Hive高级:函数
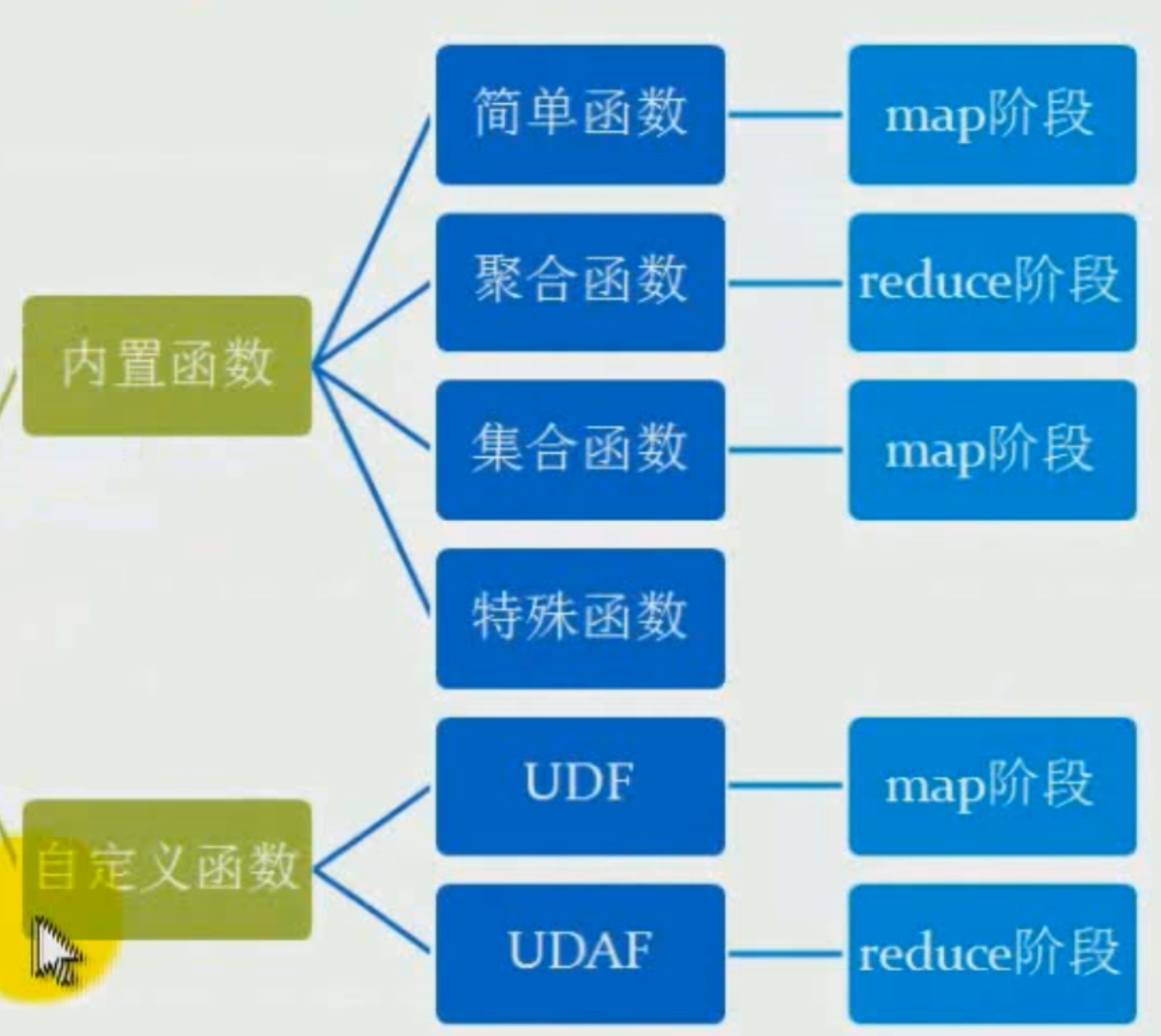
函数
- 内置函数
- 自定义
cli命令
- show functions [like "<pattern>"] 会列出所有函数,包括自定义函数。可以用正则检索。
- desc function fun_name :显示简单的信息介绍
- desc function extended fun_name :显示详细介绍,包括例子。
hive> desc function extended concat; OK tab_name concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data bin1, bin2, ... binN Returns NULL if any argument is NULL. Example: > SELECT concat('abc', 'def') FROM src LIMIT 1; 'abcdef' Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFConcat Function type:BUILTIN
简单函数
函数的计算粒度-单条记录。
特殊函数
- 窗口函数
- 分析函数
- 混合函数
- UDTF
窗口

分析函数:

混合:


内置函数
get_json_object
hive> select get_json_object('{"name":"jack", "age":"22"}', '$.name'); OK _c0 jack
