Hive基础
Hive
非官网中文:http://codingdict.com/article/8150
官网英文:https://www.tutorialspoint.com/hive/hive_introduction.htm (包括安装教程)
文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Apache Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,
可以将SQL语句转换为MapReduce任务进行运行。
其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
#hive查看一个表的详细信息,类似一些sql数据库 desc formatted 表名
Hadoop
大数据:包括巨大的数据存量,数据高速增值,每天都会大量增加。
传统方式不适合管理它。Hadoop即是一种管理大数据的框架。
- 开源
- 在分布式环境储处理数据
- 两种模式:
- MapReduce:这是一个并行编程模型,用于在大型商用硬件集群上处理大量数据。
- HDFS, hadoop distributed file system.用于储存和处理数据集dataset。它提供了一个容错文件系统在商品硬件上运行。
- 例如命令:stored as textfile把文件存储在hdfs上。
Hadoop生态系统包含不同的子项目(工具),例如用于帮助Hadoop模块的Sqoop,Pig和Hive。
- Hive: 它是一个用来开发SQL类型脚本来执行MapReduce操作的平台。
- Pig: 这是一个用于为MapReduce操作开发脚本的过程语言平台。MapReduce使用Pig处理结构化和半结构化数据的脚本方法。
- Sqoop: 它用于在HDFS和RDBMS之间导入和导出数据
shell命令
# 查看帮助文档
$ hadoop fs –help
# 查看具体某个命令的说明
$ hadoop fs –help <命令>
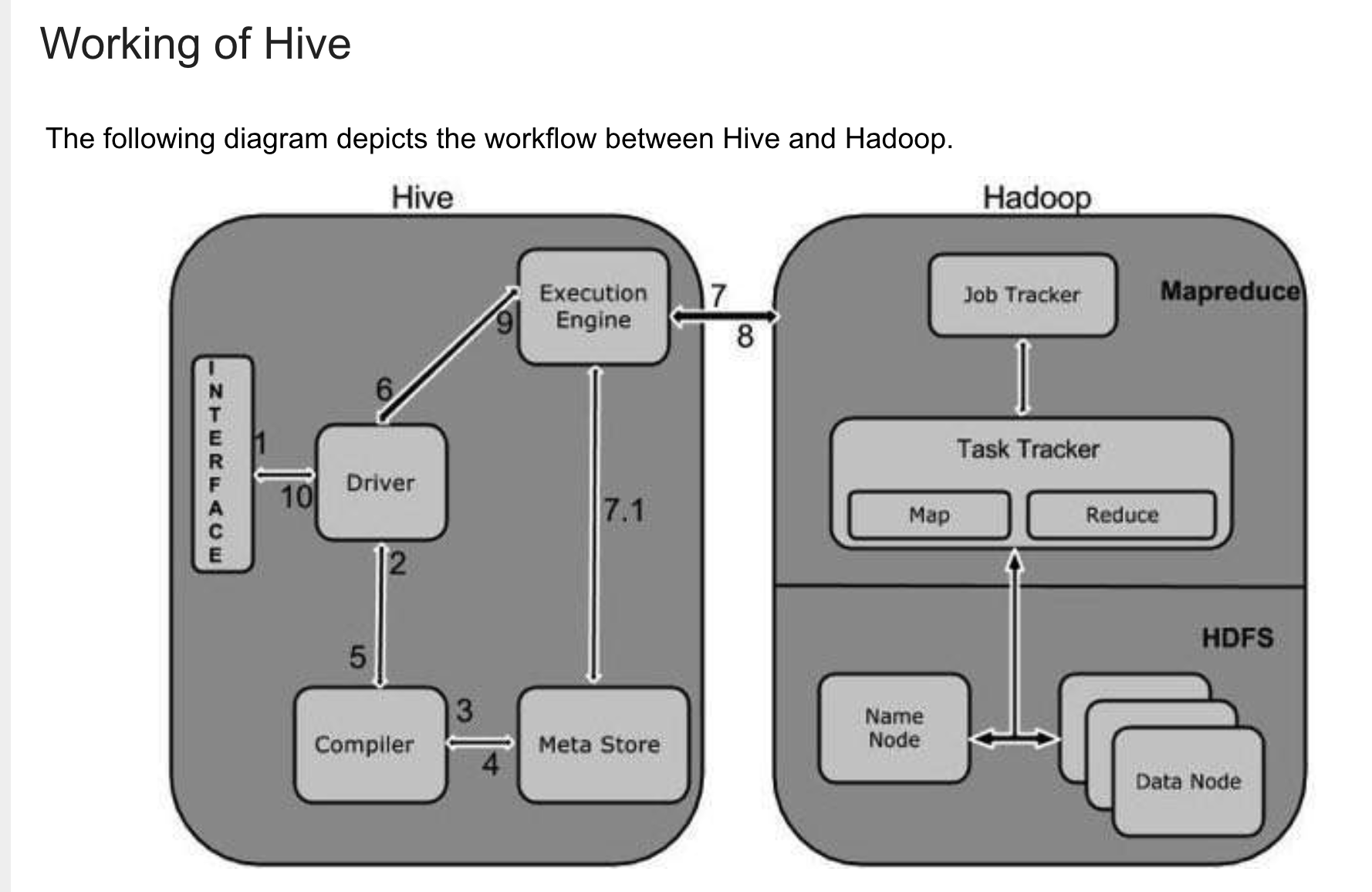
hive和hadoop的工作流
具体说明见👆的链接。
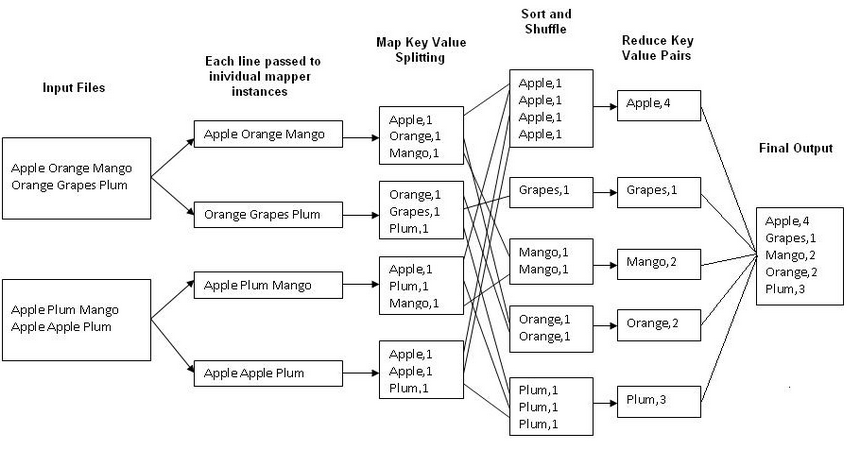
安装
java安装:
java官网下载网页:https://www.oracle.com/java/technologies/javase-jdk13-downloads.html
运行后,在terminal查看:java --version。可以看到版本号信息。
网上找的一篇安装文章:https://juejin.im/post/5d36d9ea6fb9a07ee16968f3 (还要进行配置?)
安装hadoop中的问题。
网上找的一篇安装文章: https://zhuanlan.zhihu.com/p/33117305 (对我无用, 第二条又尝试安装,)
使用这https://www.jianshu.com/p/3fff03cdd9ad
操:homebrew update。。。一直不动,又搞了1个小时。
brew unlink yarn
brew install hadoop 还是慢!
