_id
FROM employees a
GROUP BY a.department_id
HAVING min(a.salary) > (SELECT min(salary)
FROM employees
WHERE department_id = 50);
10.8 错误的标量子查询,示例
将上面的示例③中子查询语句中的min(salary)改为salary,执行效果如下:
mysql> SELECT
min(a.salary) minsalary,
department_id
FROM employees a
GROUP BY a.department_id
HAVING min(a.salary) > (SELECT salary
FROM employees
WHERE department_id = 500000);
ERROR 1242 (21000): Subquery returns more than 1 row
错误提示:子查询返回的结果超过了1行记录。
说明:上面的子查询只支持最多一列一行记录
10.9 列子查询(子查询结果集一列多行)
列子查询需要搭配多行操作符使用:in(not in)、any/some、all。
为了提升效率,最好去重一下distinct关键字。
示例1
返回location_id是1400或1700的部门中的所有员工姓名
/*返回location_id是1400或1700的部门中的所有员工姓名*/
/*方式1*/
/*①查询location_id是1400或1700的部门编号*/
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN (1400, 1700);
/*②查询员工姓名,要求部门是①列表中的某一个*/
SELECT a.last_name
FROM employees a
WHERE a.department_id IN (SELECT DISTINCT department_id
FROM departments
WHERE location_id IN (1400, 1700));
/*方式2:使用any实现*/
SELECT a.last_name
FROM employees a
WHERE a.department_id = ANY (SELECT DISTINCT department_id
FROM departments
WHERE location_id IN (1400, 1700));
/*拓展,下面与not in等价*/
SELECT a.last_name
FROM employees a
WHERE a.department_id <> ALL (SELECT DISTINCT department_id
FROM departments
WHERE location_id IN (1400, 1700));
**示例2 **
返回其他工种中比job_id为'IT_PROG'工种任意工资低的员工的员工号、姓名、job_id、salary
/*返回其他工种中比job_id为'IT_PROG'工种任一工资低的员工的员工号、姓名、job_id、salary*/
/*①查询job_id为'IT_PROG'部门任-工资*/
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG';
/*②查询员工号、姓名、job_id、salary,slary<①的任意一个*/
SELECT
last_name,
employee_id,
job_id,
salary
FROM employees
WHERE salary < ANY (SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG') AND job_id != 'IT_PROG';
/*或者*/
SELECT
last_name,
employee_id,
job_id,
salary
FROM employees
WHERE salary < (SELECT max(salary)
FROM employees
WHERE job_id = 'IT_PROG') AND job_id != 'IT_PROG';
**示例3 **
返回其他工种中比job_id为'IT_PROG'部门所有工资低的员工的员工号、姓名、job_id、salary
/*返回其他工种中比job_id为'IT_PROG'部门所有工资低的员工的员工号、姓名、job_id、salary*/
SELECT
last_name,
employee_id,
job_id,
salary
FROM employees
WHERE salary < ALL (SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG') AND job_id != 'IT_PROG';
/*或者*/
SELECT
last_name,
employee_id,
job_id,
salary
FROM employees
WHERE salary < (SELECT min(salary)
FROM employees
WHERE job_id = 'IT_PROG') AND job_id != 'IT_PROG';
