Mysql index索引
Mysql index索引
Mysql index使用了B tree算法来提高了数据库的搜索能力。
关于B树的知识可见 :平衡搜索树-B树
相关知识的学习途径:
强大的mysql学习网站: https://www.mysqltutorial.org/mysql-index/
凡人求索(简书)的一篇文章:https://www.jianshu.com/p/f588c41f1cb5
MySQL样本数据库下载(用于练习,导入.sql的方法见https://www.cnblogs.com/chentianwei/p/12142068.html)
备注:如果使用workbench,可以生成EER图,查看各个表的关联关系,或者从👆下载pdf.
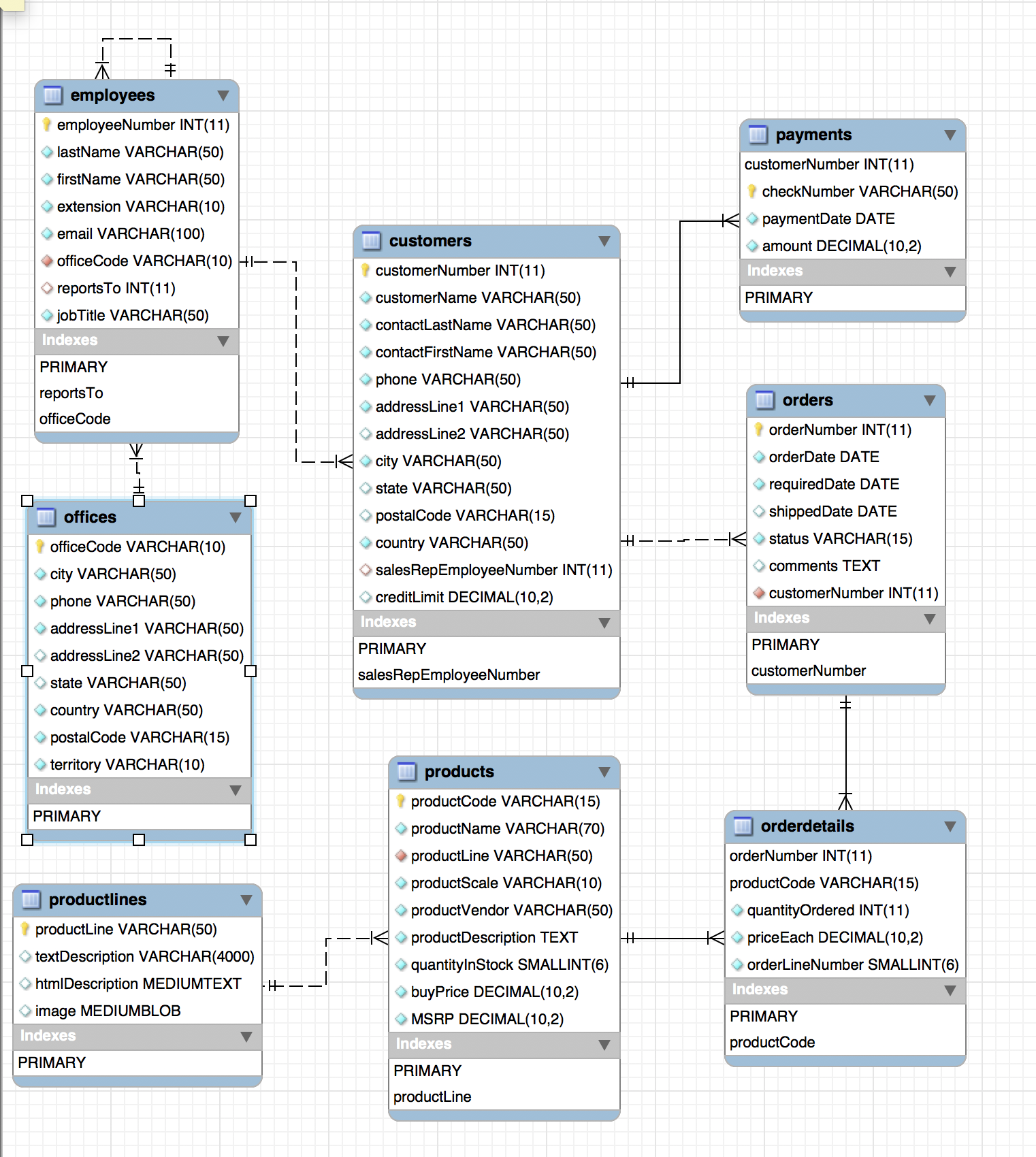
导入.sql完成后,开始练习下面语句:
mysql> explain select employeeNumber, lastName, firstName from employees where jobTitle = "Sales Rep"; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 23 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
这时,查询了23条语句, 而employees全表,也就23条语句,证明是全表扫描!