直接关闭brew每次执行命令时的自动更新:
vim ~/.bash_profile
# 新增一行 export HOMEBREW_NO_AUTO_UPDATE=true
安装不成功:❌失败
~ ⮀ brew install hadoop ==> Downloading https://www.apache.org/dyn/closer.cgi?path=hadoop/common/hadoop-3.2.1/hadoop ==> Downloading from http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/h ######################################################################## 100.0%
另辟蹊径
联系助教,让尝试finalshell这款产品。http://www.hostbuf.com/t/988.html
下载后又询问了一下如何连接的问题。密码必须手动输入,粘贴可能有其他占位符号。
可以正常用了。
第二天再次尝试安装hadoop。
https://zhuanlan.zhihu.com/p/33117305
发现下载的文件不对:
应当是hadoop-3.2.1,而不是hadoop-2.8.2-src(⚠️有个-src)。
解压
到/Users/chentianwei/hadoop/hadoop-3.2.1
添加环境变量:
vim ~/.bash_profile #添加: export HADOOP_HOME=/Users/chentianwei/hadoop/hadoop-3.2.1 export PATH=$PATH:$HADOOP_HOME/bin #:wq保存退出 #然后,在当前shell下运行这个脚本: source ~/.bash_profile
执行,表示成功。
~ ⮀ hadoop version Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /Users/chentianwei/hadoop/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
修改 Hadoop 的配置文件
有3种方法开始:
- Local (Standalone) Mode
- Pseudo-Distributed Mode(知乎上的文章搭建的是这个,步骤类似,但有区别)
- Fully-Distributed Mode
之后的暂时终止安装,毕竟太麻烦了。后续需要再学习吧。
2.7-8 Hive常用交互命令
hive -help 查看帮助信息
hive:
- --database <databasename> 指定数据库并进入hive。相当于进入hive,并使用use <database_name>
- -e <quoted-query-string> SQL from command line不进入交互窗口执行""内的sql语句。
- -f <filename> SQL from files 执行文件脚本中的sql语句。
在hive内:
1.退出用exit或quit
2. 在hive cli命令窗口中如何查看hdfs文件系统 executes a dfs command from the Hive shell
hive> dfs -ls /;
3.在hive cli命令窗口中查看本地文件系统, executes a shell command from the Hive shell!
hive>! ls; ⚠️!clear命令清空屏幕。需要加上!感叹号
4 在CLI内执行脚本文件
source <filepath>
例子:source /home/frog005/tian/try.sql;
2.9 Hive常见属性配置(略)
3 数据类型
3.1基本
| Hive数据类型 | Java数据类型 | 长 度 | 例 子 |
| tinyint | 1byte有符号整数 | 20 | |
| smallint | 2byte | ||
| int | 4byte | ||
| bigint | 8byte | ||
| boolean | TRUE / FALSE | ||
| float | 单精度浮点数 | ||
| double | 双精度浮点数 | ||
| string | 可变字符串。可指定字符集 | “hello” 'world' | |
| timestamp 或date | 时间类 |
3.2集合类型
| 类 型 | 描述 | |
| struct | 可以通过点符号访问集合中的元素 | struct<col_name: data_type [comment col_comment], ...> |
| map | 一组键值对儿元组集合(key, value)。 通过字段名获取值 | map<primitive_type, data_type> |
| array | 一组相同类型和名次的变量的集合,有编号从0开始 | Array<data_type> |
可以进行无限制层次嵌套。
例子:
1.假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为

2我们在Hive里创建对应的表,并导入数据。 创建本地测试文件test.txt:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
⚠️注意:MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
- array是相同类型的字符串。
- map结构是元祖的键值对儿,比如上面的xiao song:18_xiaoxiao song:19
- struct结构数据,只有值,key是存在于表结构中。
3. Hive上创建测试表test
create table test_1(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
- row format delimited fields terminated by ',' -- 列分隔符
- collection items terminated by '_' --MAP, STRUCT, ARRAY 三种集合类型的分隔符(数据分割符号)
- map keys terminated by ':' -- MAP中的key与value的分隔符
- lines terminated by '\n'; -- 行分隔符
4. 导入文本数据到测试表:
load data [local] inpath '/opt/test.txt' [overwrite] into table <表名>
- overwrite: 覆盖掉原来的数据。
hive> load data local inpath '/home/frog005/tian/test_1.txt' into table test_1; Loading data to table test.test_1 OK Time taken: 1.948 seconds hive> select * from test_1; OK test_1.name test_1.friends test_1.children test_1.address songsong ["bingbing","lili"] {" xiao song":18,"xiaoxiao song":19} {"street":"hui long guan","city":"beijing"} yangyang ["caicai","susu"] {"xiao yang":18,"xiaoxiao yang":19} {"street":"chao yang","city":"beijing"} Time taken: 0.644 seconds, Fetched: 2 row(s)
5. 访问三种集合列的数据:
select friends[1], child['xiao song'], address.city from test where name="songsong"
3.3类型转换
-
隐式类型转换规则
-
任何整数类型都可以隐式地转换为一个范围更广的类型
-
所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE
-
TINYINT、SMALLINT、INT都可以转换为FLOAT
-
BOOLEAN类型无法做转换。
- 使用CAST,可以强制转换,如果失败则返回空值NULL。例子:
//转化成功: hive> select CAST(12 AS float); OK _c0 12.0 Time taken: 0.226 seconds, Fetched: 1 row(s) //转化失败,返回NULL hive> select CAST("hello" AS float); OK _c0 NULL Time taken: 0.222 seconds, Fetched: 1 row(s)
第4章 DDL数据定义
创建数据库:
创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
避免要创建的数据库已经存在错误,增加if not exists判断
create database if not exists db_hive2 location '/db_hive2.db'; #location指定数据库存放的位置。
过滤显示查询的数据库
hive> show databases like 'db_hive*';
查看当前数据库:
hive>select current_database();
或者使用set,在命令行显示当前数据库:
set hive.cli.print.current.db=true;
查看数据库详细信息:
hive> desc database db_hive; #查看更多的信息 hive> desc database extended db_hive;
修改数据库信息:
使用alter database和dbproperties设置键值对儿的属性值。
⚠️数据库信息:名字,数据库所在位置都不能改。
alter database db_hive set dbproperties("createtime"='20200227'); hive> desc database extended db_hive; OK db_name comment location owner_name owner_type parameters db_hive hdfs://localhost:9000/user/hive/warehouse/db_hive.db frog005 USER {createtime=20200227}