10.10 行子查询(子查询结果集一行多列)
查询员工编号最小并且工资最高的员工信息,3种方式
/*查询员工编号最小并且工资最高的员工信息*/
/*①查询最小的员工编号*/
SELECT min(employee_id)
FROM employees;
/*②查询最高工资*/
SELECT max(salary)
FROM employees;
/*③方式1:查询员工信息*/
SELECT *
FROM employees a
WHERE a.employee_id = (SELECT min(employee_id)
FROM employees)
AND salary = (SELECT max(salary)
FROM employees);
/*方式2*/
SELECT *
FROM employees a
WHERE (a.employee_id, a.salary) = (SELECT
min(employee_id),
max(salary)
FROM employees);
/*方式3*/
SELECT *
FROM employees a
WHERE (a.employee_id, a.salary) in (SELECT
min(employee_id),
max(salary)
FROM employees);
方式1比较常见,方式2、3更简洁。
10.11 exists后面(也叫做相关子查询)
- 语法:exists(完整的查询语句)。
- exists查询结果:1或0,exists查询的结果用来判断子查询的结果集中是否有值。
- 一般来说,能用exists的子查询,绝对都能用in代替,所以exists用的少。
- 和前面的查询不同,这先执行主查询,然后主查询查询的结果,在根据子查询进行过滤,子查询中
涉及到主查询中用到的字段,所以叫相关
**示例1 **
简单示例
mysql> SELECT exists(SELECT employee_id
FROM employees
WHERE salary = 300000) AS 'exists返回1或者0';
**示例2 **
查询所有员工的部门名称
/*exists入门案例*/
SELECT exists(SELECT employee_id
FROM employees
WHERE salary = 300000) AS 'exists返回1或者0';
/*查询所有员工部门名*/
SELECT department_name
FROM departments a
WHERE exists(SELECT 1
FROM employees b
/*使用in实现*/
SELECT department_name
FROM departments a
WHERE a.department_id IN (SELECT department_id
FROM employees);
**示例3 **
查询没有员工的部门
/*查询没有员工的部门*/
/*exists实现*/
SELECT *
FROM departments a
WHERE NOT exists(SELECT 1
FROM employees b
WHERE a.department_id = b.department_id AND b.department_id IS
NOT NULL);
/*in的方式*/
SELECT *
FROM departments a
WHERE a.department_id NOT IN (SELECT department_id
FROM employees b
WHERE b.department_id IS NOT NULL);
NULL的大坑
**示例1 **
使用not in的方式查询没有员工的部门,如下
SELECT *
FROM departments a
WHERE a.department_id NOT IN (SELECT department_id
FROM employees b);
运行结果:
mysql> SELECT *
-> FROM departments a
-> WHERE a.department_id NOT IN (SELECT department_id
-> FROM employees b);
Empty set (0.00 sec)
not in的情况下,子查询中列的值为NULL的时候,外查询的结果为空。
**建议:建表是,列不允许为空。 **
总结
- 本文中讲解了常见的子查询,请大家务必多练习
- 注意in、any、some、any的用法
- 字段值为NULL的时候,not in查询有大坑,这个要注意
- 建议创建表的时候,列不允许为空
11. 细说NULL导致的神坑,让人防不胜防
11.1 比较运算符中使用NULL
任何值和NULL使用运算符(>、<、>=、<=、!=、<>)或者(in、not in、any/some、all)比
较时,返回值都为NULL,NULL作为布尔值的时候,不为1也不为0。
11.2 IN、NOT IN和NULL比较
**IN和NULL比较 **
mysql> select * from test1;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| 1 | NULL |