为字段jobTitle创建索引:
mysql> create index jobTitle on employees(jobTitle);
然后再查询:
mysql> explain select employeeNumber ,lastName, firstName from employees
-> where jobTitle = "Sales Rep";
+----+-------------+-----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | ref | jobTitle | jobTitle | 52 | const | 17 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
因为有了索引,where子句中的jobTitle就无需全表扫描了,只查看了17行。
查看索引
mysql> show indexes from employees;
⚠️可以加where子句进行查找比如where Non_unique = 0 +-----------+------------+------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-----------+------------+------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | employees | 0 | PRIMARY | 1 | employeeNumber | A | 23 | NULL | NULL | | BTREE | | | YES | NULL | | employees | 1 | reportsTo | 1 | reportsTo | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | officeCode | 1 | officeCode | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | employees | 1 | jobTitle | 1 | jobTitle | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | +-----------+------------+------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
可以看到索引使用了B树的算法。
- Non_unique: 0代表否,即这个列的每个值都是唯一的; 1代表是, 非唯一的。
- key_name: 索引名字。如果两个列有同一个索引名字,表示这两个列用一个联合索引。
- Seq_in_index: 索引中的序列序号,从1开始。
- Cardinality: 基数(表示有多少数量,和顺序无关),这里是对一列中的唯一值的估计值。如果这个值较高那么就适合使用索引。
- Null: 如果列含有Null,则Yes
- Index_type: 表示索引类型:BTree, RTree, Hash, FullText等。
- Expression: 索引使用表达式而不是列/列前置值。
删除索引
drop index key_name ON table_name;
上面的employees删除索引jobTitle:
mysql> drop index jobTitle on employees;
注意:如key_name是primary,就把主键删除了。
唯一性索引
primary key索引可以强制索引为唯一索引。但一张表只能有一个主键。
如果想要为其他列添加唯一的索引,需要使用unique index
mysql> create unique index idx_name on employees (firstName, lastName); mysql> show indexes from employees where Non_unique = 0; +-----------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-----------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | employees | 0 | PRIMARY | 1 | employeeNumber | A | 23 | NULL | NULL | | BTREE | | | YES | NULL | | employees | 0 | idx_name | 1 | firstName | A | 21 | NULL | NULL | | BTREE | | | YES | NULL | | employees | 0 | idx_name | 2 | lastName | A | 23 | NULL | NULL | | BTREE | | | YES | NULL | +-----------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
- Seq_in_index: 索引中的序列序号,从1开始。firstName是第一索引索引sqe_in_index是1。
或者使用(都可以创建unique key):
alter table employees add constraint idx_name unique key(firstName, lastName);
Prefix index 前缀索引
为一个列创建一个索引,Mysql使用Btree或hash算法。如果这个列的数据类型是字符串,那么索引会消耗大量磁盘空间,并且会潜在底降低插入insert操作的效率。
为了优化这个问题,我们可以使用Prefix index。这种优化其实就是规定一个字符串长度len,这个len会小于绝大部分列的字符串的长度,每个字符串的前len部分会被创建为索引值,这样就会减少磁盘空间的消耗了。
这是一个技巧性的优化。
例子:使用products表
mysql> SELECT -> productName, -> buyPrice, -> msrp -> FROM -> products -> WHERE -> productName LIKE '1970%'; +----------------------------+----------+--------+ | productName | buyPrice | msrp | +----------------------------+----------+--------+ | 1970 Plymouth Hemi Cuda | 31.92 | 79.80 | | 1970 Triumph Spitfire | 91.92 | 143.62 | | 1970 Chevy Chevelle SS 454 | 49.24 | 73.49 | | 1970 Dodge Coronet | 32.37 | 57.80 | +----------------------------+----------+--------+
用explain分析一下:
mysql> explain SELECT productName, buyPrice, msrp FROM products WHERE productName LIKE '1970%'; +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | products | NULL | ALL | NULL | NULL | NULL | NULL | 110 | 11.11 | Using where | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
发现row是110行。mysql进行了全表扫描。
在实际工作中,如果对productName的查询非常频繁,那么就要给他加上一个索引了。
create index idx_productName on products(productName)
但是,因为它是字符串类型的列,我们可以优化一下:使用Prefix index。
方法:
1. 查看这个列创建时的长度:varchar(70)。
mysql> desc products; +--------------------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------------+---------------+------+-----+---------+-------+ | productCode | varchar(15) | NO | PRI | NULL | | | productName | varchar(70) | NO | | NULL | | | productLine | varchar(50) | NO | MUL | NULL | | | productScale | varchar(10) | NO | | NULL | | | productVendor | varchar(50) | NO | | NULL | | | productDescription | text | NO | | NULL | | | quantityInStock | smallint(6) | NO | | NULL | | | buyPrice | decimal(10,2) | NO | | NULL | | | MSRP | decimal(10,2) | NO | | NULL | | +--------------------+---------------+------+-----+---------+-------+
2. 估计一下,一般用多长的字符串,这里估计20,发现可以包括全部的110条记录。
mysql> select count(distinct left(productName, 20)) from products; +---------------------------------------+ | count(distinct left(productName, 20)) | +---------------------------------------+ | 110 |
3. 所以使用len: 20。 ex
explain SELECT productName, buyPrice, msrp FROM products WHERE productName LIKE '1970%';
+----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | products | NULL | range | idx_productName | idx_productName | 72 | NULL | 4 | 100.00 | Using index condition | +----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号