4.51管理表Managed_table
Table Type: MANAGED_TABLE
默认创建的表都是所谓的管理表,即内部表,
当删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
根据查询结果创建表(被查询表的结构和查询结果会被添加到新创建的表中):create table as Select
hive (db_hive)> create table if not exists student2 as select name, address from test;
根据已经存在的表结构创建表:create table like
hive (db_hive)> create table if not exists student3 like student2;
查询表的类型:
- desc <table_name>
- 如果查询详细信息: desc formatted student2
4.52外部表 External Tables
1 使用external可以创建一个表,使用location提供数据。create external table 表名() location "路径"
当删除drop外部表时,只会删除表的描述信息(元数据信息),数据文件不会从文件系统中删除。除非进行额外的属性设置。
- 外部表可以使用任意HDFS location来储存数据。
- 不会由配置属性hive.metastore.warehouse.dir来储存在指定的文件夹内。
- 如果不指定location,则在warehouse中新建目录。
2.管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
3.例子:
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
4.6 分区表Partitioned tables
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。
Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。
在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
使用partitioned by(key, type[, state string])子句。
- 可以有一个或多个分群列
- 分区本质就是建立一个独立的数据目录
- 可以有2级子目录。
例子:
//1。 创建一个带分区的表格,相当于在location位置创建了一个目录 //2。 增加分区:每增加一个分区,就是增加一个目录。 //3。 导入数据根据条件,放到不同的目录中。 查询数据根据where条件去不同的分区查数据。 hive>create table Student(col1 string, col2 string) partitioned by (dept string); hive> alter table student add partition(dept='cse'); hive> alter table student add partition(dept='china');
hive> load data local inpath "/home/frog005/tian/test_1.txt" into table student partition(dept='usa');
有多种方法上传数据,上面的是使用load data的方法。
还有, 加载HDFS文件到hive中:
首先,创建文件夹:
dfs -mkdir -p /user/hive/warehouse/db_hive.db/student/month=2;
然后,上传文件到hdfs
//dfs -put 数据路径 存储数据的hive文件夹 hive>dfs -put /home/frog005/tian/student.sql /user/hive/warehouse/db_hive.db/student/month=2;
但是,此时表还没有和数据所在文件夹关联:
#所以需要消费 msck repair table 表名 #之后即可使用查询了 hive> select * from student where month=4;
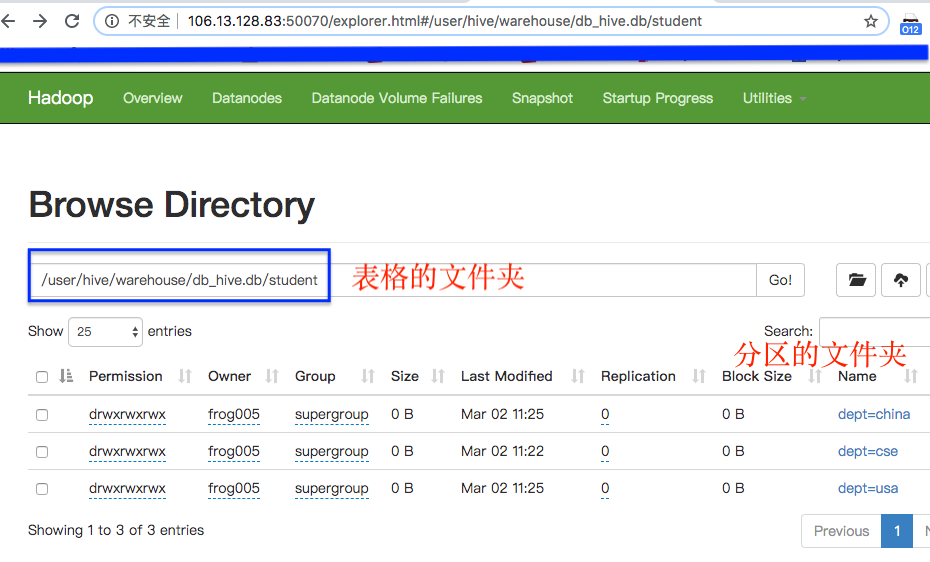
删除分区用alter table 表名 drop partition(xx="yy");
查看分区:
- 用hdfS : http://106.13.128.83:50070/explorer.html#/user/hive 进入对应的文件夹目录
- 或者使用:hive> show partitions 表名
hive> show partitions student; OK partition dept=china dept=usa Time taken: 0.086 seconds, Fetched: 2 row(s)
4.7修改表
重命名:
alter table student2 rename to student_2;
增加列:
alter table student3 add columns(password string comment 'enter password');
⚠️和mysql的写法区别:“alter table 表名 add 列名 列类型;”
修改列的信息(列名/类型/注释等。。还包括移动到某个列后面):
# alter table 表名 change [column] 旧列名 新列名 类型 [comment '描述信息'] [after 已存在的列的列名| first]
alter table student3 change [column] password pass string comment "password";
⚠️:列的数据类型的修改必须符合类型转化的规则,比如string类型不能转化为int类型,强行转化会报告❌。
⚠️:和mysql的写法类似:“alter table 表名 change 字段名称 新字段名称 新字段定义;”
add或替换列信息:
alter table student_2 replace columns(dname string, location struct<street:string, city:string>);
⚠️替换时列时我遇到多次报错❌。 replace先把现存的列都删除,然后重新添加新的列。但我遇到多次错误,所以要参考wiki。
删除表:drop table 表名;
-
会把内部表的location位置储存的数据一起删除。
- ⚠️只删除外部表的元信息。即使用create external table 命令创建的外部表的location位置储存的数据不会被删除。
- 这是因为,外部表一般应用于这个场景: 从hdfs取数据,创建一个外部临时表(使用location参数获得数据),用这个表做数据分析,只进行查询操作。当不用这个表后,删除它,但location的数据源需要保留,所以drop默认不会删除locatio数据源。
修改表的属性:
alter table 表名 set tblproperties(属性名=value, 属性名=value, ...)
例子:
alter table t_1 set tblproperties('comment' = "xxxxxxxxxxx");
# 修改表的分隔符号 alter table t_1 set tblproperties('field.delim'=',');
可以使用 <desc t_1>看已经有的表属性:
Table Parameters: comment xxxxxxxxxxx field.delim , last_modified_by frog005
修改分区表的属性
alter table 表名 partition(dt="xxxx") set serdeproperties ('field.delim'='\t')
⚠️这种方式针对的是已经存在的分区数据。因为使用set tblproperties是没办法对已经分区的表的数据进行修改的。
修改location
alter table 表名 [partition()] set location()
⚠️partition()为一个分区指定其他的目录。
查看hive数据存储位置:
首先在hive中使用
desc formatted 表名
然后找到存储路径:
# Detailed Table Information Database: db_hive Owner: frog005 CreateTime: Fri Feb 28 11:06:30 CST 2020 LastAccessTime: UNKNOWN Retention: 0 Location: hdfs://localhost:9000/user/hive/warehouse/db_hive.db/test
最后, 在terminal上使用hadoop fs 来查询。
[frog005@instance-grq6ue3x ~]$ hadoop fs -ls /user/hive/warehouse/db_hive.db/ # drwxrwxrwx - frog005 supergroup 0 2020-02-28 11:15 /user/hive/warehouse/db_hive.db/student3 drwxrwxrwx - frog005 supergroup 0 2020-02-28 11:07 /user/hive/warehouse/db_hive.db/test drwxrwxrwx - frog005 supergroup 0 2020-03-01 11:30 /user/hive/warehouse/db_hive.db/test1
或者在hive中使用: dfs -ls <路径>
查看函数帮助信息:
show functions [like '*month*']; desc function [extended] <函数名字>;
5.12通过查询语句向表中插入数据(Insert)
一般用法:
insert [overwrite|into] table [partition()]
表名 select col1,... from 表名 where...
