Mysql8.0的新特点:with声明, 窗口函数
Mysql8.0的新特点
1-6号更新:窗口函数的frame_clause的使用
with声明
https://dev.mysql.com/doc/refman/8.0/en/with.html
也叫做common table expression。(CTE)
CTE是一个命名的临时结果集合,用在一个声明的内部,可以被多次反复使用。非常类似sql5.7的衍生表(derived table)
WITH cte AS (SELECT 1) SELECT * FROM cte; SELECT * FROM (SELECT 1) AS dt;
本文只是简单的介绍一下。
CTE的用途就是优化查询sql的方法。见这篇文章:Section 8.2.2.4, “Optimizing Derived Tables, View References, and Common Table Expressions with Merging or Materialization”.
Common Table Expressions
使用with子句和1个或几个逗号分隔的子句。每个子句提供一个子查询,子查询产生一个结果集合,给这个集合设置一个名字。例子:
mysql> with -> sc_60 as (select * from SC where score >= 60) -> select * from sc_60; +------+------+-------+ | SId | CId | score | +------+------+-------+ | 01 | 01 | 80.0 | | 01 | 02 | 90.0 | | 01 | 03 | 99.0 | | 02 | 01 | 70.0 | | 02 | 02 | 60.0 | | 02 | 03 | 80.0 | | 03 | 01 | 80.0 | | 03 | 02 | 80.0 | | 03 | 03 | 80.0 | | 05 | 01 | 76.0 | | 05 | 02 | 87.0 | | 07 | 02 | 89.0 | | 07 | 03 | 98.0 | +------+------+-------+ 13 rows in set (0.00 sec)
区别和优势
- CTE和衍生表都需要命名
- 两者都是为一个单独的声明而出现。
- 但,衍生表在一个查询内部只能被引用一次,
- 而,CTE可以被多次引用。
- 并,CTE可以自我引用。用于递归recursive。
- 并,CTE可读性更强,它出现在声明的最开始位置,而不是被嵌套在语句内部。
窗口函数 windows function (非聚合窗口函数)官方文档
MySQL 8.0窗口函数:用非常规思维简易实现SQL需求(中文)
需要在单表中满足某些条件的记录集内部做一些函数操作,不是简单的表连接,也不是简单的聚合可以实现的,通常会让写SQL的同学焦头烂额、绞尽脑汁,费了大半天时间写出来一堆长长的晦涩难懂的自连接SQL,且性能低下,难以维护。
要解决此类问题,最方便的就是使用窗口函数。
- 本章描述了非聚合窗口函数,因为每一行来自一个查询,使用和这个行相关的行来执行一个计算。
- 大多数聚合函数可以被用作窗口函数。
几个函数的表格:
| Name | Description |
| dense_rank() | Rank of current row within its partition, without gaps |
| rank() | Rank of current row within its partition, with gaps |
| row_number() | 每行加一个行号 |
rank()和dense_rank()的区别https://www.cnblogs.com/chentianwei/p/12128269.html
窗口函数的概念和语法
https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html
传统分组聚合函数和窗口函数的区别
- 传统group by配合聚合函数,是把查询的row导入一个单一的结果行row
- 窗口函数不是这样,它针对每一个查询row产生一个结果。
概念:
- 当前行: 函数计算所在行被称为当前行current row
- 当前行的窗口: 当前行涉及的使用函数计算的query rows组成了一个窗口。所以窗口就是指当前行涉及的使用函数计算的query rows。
格式:
函数() OVER ([PARTITION BY expr,..], [order by expr [asc|desc],...]) AS 别名
- over()内部有3块分别是partition by , order by , 和最后一个frame子句。
- ⚠️如果over()内什么都不写,则函数作用于where子句的范围,即基于所有行计算。
(1-6号更新)
窗口函数中的Frame子句的使用
参考https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html (看案例代码)
参考https://www.mysqltutorial.org/mysql-window-functions/ (看文章最后的图的说明)
这块知识点需要看案例来理解:
mysql> SELECT time, subject, val, SUM(val) OVER (PARTITION BY subject ORDER BY time ROWS UNBOUNDED PRECEDING) AS running_total, AVG(val) OVER (PARTITION BY subject ORDER BY time ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS running_average FROM observations; +----------+---------+------+---------------+-----------------+ | time | subject | val | running_total | running_average | +----------+---------+------+---------------+-----------------+ | 07:00:00 | st113 | 10 | 10 | 9.5000 | | 07:15:00 | st113 | 9 | 19 | 14.6667 | | 07:30:00 | st113 | 25 | 44 | 18.0000 | | 07:45:00 | st113 | 20 | 64 | 22.5000 | | 07:00:00 | xh458 | 0 | 0 | 5.0000 | | 07:15:00 | xh458 | 10 | 10 | 5.0000 | | 07:30:00 | xh458 | 5 | 15 | 15.0000 | | 07:45:00 | xh458 | 30 | 45 | 20.0000 | | 08:00:00 | xh458 | 25 | 70 | 27.5000 | +----------+---------+------+---------------+-----------------+
这是使用窗口函数得到的一个表格。
2020-03-05补:
上面的一句如今我都看不懂了。现在的理解是,frame就是以当前行为基,取上下行的范围区间。这个区间的值被传入聚合函数,进行运算。
2020-4-12补充:
把上面的数据输入数据库,进行测验:
1. over()内,只有一个partition by参数。
select *, sum(val) over(partition by subject) as sum_val from observations;
07:45:00 st113 20 64
07:30:00 st113 25 64
07:15:00 st113 9 64
07:00:00 st113 10 64
08:00:00 xh458 25 70
07:45:00 xh458 30 70
07:30:00 xh458 5 70
07:15:00 xh458 10 70
07:00:00 xh458 0 70
结果,窗口函数作用于整个分区。
即使用:ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
2.over()内,有一个partition by参数和一个order by 参数。
select *, sum(val) over(partition by subject order by time) as sum_val from observations; 07:00:00 st113 10 10 07:15:00 st113 9 19 07:30:00 st113 25 44 07:45:00 st113 20 64 07:00:00 xh458 0 0 07:15:00 xh458 10 10 07:30:00 xh458 5 15 07:45:00 xh458 30 45 08:00:00 xh458 25 70
结果默认使用:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
3. 改变数据, over()内,有2个partition by参数
07:00:00,st113,10, 07:15:00,st113,10, 07:15:00,st113,25, 07:45:00,st113,20, 07:00:00,xh458,0, 07:15:00,xh458,10, 07:30:00,xh458,5, 07:45:00,xh458,30, 08:00:00,xh458,25, 07:15:00,st113,100,
select *, sum(val) over(partition by subject, time ) as sum_val from observations;
结果:窗口函数作用于整个分组。即subject + time的分组。
⚠️更复杂的2个partition by,2个order by,还是根据目的加上frame明确范围的好
概念解释
frame子句的抽象格式:
frame_unit {<frame_start>|<frame_between>}
frame_unit有rows和range两种。
frame_start有3种:
UNBOUNDED PRECEDING: 从partition的开始到当前行current row的范围N PRECEDING: a physical N of rows before the first current row. 当前行,向上数N行的范围。N可以是数值或经过表达式计算返回的数。CURRENT ROW: 即当前行
frame_between: 抽象表示:BETWEEN frame_boundary_1 AND frame_boundary_2
frame_boundary_1 和frame_boundary_2 可以是:
frame_startUNBOUNDED FOLLOWING: 从当前行到partition的最后一行的范围。N FOLLOWING: 当前行,向下数N行的范围。
⚠️如果over()内使用不指定Frame子句,SQL默认使用:
⚠️👆这题规则👇只针对部分窗口函数生效。
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
2020-03-06补充:
发现了rows和range的区别:
- 用rows参数,则不考虑重复的值。
- 用range参数,如果当前行的值是10,相邻下一行的值也是10,sum()计算时,会把相邻的这两个值相加的。即考虑重复。具体见博客:
frame子句的对什么函数有影响?
- 部分聚合函数
- first_value, last_value,nth_value 3个窗口函数。
- 不会影响如rank, row_number等窗口函数,即使加上frame子句,这些窗口函数的作用范围仍然是整个partition。
- 例子:sum() over(partition by xxx) 作用于整个partition分组。✅
图例子:
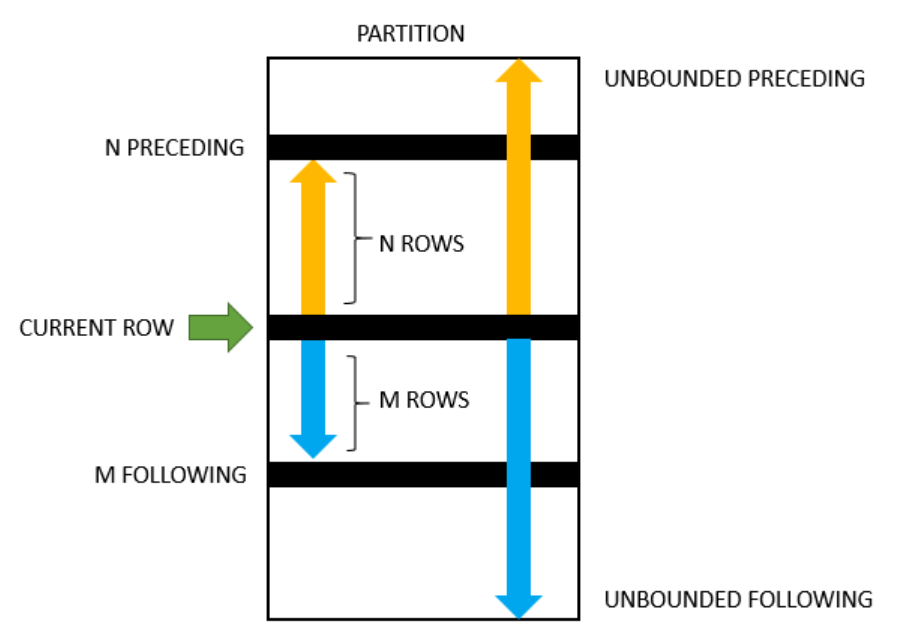
明白了这些生词的意思,然后看上面的例子就能理解了。
更多用法还要看文档(上面第一个连接)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号