parse_url() 取url的一部分。
concat
# 把type字段的值和"123"拼接 hive> select concat(type, '123') from winfunc; _c0 abc123 bcd123 cde123 def123 ...
concat_ws
带分隔符号的拼接。分隔付哈可以
hive> select concat_ws('.',type, '123') from winfunc; OK _c0 abc.123 bcd.123 cde.123 def.123 abc.123
split(string, 分隔符)
返回一个数组
hive> select split("abc", ""); OK _c0 ["a","b","c",""]
hive> select concat_ws('.',split(type,"")) from winfunc; OK _c0 a.b.c. b.c.d. c.d.e.
collect_set
返回set,去重
collect_list
返回数组.
select collect_list(id) from winfunc; 。。。 ["1001","1001","1001","1001","1002","1002","1002","1002","1002","1002","1003","1003","1004"]
select collect_set(id) from winfunc;
⚠️:hive sql语法中的这2个函数的作用等同于mysql中的聚合函数group_concat()。group_concat()相对功能更完善:
- 有去重关键字distinct
- 排序子句order by
- 有分隔符号子句: separator
GROUP_CONCAT( DISTINCT expression ORDER BY expression SEPARATOR sep );
相比之下,hsq中的collect_set, collect_list,concat, concat_ws,4个函数要配合使用,才达到group_concat的功能。
窗口函数:类似mysql新版本的窗口函数
hive sql的窗口函数和mysql的窗口函数用法完全一样!
具体用法见mysql:https://www.cnblogs.com/chentianwei/p/12145280.html
附加2020-4:再次理解窗口函数:
由三部分组成窗口函数:
- partition by,先对表格分组。【可选】
- order by,对每个组排序【可选】
- 函数+frame子句。对每行数据执行的操作,及操作的作用范围,默认是当前行及这行上面的本组的所有行。
概念:
- 当前行: 函数计算所在行被称为当前行current row
- 当前行的窗口: 当前行涉及的使用函数计算的query rows组成了一个窗口(由frame设置范围)。所以窗口就是指当前行涉及的使用函数计算的query rows。
- over()内部有3块分别是partition by , order by , 和最后一个frame子句。
格式:
函数() OVER ([PARTITION BY expr,..], [order by expr [asc|desc],...] [, window frame子句]) AS 别名
- 🌿即省缺window frame子句,range between unbounded precending and current row是默认值
- 同时省缺order by 和window frame子句,使用ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
- frame中的range和row的区别:
- range,第一,当前行的被函数()取值的列的value,然后,以这个value为根基,上下行的值如果都是这个value,都算当前行,然后再确定范围。逻辑意义上的行。
- rowS, 代表以行号来决定frame范围。物理意义上的行。
-
-
ROWS: The frame is defined by beginning and ending row positions. Offsets are differences in row numbers from the current row number. 行位置,物理意义上的行。 -
RANGE: The frame is defined by rows within a value range. Offsets are differences in row values from the current row value.
-
窗口函数:
-
lead,lag
-
first_value, last_value
和over合作的标准聚合函数:⚠️聚合函数也可以在over内使用(hive2.1以后版本)
- count
- sum
- min, max
- avg
分析函数:
- rank, dense_rank
- row_number 行号。
- cume_dist 累加行数占总行数的比例cumulative。
- percent_rank 类似cume_dist,计算方法有区别。
- ntile 分片,把数据平分成几片
例子:
数据:
col_name data_type
id string
money int
type string
hive> select * from winfunc; OK winfunc.id winfunc.money winfunc.type 1001 100 abc 1001 150 bcd 1001 200 cde 1001 150 def 1002 200 abc 1002 200 abc 1002 100 bcd 1002 300 cde 1002 50 def 1002 400 efg 1003 400 abc 1003 50 bdc 1004 60 abc
根据id分区,然后根据money排序,然后挑出first_value(money)。
hive> select id, money, first_value(money) over(partition by id order by money) > from winfunc;
id money first_value_window_0
1001 100 100
1001 150 100
1001 150 100
1001 200 100
1002 50 50
1002 100 50
1002 200 50
1002 200 50
1002 300 50
1002 400 50
1003 50 50
1003 400 50
1004 60 60
再看使用sum()函数的这个例子:
hive> select id, money, > sum(money) over (partition by id order by money) > from winfunc; #中间略 id money sum_window_0 1001 100 100 1001 150 400 1001 150 400 1001 200 600 1002 50 50 1002 100 150 1002 200 550 1002 200 550 1002 300 850 1002 400 1250 1003 50 50 1003 400 450 1004 60 60
如果再加上frame子句部分:
🌿即省缺window frame子句,range between unbounded precending and current row是默认值,因此本查询语句等于👆的查询语句的结果。
⚠️相同的值,被同时sum了。即第2行150,第3行150的第三列都是400,100+150+150.