多行插入:
from 表名
insert [overwrite|into] table 表名 [partition()]
select col1,... where
1.创建一张分区表
hive (default)> create table student(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';
2.基本插入数据
hive (default)> insert into table student partition(month='201709') values(1,'wangwu');
3.基本模式覆盖原数据(根据单张表查询结果)⚠️需要指定字段fielde,否则报告❌。
hive (default)> insert overwrite table student partition(month='201708') select id, name from student where month='201709';
4.多插入模式(根据多张表查询结果)
hive (default)> from student insert overwrite table student partition(month='201707') select id, name where month='201709' insert overwrite table student partition(month='201706') select id, name where month='201709';
Hive不同文件读取对比:
- stored as textfile
- 直接查看hdfs
- hadoop fs -text
- stored as sequencefile
- stored as rcfile
- stored as inputformat 'class'自定义格式
hive使用SerDe来存取数据:
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe
InputFormat: org.apache.hadoop.hive.ql.io.RCFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.RCFileOutputFormat

Hive bucket 分桶
官网说明:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL+BucketedTables
-
对表/分区,进一步组成桶。
-
针对某一个列
-
获得好的查询效率
-
sampling取样本更高效✅
CLUSTERED BY and SORTED BY 不会影响数据的插入,只会影响数据的读取。
所以插入数据时,应当指定桶号。
⚠️新版本会默认是分桶的,所以不用设置参数。
例子:
create table bucketed_user(id string, name string)
clustered by (id) sorted by(name) into 4 buckets
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
插入数据:
hive> insert overwrite table bucketed_user select id, name from student;
其他:(具体见插入👆)
hive (db_hive)> insert into table student1 > partition(month=1) > select id, name from student where month=1;
分桶之取样:(点击见wiki)
语法: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
select * from bucketed_user tablesample(bucket 1 out of 2 on id) #bucket 1 out of 2: 意思是从2部分桶中拿每部分的第1个桶。
解释:
tablesample子句让用户从抽样的数据中写查询,而不是从整个表的数据。
这个子句位于from子句中
桶从1.colname开始编号, 表示这个列从表中取样的位置。
colname可以是:非分区列,或者用rand()从整行中取样。
行rows基于colname被分桶,随机的被分配到从1到y的桶中。然后再从中拿出x个桶。
和clustered by配合使用
tablesampe当然可以扫描整个表然后取样,但是这样效率太差。所以,和由clustered by创建的表配合进行样本取样。
- 创建分桶的表
- 查询时tablesample中的column必须和colustered by中的列一样。
例子:
#1.使用CLUSTERED BY id INTO 32 BUCKETS创建了分成32个桶的表。
#2.TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)
#3. 32/16=2 。把32个桶分成A,B两个部分,每部分有16个桶。
#4. 然后,从每部分取出这个部分的第3个桶。即:桶号3和19
分桶之join(默认false)(实际工作中很少用)
关联条件:
- 如果被连接的表的关联列是都被分桶的列。
- 并且一个表的桶的数量是另一个表的桶的数量的倍数,桶可以关联一起。
这些操作会在mapper上完成。
默认这个功能是是false的需要设置参数:
set hive.optimize.bucketmapjoin=false
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
在hive内设置变量。
hive> set a=2; hive> set a;
使用变量 “${a}”
使用环境变量"${env:HOME}"
hive> select "${env:HOME}" from business;
Hive数据加载
1创建表时使用select导入数据
2创建表时指定数据位置location
# "/user/hive/warehouse/db_hive.db/new"是文件夹。 hive (db_hive)> create table new2 like test > location "/user/hive/warehouse/db_hive.db/new";
3本地加载数据(非hdfs数据)
load data local inpath 'localpath' [overwrite] into table table_name [partition()]
hive (db_hive)> load data local inpath '/home/frog005/tian/test_1.txt' > into table new;
⚠️这类的inpath路径是file:文件系统下的文件。
4hdfs数据加载:(移动,粘贴)
load data inpath '/user/hive/warehouse/db_hive.db/test/test_1.txt' into table 目的表名;
⚠️这里没有local关键字。把HDFS数据移动到你的表location属性指定的目录。原位置数据被移除!!!
5使用hadoop fs -put <src> <destination_localfile>命令。(等同-copyFromLocal) 复制本地文件并粘贴到hdfs系统下的目录。
hive (db_hive)> dfs -put /home/frog005/tian/student.sql > /user/hive/warehouse/student5;
从👆3,4理解关于local关键字
⚠️'/user/hive/warehouse/db_hive.db/test/test_1.txt'是hdfs系统下的文件。不是本地文件,所以报告❌:
hive (db_hive)> load data local inpath '/user/hive/warehouse/db_hive.db/new/test_1.txt' > into table test; FAILED: SemanticException Line 1:23 Invalid path ''/user/hive/warehouse/db_hive.db/new/test_1.txt'':
No files matching path file:/user/hive/warehouse/db_hive.db/new/test_1.txt
我的理解:
- local代表的是非hdfs数据。而inpath是hdfs路径。
- file:/user/hive/warehouse/db_hive.db/new/test_1.txt。开头的file:代表了是普通的文件系统。
- hdfs://localhost:9000/user/hive/warehouse/db_hive.db/new 开头是hdfs:代表了是hdfs文件系统。
可以对比一下:
- 没有使用local关键字,那么系统默认inpath路径是hdfs路径。
- 这时,你要是用非hdfs文件,就会报错❌。
hive (db_hive)> load data inpath '/home/frog005/tian/test_1.txt' > into table new; FAILED: SemanticException Line 1:18 Invalid path ''/home/frog005/tian/test_1.txt'':
No files matching path hdfs://localhost:9000/home/frog005/tian/test_1.txt
load命令可以反复导入同一个源文件,并重新命名加上后缀_copy_1:

Hive数据导出
Hadoop方式:
- hadoop fs -help [某个命令] 帮助信息/某个命令的帮助信息。
- -get <src> ... <localdst>命令, 等同于-copyToLocal命令。
-
例子: $ hadoop fs -get /user/hive/warehouse/score/* /home/frog005/tian ⚠️*代表文件夹下的所有文件。
-
- -text [-ignoreCrc] <src> 直接打印在屏幕
-
$ hadoop fs -text /user/hive/warehouse/score/* > 自定义的文件名 ⚠️使用重定向符号>把数据输出到一个文件。
-
-
-put 命令: 和get命令正相反,把本地文件存入hds系统中。
- -rm,⚠️和linux命令有很多用法一样。
使用insert overwrite [local] directory '路径'命令
加上local,移动到本地目录,Moving data to local directory /home/frog005/chen1
insert overwrite local directory '/home/frog005/chen1' row format delimited fields terminated by '\t' select name, score from score;
去掉local, 移动到hdfs目录,Moving data to directory hdfs://localhost:9000/home/frog005/chen1/.hive-staging_hive_2020-03-03_17-00-08_974_7480549450822926146-1/-ext-10000
使用shell命令加管道:hive -f/e | grep/sed/awk > file
第三方工具:sqoop
HIve动态分区插入dynamic partition insert
上面的分区一章,告诉我们如果要插入多个分区可以使用from table_name [...]的语法格式。
但是,如果针对如国家,地区等分区,想想世界上有多少个国家吧,你可不想一条一条命令的输入,太麻烦了!!!