| NULL | NULL |
+------+------+
3 rows in set (0.00 sec)
mysql> select * from test1 where a in (null);
Empty set (0.00 sec)
mysql> select * from test1 where a in (null,1);
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| 1 | NULL |
+------+------+
2 rows in set (0.00 sec)
**结论:当IN和NULL比较时,无法查询出为NULL的记录。 **
**NOT IN 和NULL比较 **
mysql> select * from test1 where a not in (1);
Empty set (0.00 sec)
mysql> select * from test1 where a not in (null);
Empty set (0.00 sec)
mysql> select * from test1 where a not in (null,2);
Empty set (0.00 sec)
mysql> select * from test1 where a not in (2);
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| 1 | NULL |
+------+------+
2 rows in set (0.00 sec)
**结论:当NOT IN 后面有NULL值时,不论什么情况下,整个sql的查询结果都为空。 **
**EXISTS、NOT EXISTS和NULL比较 **
mysql> select * from test2;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| 1 | NULL |
| NULL | NULL |
+------+------+
3 rows in set (0.00 sec)
mysql> select * from test1 t1 where exists (select * from test2 t2 where t1.a =
t2.a);
+------+------+
| a | b |
+------+------+
| 1 | 1 |
| 1 | NULL |
+------+------+
2 rows in set (0.00 sec)
mysql> select * from test1 t1 where not exists (select * from test2 t2 where
t1.a = t2.a);
+------+------+
| a | b |
+------+------+
| NULL | NULL |
+------+------+
1 row in set (0.00 sec)
上面我们复制了表test1创建了表test2。 查询语句中使用exists、not exists对比test1.a=test2.a,因为=不能比较NULL,结果和预期一致。
11.2 判断NULL只能用IS NULL、IS NOT NULL
mysql> select 1 is not null;
+---------------+
| 1 is not null |
+---------------+
| 1 |
+---------------+
1 row in set (0.00 sec)
mysql> select 1 is null;
+-----------+
| 1 is null |
+-----------+
| 0 |
+-----------+
1 row in set (0.00 sec)
mysql> select null is null;
+--------------+
| null is null |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
mysql> select null is not null;
+------------------+
| null is not null |
+------------------+
| 0 |
+------------------+
1 row in set (0.00 sec)
**结论:判断是否为空只能用IS NULL、IS NOT NULL。 **
11.3 聚合函数中NULL的坑
mysql> select count(a),count(b),count(*) from test1;
+----------+----------+----------+
| count(a) | count(b) | count(*) |
+----------+----------+----------+
| 2 | 1 | 3 |
+----------+----------+----------+
1 row in set (0.00 sec)
count(a)返回了2行记录,a字段为NULL的没有统计出来。
count(b)返回了1行记录,为NULL的2行记录没有统计出来。