hive> select id, money, > sum(money) over (partition by id order by money RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) > from winfunc; #略 id money sum_window_0 NULL NULL 1001 100 100 1001 150 400 1001 150 400 1001 200 600 1002 50 50 1002 100 150 1002 200 550 1002 200 550 1002 300 850 1002 400 1250 1003 50 50 1003 400 450 1004 60 60
但是,如果改成用rows取代range, 结果不同:
⚠️用rows不会考虑相同的值,此时的sum相当于累加计算。
hive> select id, money, > sum(money) over (partition by id order by money rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) > from winfunc; #略 id money sum_window_0 NULL NULL 1001 100 100 1001 150 250 1001 150 400 1001 200 600 1002 50 50 1002 100 150 1002 200 350 1002 200 550 1002 300 850 1002 400 1250 1003 50 50 1003 400 450 1004 60 60
看mysql文档关于rows和range:
-
ROWS: The frame is defined by beginning and ending row positions. Offsets are differences in row numbers from the current row number.框架范围是从开始到行结束位置。考虑的是行号。 -
RANGE: The frame is defined by rows within a value range. Offsets are differences in row values from the current row value.范围是关于值的范围。考虑的是这行的取值。如果当前行的上下行的值和当前行的相同,那么会被算作范围frame之内。
lead(列名,offset值, [default])
返回当前行的下面的指定行数的值。
hive> select id, money, > lead(money,2) over (partition by id order by money) > from winfunc; # id money lead_window_0 NULL NULL 1001 100 150 1001 150 200 1001 150 NULL 1001 200 NULL 1002 50 200 1002 100 200 1002 200 300 1002 200 400 1002 300 NULL 1002 400 NULL 1003 50 NULL 1003 400 NULL 1004 60 NULL
lag(列名, offset, [default])
返回前offset行的值,如果没有,则返回defalut参数。default可以自己定义。
把partition分成n组/桶,每行都分配所在组/桶号, 返回当前行所在partition的桶号。
rank()
排序,相同值给予相同序列标记。考虑gap。即1,2,2,4这样排序。2,2行是相同的值。
dense_rank()
排序,相同值给予相同序列标记。考虑gap。即1,2,2,3这样排序。2,2行是相同的值。
混合函数
java_method和reflect一样的功能。可以使用java的类的方法。
hive> select reflect("java.lang.Math", "sqrt", cast(id as double)) from winfunc;
- 参数1 是类
- 参数2 是方法
表函数(wiki) lateral view(横向视野)
LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias) *fromClause: FROM baseTable (lateralView)*- udft(): user defined function table。这里特指内建表格生成函数。如explode(expression)
用途:
- 首先,在原表的每行使用udtf(函数)。
- 然后,把结果输出行和输入行连接起来,形成一个虚拟表。
内建表格生成函数
例子:
hive> select id, adid > from winfunc > lateral view explode(split(type, "b")) tt as adid; OK id adid 1001 a 1001 c 1001 1001 cd 1001 cde 1001 def 1002 a 1002 c 1002 a 1002 c 1002 1002 cd 1002 cde 1002 def 1002 efg 1003 a 1003 c 1003 1003 dc 1004 a 1004 c
select dept_id, sum(if(sex='男',1,0)) as male_count, sum(if(sex='女',1,0)) as female_count from emp_sex
正则表达式
regexp_replace(字符串a, 字符串b, 字符串c)
- a是原字符串
- b是正则表达式
- c是符合条件后,要替换的字符串。
hive> select regexp_replace('foobar', 'oo|ar', ""); #返回 fb
regexp_extract()
a rlike b
nvl函数,
把null转化为指定值:比如nvl(列名, -1)把列中的null转化为-1.
⚠️其实就是if(expression, true结果, false结果) 的变种。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号