看这个文档的例子:https://cwiki.apache.org/confluence/display/Hive/Tutorial#Tutorial-Dynamic-PartitionInsert
使用动态分区的配置参数:(点击见参数文档)
set hive.exec dynamic.partition=true (默认就是true,无需手动设置)
set hive.exec.dynamic.partition.mode=nonstrick//无限制模式,默认模式是strict,这时表结构必须有一个静态分区,且放到最前面。
- static partiton简称SP
- dynamic partition简称DP
In INSERT ... SELECT ... queries, 在select声明内,动态分区列必须在所有列的最后,并且,和出现在partition()子句的顺序一样。
INSERT OVERWRITE TABLE T PARTITION (ds, hr)
SELECT key, value, ds, hr FROM srcpart WHERE ds is not null and hr>10;
其他语法:https://cwiki.apache.org/confluence/display/Hive/DynamicPartitions
例子:
create table dy_children (
name string)
partitioned by(id int, month string)
row format delimited fields terminated by '\t'
lines terminated by '\n';
#现成儿的表 hive (db_hive)> desc children; OK col_name data_type comment id int name string month string
动态分区:先以id分区,然后再以month分区:
insert overwrite table dy_children partition(id, month)
select name, id, month from children;
在严格模式下,如何动态分区?
hive> insert overwrite table s_part partition(id, month) > select name,id,month from children; FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column.
To turn this off set hive.exec.dynamic.partition.mode=nonstrict
上面的例子报告错误了。因为此时s_part并没有静态分区。
正确的写法,先指定静态分区:
hive> insert overwrite table s_part partition(id=1, month)
> select name, month from children where id=1; ⚠️select后面没有id列
hive> show partitions s_part; OK partition id=1/month=202001 id=1/month=202002 id=1/month=202003 id=1/month=202004
如何删除分区?
会连带数据一起删除。
hive (db_hive)> alter table s_part drop partition (id>=1);
可以使用>, <, <>来设置条件。
也可以使用:hive> alter table t drop if exists partition (p=1),partition (p=2),partition(p=3);
Hive 高级查询
Hive2.0函数大全(中文版)
https://www.cnblogs.com/MOBIN/p/5618747.html
查询操作:
- group by
- order by
- join
- distribute by, 可以和sort by结合进行局部排序。
- sort by
- cluster by, 可以和sort by结合,按照桶进行排序。
- Union by
底层用Mapreduce实现。
聚合函数
count(*), 不会计算有null值的记录。
count(1), 每列都+1
count(列),类似count(*)
sum(), 返回bigint.
- sum()不能和int相加,必须先类型转化: sun()+ cast(1 as bigint)
avg(), 返回double
distinct 不同值的数量: count(distinct col)
Order by
全局排序。
后面可以有多列: order by col1 [asc| desc], col2 [asc | desc], ..
可以决定null值放到表头或表尾:nulls first | nulls last
⚠️数据量大的时候,不要用order by,因为需要reducer,且只能有一个reducer来整理最后的输出,如果数据太大,单一的reducer会花费很长时间来完成。另外还容易导致内存溢出。
⚠️hive.mapred.mode参数默认是nonstrict的,但是,改为strict后,order by必须和limit子句配对儿使用。
流程:
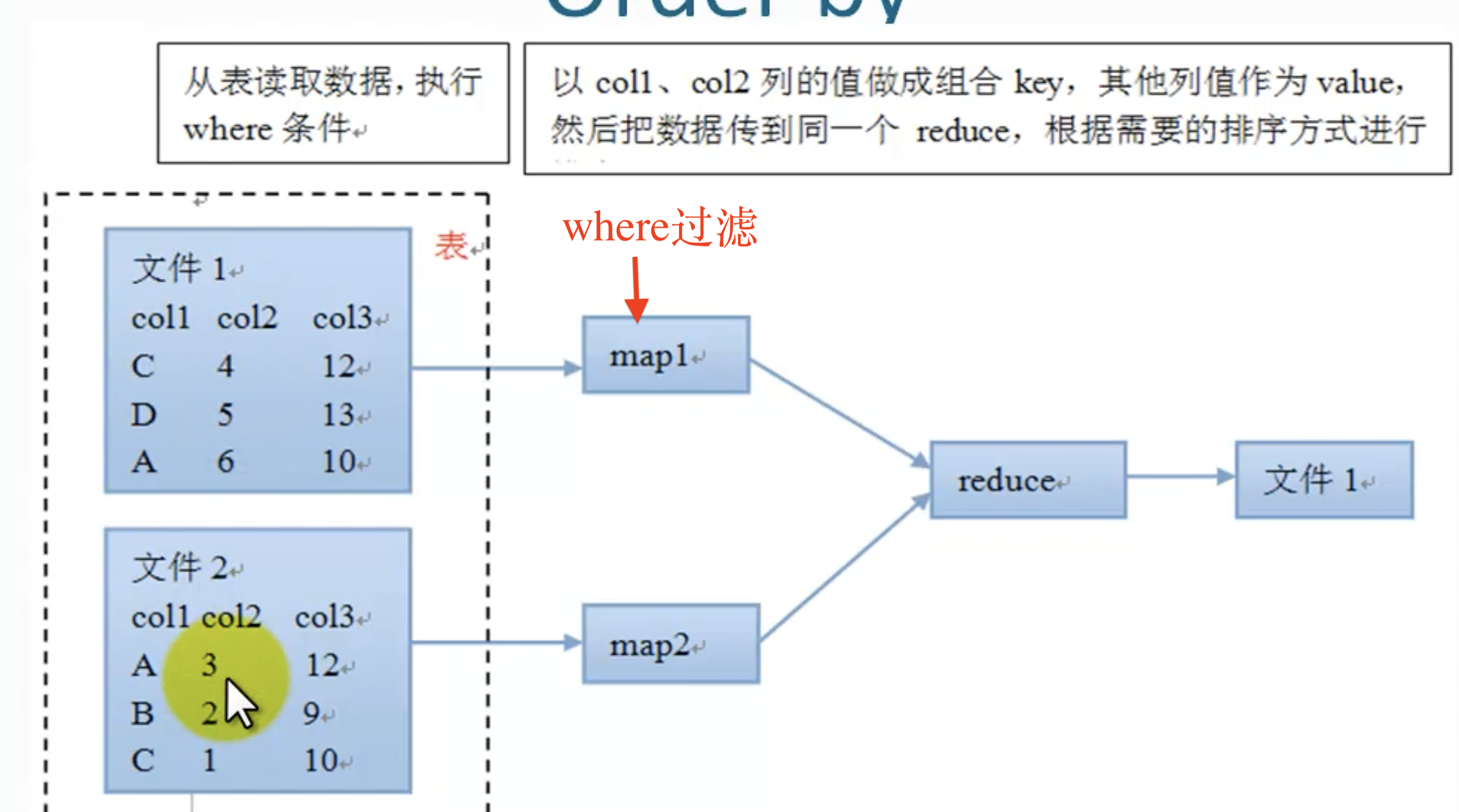
Sort By
和order by 的语法类似 。一般用在列上,用在产生reduce之前。
和order by的区别: order by 作用于一个reducer, 而sort by作用于各个独立的reducer.