count(*)可以统计所有数据,不论字段的数据是否为NULL。
**结论:count(字段)无法统计字段为NULL的值,count(*)可以统计值为null的行 **
11.4 NULL不能作为主键的值
从上面的脚本可以看出,当字段为主键的时候,字段会自动设置为 not null 。
结论:当字段为主键的时候,字段会自动设置为not null。
看了上面这些还是比较晕,NULL的情况确实比较难以处理,容易出错,最有效的方法就是避免使用NULL。所以,强烈建议创建字段的时候字段不允许为NULL,设置一个默认值。
总结
- NULL作为布尔值的时候,不为1也不为0
- 任何值和NULL使用运算符(>、<、>=、<=、!=、<>)或者(in、not in、any/some、all),
返回值都为NULL - 当IN和NULL比较时,无法查询出为NULL的记录
- 当NOT IN 后面有NULL值时,不论什么情况下,整个sql的查询结果都为空
- 判断是否为空只能用IS NULL、IS NOT NULL
- count(字段)无法统计字段为NULL的值,count(*)可以统计值为null的行
12 b+树
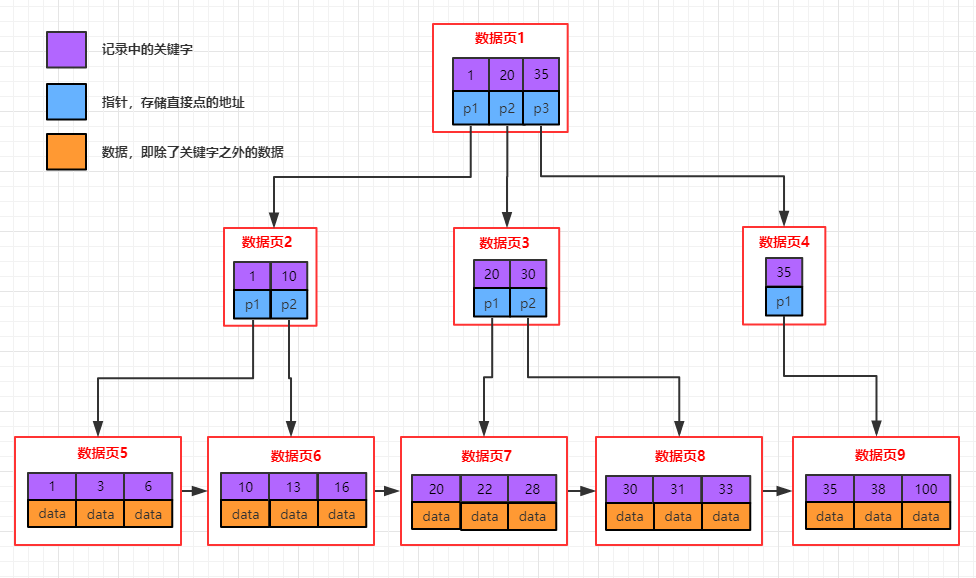
先看个b+树结构图:
12.1 b+树的特征
\1. 每个结点至多有m个子女
\2. 除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女
\3. 有k个子女的结点必有k个关键字
\4. 父节点中持有访问子节点的指针
\5. 父节点的关键字在子节点中都存在(如上面的1/20/35在每层都存在),要么是最小值,要么是最
大值,如果节点中关键字是升序的方式,父节点的关键字是子节点的最小值
\6. 最底层的节点是叶子节点
\7. 除叶子节点之外,其他节点不保存数据,只保存关键字和指针
\8. 叶子节点包含了所有数据的关键字以及data,叶子节点之间用链表连接起来,可以非常方便的支
持范围查找
12.2 b+树与b-树的几点不同
1.b+树中一个节点如果有k个关键字,最多可以包含k个子节点(k个关键字对应k个指针);而b-树
对应k+1个子节点(多了一个指向子节点的指针)
\2. b+树除叶子节点之外其他节点值存储关键字和指向子节点的指针,而b-树还存储了数据,这样同
样大小情况下,b+树可以存储更多的关键字
\3. b+树叶子节点中存储了所有关键字及data,并且多个节点用链表连接,从上图中看子节点中数据
从左向右是有序的,这样快速可以支撑范围查找(先定位范围的最大值和最小值,然后子节点中依
靠链表遍历范围数据)
13 索引
分为聚集索引和非聚集索引
13.1 索引分类
聚合索引
每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存
在文件中,叶子节点存储主键的值以及对应记录的数据,非叶子节点不存储记录的数据,只存储主键的
值。当表中未指定主键时,mysql内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作
为主键,用rowid构建聚集索引。
聚集索引在mysql中又叫主键索引
非聚集索引(辅助索引)
也是b+树结构,不过有一点和聚集索引不同,非聚集索引叶子节点存储字段(索引字段)的值以及对应
记录主键的值,其他节点只存储字段的值(索引字段)。
每个表可以有多个非聚集索引
13.2 mysql中非聚集索引分为
**单列索引 **
即一个索引只包含一个列。
**多列索引(又称复合索引) **
即一个索引包含多个列。
**唯一索引 **
索引列的值必须唯一,允许有一个空值。
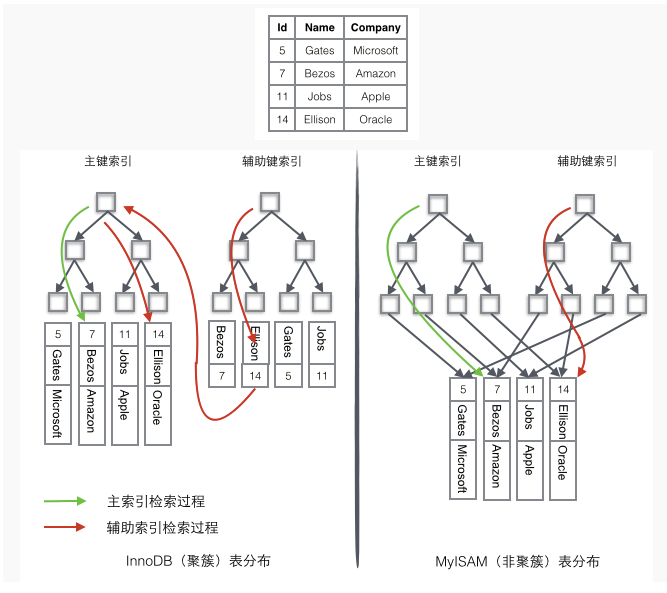
上面的表中有2个索引:id作为主键索引,name作为辅助索引。
innodb我们用的最多,我们只看图中左边的innodb中数据检索过程:
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name='Ellison'的数据,需要2步:
1. 先在辅助索引中检索到name='Ellison'的数据,获取id为14
2. 再到主键索引中检索id为14的记录
辅助索引相对于主键索引多了第二步。
13.3 索引管理
**创建索引 方式1 **
create [unique] index 索引名称 on 表名(列名[(length)]);
方式2
alter 表名 add [unique] index 索引名称 on (列名[(length)]);
如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类
型,必须指定length。
[unique]:中括号代表可以省略,如果加上了unique,表示创建唯一索引。
如果table后面只写一个字段,就是单列索引,如果写多个字段,就是复合索引,多个字段之间用
逗号隔开
**删除索引 **
rop index 索引名称 on 表名
**查看索引 **
查看某个表中所有的索引信息如下:
show index from 表名;
**索引修改 **
可以先删除索引,再重建索引。
14如何正确使用索引
14.1 通常说的这个查询走索引了是什么意思?