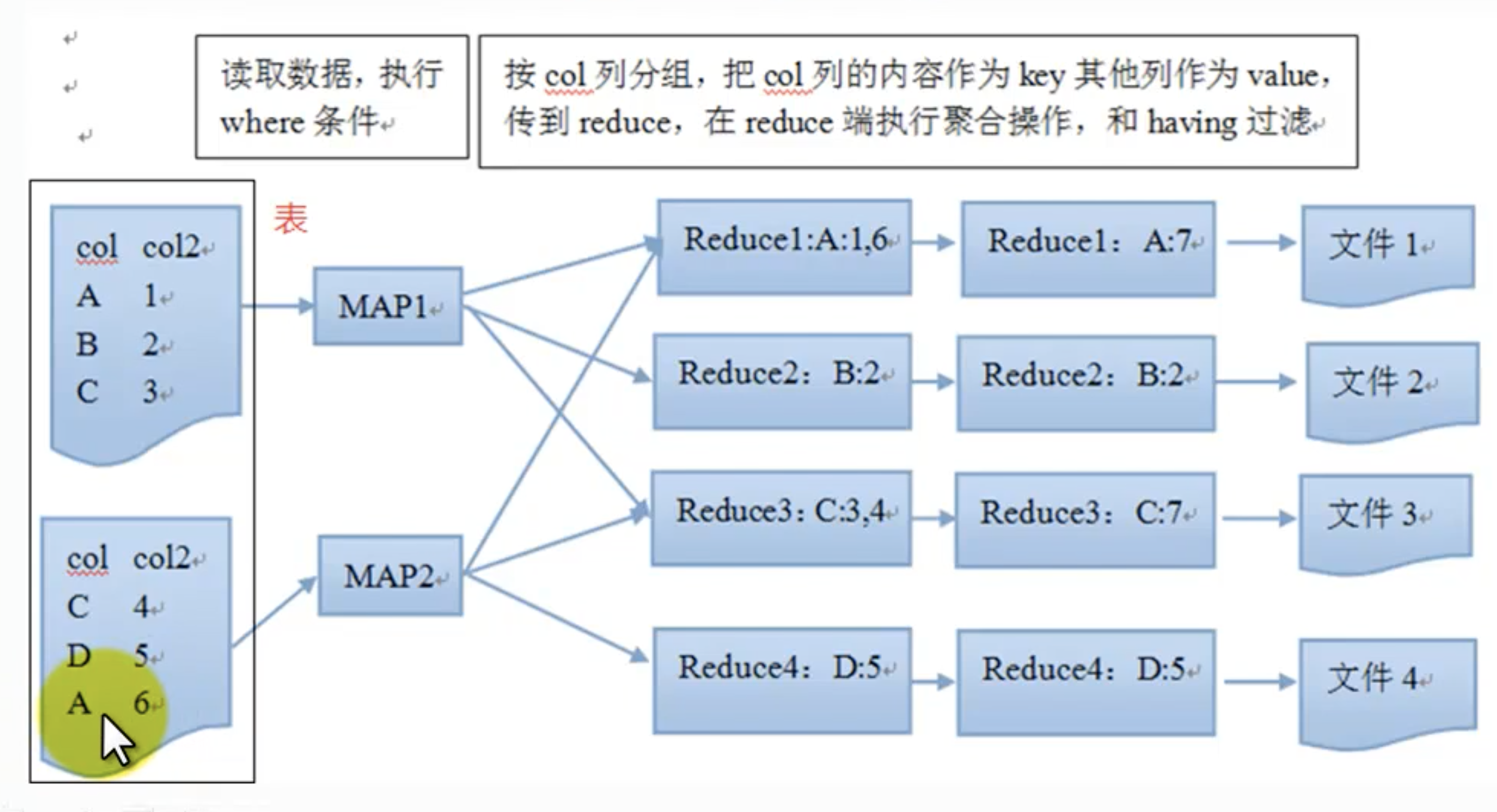
group by

使用了reduce,在reduce上进行 。受限于reduce数量,设置reduce参数set mapred.reduce.tasks = 5
输出文件个数和reduce数量相同。(数据清洗时)
问题:
网络负载过重
数据倾斜,一份数据分成5分reduce, 其中一份reduce中的数据占总数据的99%,那么其他reduce执行完成了,它却仍在执行。
使用优化参数, 可以启动2个job:hive.groupby.skewindata
流程:
Join
join 相当于内连接。(等值连接)
left [oute] join
right [outer] join
full join 就是left和right的组合,不符合的记录值用null表示
left semi join 类似exists https://www.cnblogs.com/chentianwei/p/12132268.html
mapjoin, 在map端完成join操作,不需要使用reduce, 基于内存做连接,属于优化操作。
例子:

参数设置: set hive.optimize.skewjoin =true;
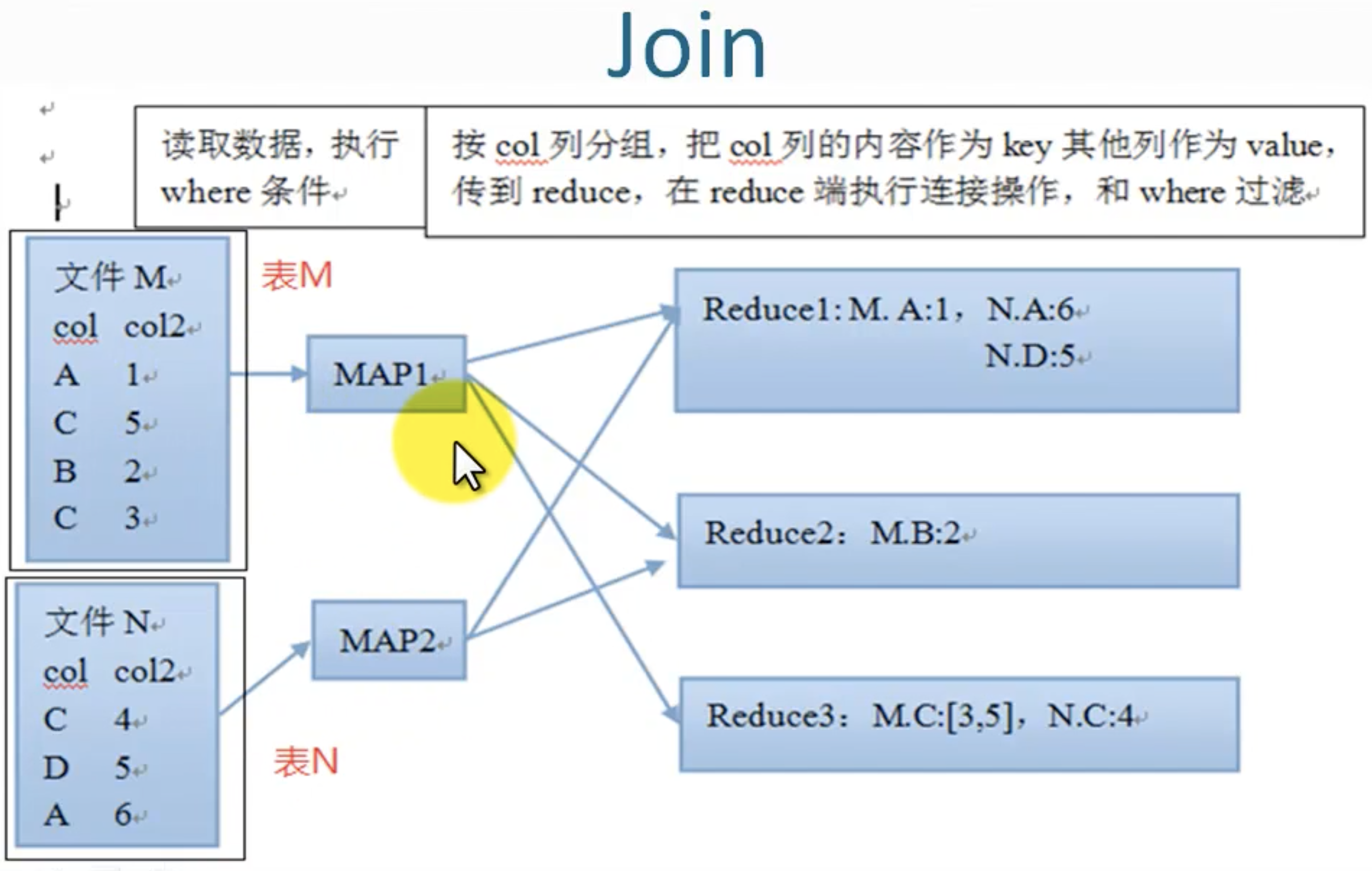
例子:
hive> select * from m; OK m.col1 m.col2 1 a 5 c 2 b 3 c hive> select * from n; OK n.col3 n.col4 4 c 5 d 6 a
内连接:
select t1.col1, t1.col2, t2.col3, t2.col4 from (select * from m)t1 join (select * from n)t2 on t1.col2=t2.col4 结果: t1.col1 t1.col2 t2.col3 t2.col4 1 a 6 a 5 c 4 c 3 c 4 c
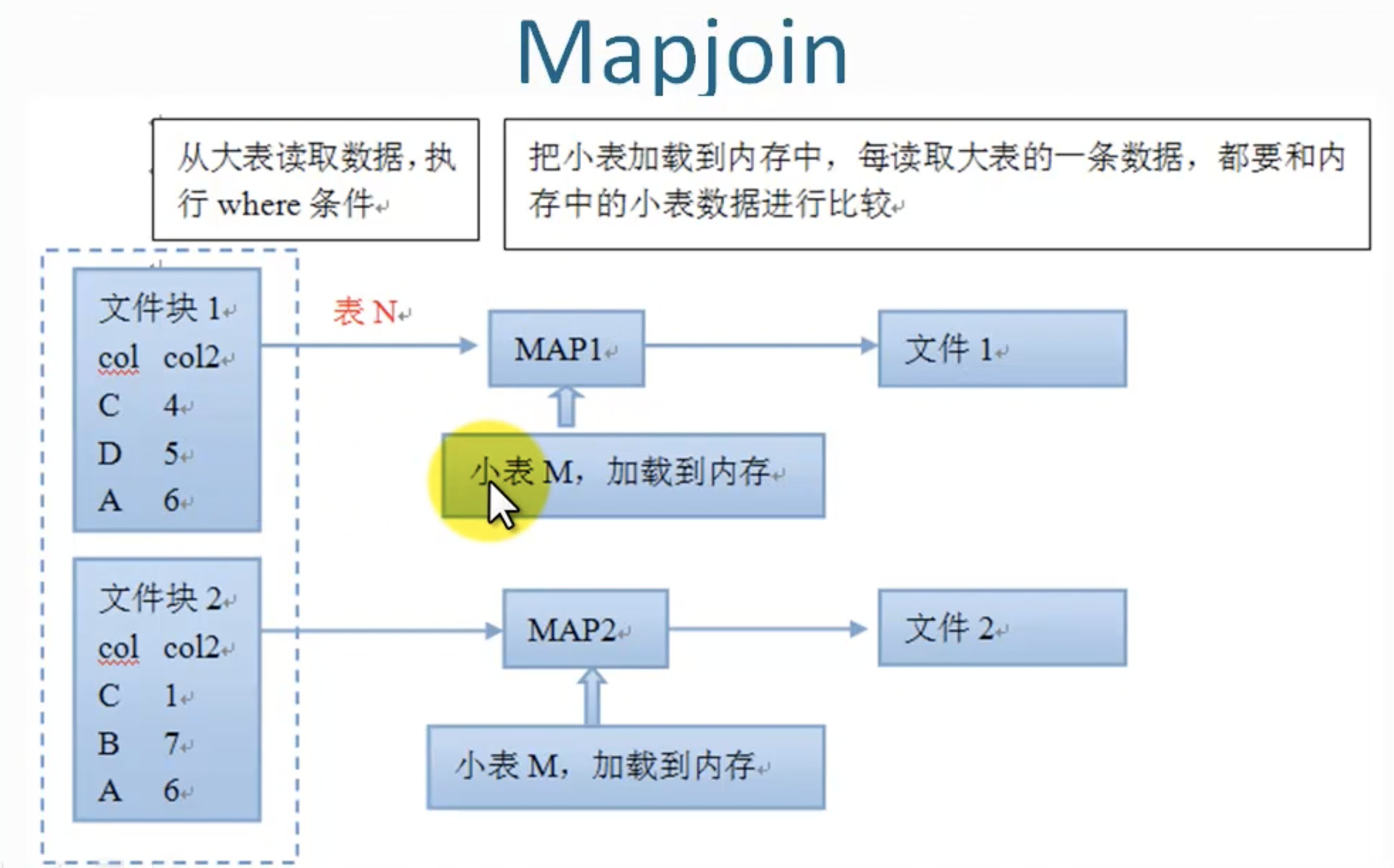
在map端把小表加载到内存,然后读取大表,和内存的小表完成连接,使用了分布方式缓存技术。
优缺点:
- 不消耗reduce资源,减少了reduce操作,加快了程序执行。
- 降低了网络负载。
- 占用内存,所以加载的表不能太大,因为每个计算节点都会加载一次。
- 生成较多的小文件。

Distribute by
应用场景:
真对map, reduce输出文件的大小不均匀,比如小文件过多,或者有个别文件超大。
这时就可以用distribute by打散数据,让输出的文件们中的数据分布均匀一些。
distribute 分散发数据
distribute by column, 按照列把数据分数到不同的reduce
结合sort by, 保证每个reduce的输出是有序的。
select col1,col2 from M distribute by col1 sort by col1 asc, col2 desc;
distribute by和group by:
- distribute by只是用于散发数据,虽然它会把相同的value放到一个reducer内,但不保证都处于相邻的位置adjacent positions。
- group by没有散发功能。把相同数据聚合。
- 相同点:都是按照key来划分数据,都使用reduce。
distribute by 和sort by组合达到cluster by 的效果:
Cluster By is a short-cut for both Distribute By and Sort By. 把相同值的数据聚集到同一reducer,并排序。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