当我们对某个字段的值进行某种检索的时候,如果这个检索过程中,我们能够快速定位到目标数据所在
的页,有效的降低页的io操作,而不需要去扫描所有的数据页的时候,我们认为这种情况能够有效的利
用索引,也称这个检索可以走索引,如果这个过程中不能够确定数据在那些页中,我们认为这种情况下
索引对这个查询是无效的,此查询不走索引
14.2 b+树中数据检索过程
**唯一记录检索 **
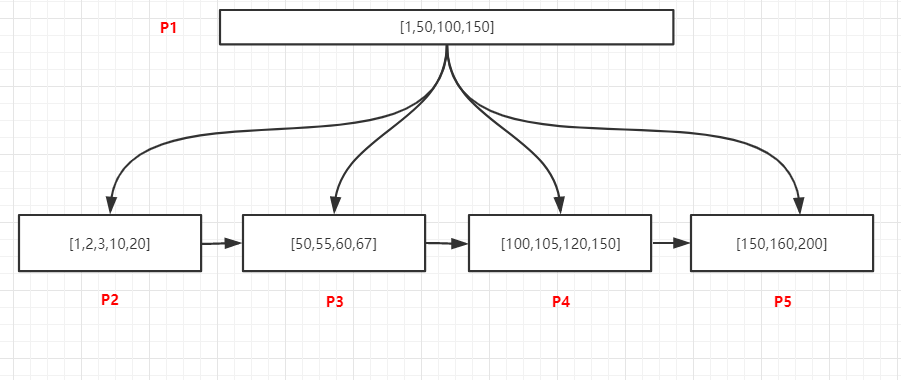
如上图,所有的数据都是唯一的,查询105的记录,过程如下:
- 将P1页加载到内存
- 在内存中采用二分法查找,可以确定105位于[100,150)中间,所以我们需要去加载100关联P4页
- 将P4加载到内存中,采用二分法找到105的记录后退出
**查询某个值的所有记录 **
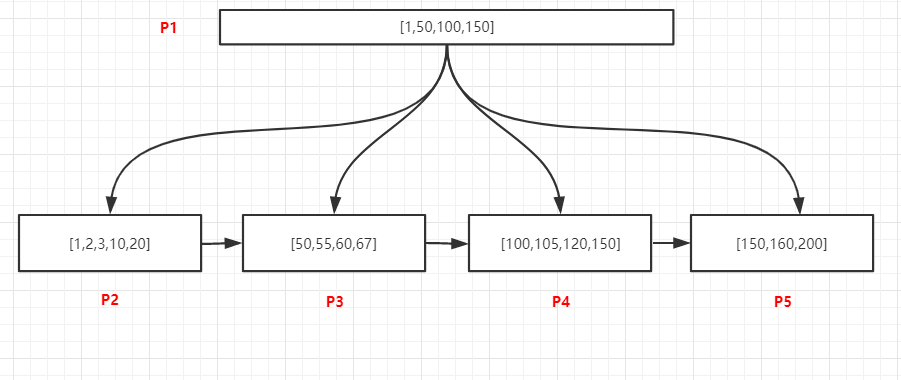
如上图,查询105的所有记录,过程如下:
1. 将P1页加载到内存
2. 在内存中采用二分法查找,可以确定105位于[100,150)中间,100关联P4页
3. 将P4加载到内存中,采用二分法找到最有一个小于105的记录,即100,然后通过链表从100开始
向后访问,找到所有的105记录,直到遇到第一个大于100的值为止
**范围查找 **
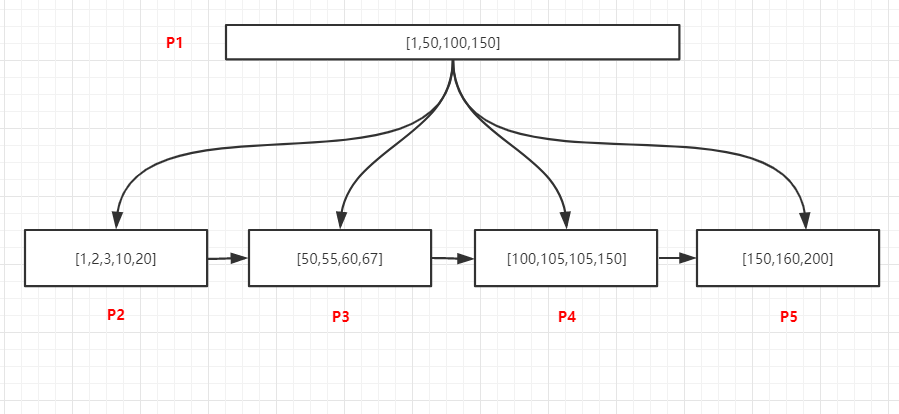
数据如上图,查询[55,150]所有记录,由于页和页之间是双向链表升序结构,页内部的数据是单项升序
链表结构,所以只用找到范围的起始值所在的位置,然后通过依靠链表访问两个位置之间所有的数据即
可,过程如下:
1. 将P1页加载到内存
2. 内存中采用二分法找到55位于50关联的P3页中,150位于P5页中
3. 将P3加载到内存中,采用二分法找到第一个55的记录,然后通过链表结构继续向后访问P3中的
60、67,当P3访问完毕之后,通过P3的nextpage指针访问下一页P4中所有记录,继续遍历P4中
的所有记录,直到访问到P5中的150为止。
**模糊匹配 **
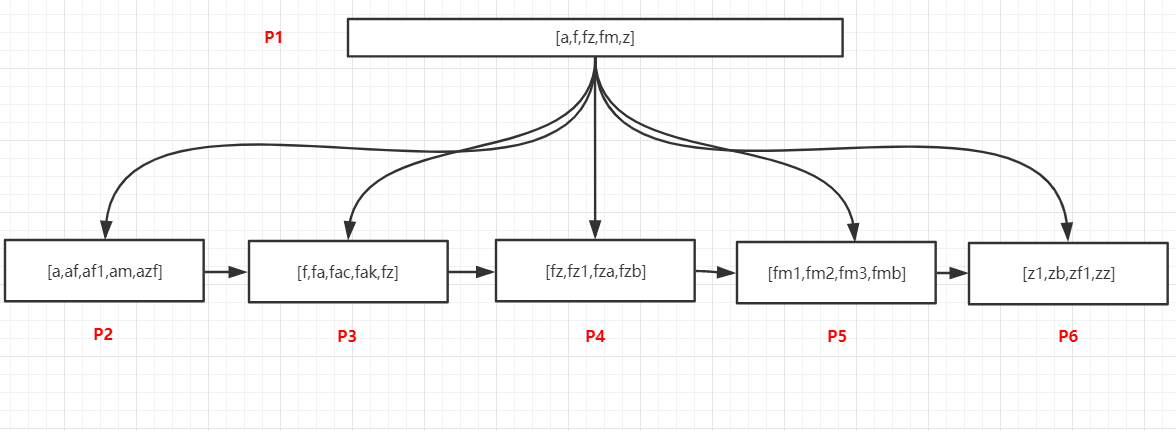
过程如下:
1. 将P1数据加载到内存中
2. 在P1页的记录中采用二分法找到最后一个小于等于f的值,这个值是f,以及第一个大于f的,这个
值是z,f指向叶节点P3,z指向叶节点P6,此时可以断定以f开头的记录可能存在于[P3,P6)这个范
围的页内,即P3、P4、P5这三个页中
3. 加载P3这个页,在内部以二分法找到第一条f开头的记录,然后以链表方式继续向后访问P4、P5中
的记录,即可以找到所有已f开头的数据
**查询包含 f 的记录 **
包含的查询在sql中的写法是 %f% ,通过索引我们还可以快速定位所在的页么?