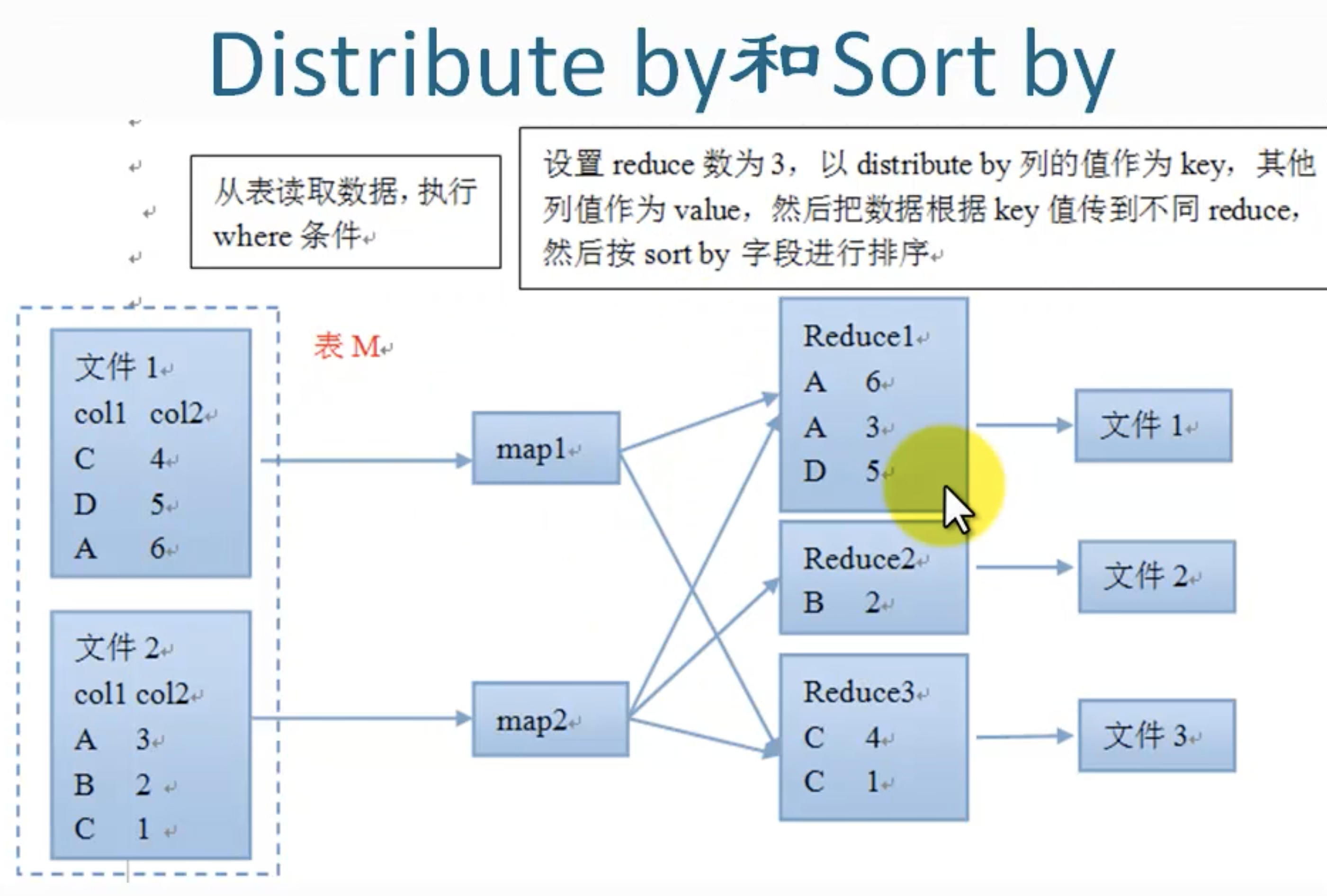
cluster by col效果等同:
distribute by col order by col
例子:⚠️参数设置!
set mapred.reduce.tasks =5;
insert overwrite table city
select time ,country, province, city from info
distribute by province
⚠️通过设置reduce数量,可以把多个reduce文件合并到一个文件。
Union all
多表合并。hive1.2之前版本不支持union。
⚠️union all 连接的表不能用别名。
没有reduce操作,速度快。
例子
select col from( select a as col from t1 union all select b as col from t2 ) temp
- 字段名字要一样,a和b字段设置相同的别名
- 字段类型要一样。
- 字段个数要一样。
- 子表不能有别名
- 合并的表要有别名:temp
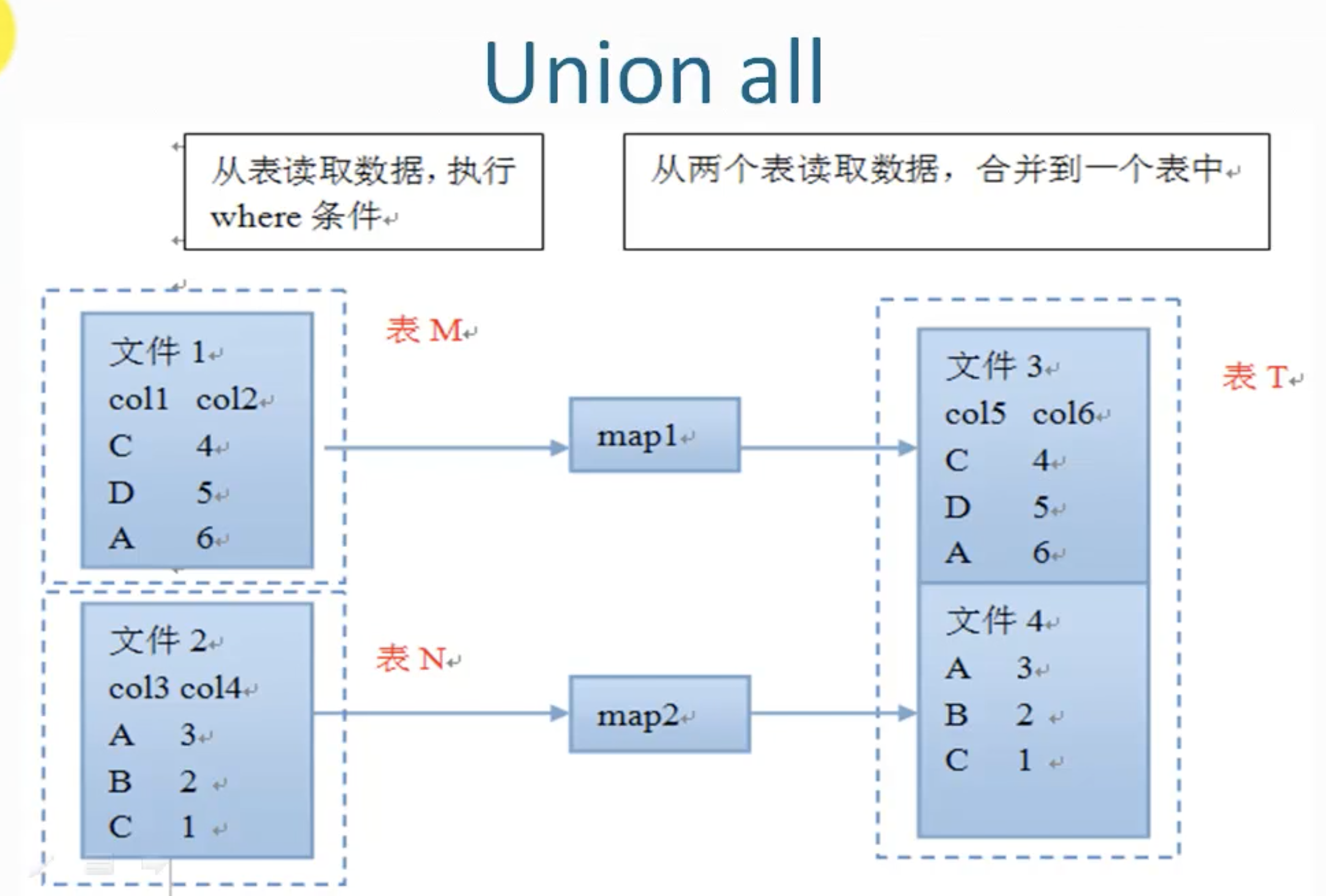
❌⚠️,创建表时使用的是field.delim='\n', 虽然使用参数改回\t,但是union all后还是产生null. 这是一个bug了。
select a, b from( select col3 as a, col4 as b from n union all select col3 as a, col4 as b from n ) tmp;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号