可以看一下上面的数据,f在每个页中都存在,我们通过P1页中的记录是无法判断包含f的记录在那些页
的,只能通过io的方式加载所有叶子节点,并且遍历所有记录进行过滤,才可以找到包含f的记录。
所以如果使用了 %值% 这种方式,索引对查询是无效的。
**最左匹配原则 **
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来
建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步
的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有
name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第
一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数
据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于
张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配
特性。
14.3索引区分度
索引区分度 = count(distint 记录) / count(记录)
当索引区分度高的时候,检索数据更快一些,索引区分度太低,说明重复的数据比较多,检索的时候需
要访问更多的记录才能够找到所有目标数据。
所以我们创建索引的时候,尽量选择区分度高的列作为索引。
14.4 索引如何走
当多个条件中有索引的时候,并且关系是and的时候,会走索引区分度高的,显然name字段重复度很低,走name查询会更快一些。
14.5模糊查询
mysql> select count(*) from test1 a where a.name like 'javacode1000%';
+----------+
| count(*) |
+----------+
| 1111 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from test1 a where a.name like '%javacode1000%';
+----------+
| count(*) |
+----------+
| 1111 |
+----------+
1 row in set (1.78 sec)
上面第一个查询可以利用到name字段上面的索引,下面的查询是无法确定需要查找的值所在的范
围的,只能全表扫描,无法利用索引,所以速度比较慢,这个过程上面有说过。
**回表 **
当需要查询的数据在索引树中不存在的时候,需要再次到聚集索引中去获取,这个过程叫做回
表,
**索引覆盖 **
查询中采用的索引树中包含了查询所需要的所有字段的值,不需要再去聚集索引检索数据,这种
叫索引覆盖。
**索引下推 **
简称ICP,Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索
引过滤数据的一种优化方式,ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储
引擎的次数
**数字使字符串类索引失效 **
id上面有主键索引,id是int类型的,可以看到,上面两个查询都非常快,都可以正常利用索引快
速检索,所以如果字段是数组类型的,查询的值是字符串还是数组都会走索引。
**函数使索引无效 **
name上有索引,上面查询,第一个走索引,第二个不走索引,第二个使用了函数之后,name所
在的索引树是无法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然
后对每条数据使用函数进行计算之后再进行条件判断,此时索引无效了,变成了全表数据扫描。
**结论:索引字段使用函数查询使索引无效 **
**运算符使索引无效 **
id上有主键索引,上面查询,第一个走索引,第二个不走索引,第二个使用运算符,id所在的索
引树是无法快速定位需要查找的数据所在的页的,只能将所有页的记录加载到内存中,然后对每
条数据的id进行计算之后再判断是否等于1,此时索引无效了,变成了全表数据扫描。
**结论:索引字段使用了函数将使索引无效。 **
14.5总结一下使用索引的一些建议
1. 在区分度高的字段上面建立索引可以有效的使用索引,区分度太低,无法有效的利用索引,可能需
要扫描所有数据页,此时和不使用索引差不多
2. 联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,mysql会一直向右匹配直到遇到范围
查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立
(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可
以任意调整
3. 查询记录的时候,少使用*,尽量去利用索引覆盖,可以减少回表操作,提升效率
4. 有些查询可以采用联合索引,进而使用到索引下推(IPC),也可以减少回表操作,提升效率
5. 禁止对索引字段使用函数、运算符操作,会使索引失效
6. 字符串字段和数字比较的时候会使索引无效
7. 模糊查询'%值%'会使索引无效,变为全表扫描,但是'值%'这种可以有效利用索引
8. 排序中尽量使用到索引字段,这样可以减少排序,提升查询效率
15 事务
-
什么是事务?
可以用来维护数据库的完整性,它保障成批的MySQL操作要么完全执行,要么完全不执行
-
事务的4个特性:
事务是必须满足4个条件(ACID) :
■原子性Atomicity: -一个事务中的所有操作,要么全部完成,要么全部不完成,最小的执行单位。
■一致性 Consistency: 事务执行前后,都处于-致性状态 。
■隔离性Isolation: 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止
多个事务并发执行时由于交叉执行而导致数据的不一一致。
■持久性Durability: 事务执行完成后,对数据的修改就是永久的,即便系统故障也不会丢失。 -
事务的隔离级别:
■READ. UNCOMMITTED
这是事务最低的隔离级别,它充许另外-一个事务可以看到这个事务未提交的数据。解决第一类丢失更
新的问题,但是会出现脏读、不可重复读、第二类丢失更新的问题,幻读。
■READ COMMITTED
保证一个事务修改的数据提交后才能被另外-一个事务读取,即另外一个事务不能读取该事务未提交的
数据。解决第一类丢失更新和脏读的问题,但会出现不可重复读、第二类丢失更新的问题,幻读问题
■REPEATABLE _READ repeatable_read (礼貌)
保证一个事务相同条件下前后两次获取的数据是一致的(注意是 一个事务,可以理解为事务间的数
据互不影响)解决第一类丢失更新, 脏读、不可重复读、第二类丢失更新的问题,但会出幻读。
■SERIALIZABLE serialzable
事务串行执行,解决了脏读、不可重复读、幻读。但效率很差,所以实际中一般不用。

