《流畅的Python》Data Structures--第3章 dict 和 set
dict and set
字典数据活跃在所有的python程序背后,即使你的源码里并没有直接使用它。
和dict有关的内置函数在模块builtins的__dict__内。
>>> __builtins__ <module 'builtins' (built-in)> >>> __builtins__.__dict__
dict之所以在python中起到至关重要的作用,是因为Hash table。
本章内容:
- 常见方法
- 如何处理找不到的key
- dict变种
- set, frozenset
- Hash table 工作原理
- hash table的潜在影响。
Generic Mapping Types 泛映射类型
在python中只有一种标准映射类型: dict。下面说的是泛映射类型。
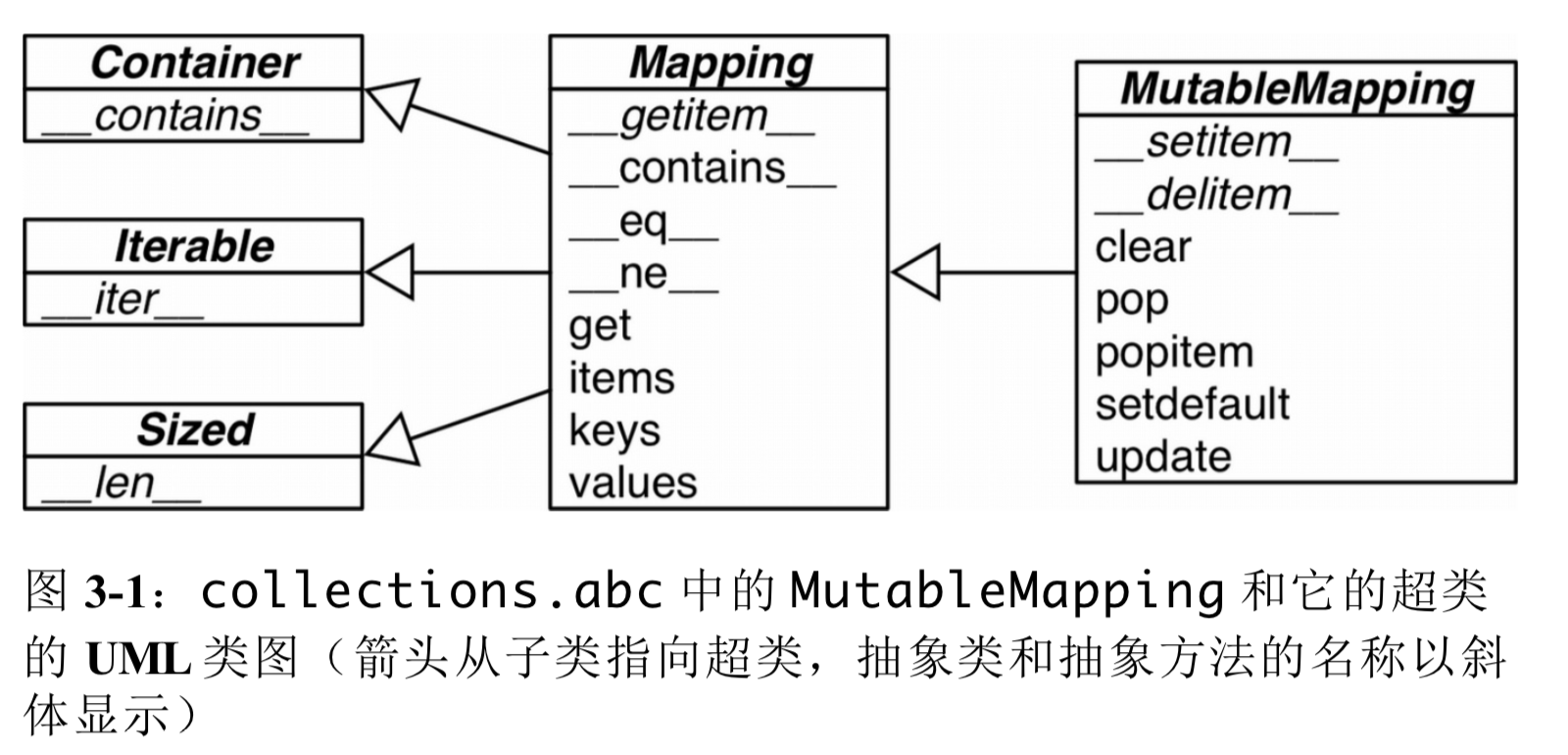
collections.abc模块提供了Mapping及其子类MutableMapping,用于formalize规范dict和相关类型的接口。
>>> from collections import * >>> UserDict <class 'collections.UserDict'> >>> UserDict.__bases__ (<class 'collections.abc.MutableMapping'>,) >>> UserDict.__class__ <class 'abc.ABCMeta'>
collections.UserDict的父类是MutableMapping。
标准库中所有的映射类型都是利用dict来实现。
key必须是hashable的数据类型。因为key必须是不可变的对象。
什么是Hashable? (点击链接,看文档说明)
- 如果说一个对象是hashable,那么在这个对象的整个生命中,它的hash value是不可变的。__hash__()
- 这个对象可以和其他对象进行比较。__eq__()
根据这个定义,str, bytes, 数值类都是hashable的。元祖的所有元素都是hashable的话,元祖也是hashable。
>>> a = {} >>> hash(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'dict' >>> a = [] >>> hash(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list' >>> a = (1, 2, (1, 2)) >>> hash(a) -1429464707349485113 >>> a = "hello" >>> hash(a) 1326837820661389949
使用hash()可知一个对象是否是hashable。返回一个hash value,如果不可hashable,报错。
⚠️其实就是说这个对象能否作为一个字典的key 使用,或一个set的内部项使用。
什么是mapping(文档)
mapping术语指的就是一种支持任意键查找并实现了 Mapping 或 MutableMapping 抽象基类 中所规定方法的容器对象。dict, OrderedDict等。
stackoverflow上的回答:什么是一个映射对象?
a mapping object (an object that supports PyMapping_Keys() and PyObject_GetItem())
第一个函数,来自映射协议。第二个来自对象协议。
dict Comprehensions
list有推导,dict也有推导,一种更简化的代码写法。
后面的章节:(略过,未学习)
- 常用方法和setdefault
- 变种:OrderedDict, ChainMap, Counter
- 子类UserDict: 更适合自定义映射类。
3.8集合 Set Theory
set涉及set和frozenset。
Python历史中,比较新的概念,使用频率也比较低。
一个set的本质就是许多唯一对象的集合collection。它的基本用途就是去除重复。
>>> l = ['spam', 'spam', 'eggs'] >>> set(l) {'eggs', 'spam'} >>> list(set(l)) ['eggs', 'spam']
⚠️set中的元素必须是hashable, 即体现出唯一性。
👆例子,set可以转化为list。使用tuple(l)也可以转化为tuple。
set类可以使用基础的 infix operators(中缀运算符),包括+, - ,& ,|
>>> s = {1}
>>> a = {2}
>>> s & a
set()
>>> s | a
{1, 2}
set Literals
class set()
创建一个不带参数的set,需要使用构建器: set(参数1)。
⚠️使用set()必然调用set函数, 速度比直接使用{}慢,可以通过dis.dis()反编译字节码看一下过程。
Set Comprehensions
又见推导式:
>>> from unicodedata import name >>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), " ")} {'=', '¤', '¢', '±', '®', '¬', '+', '§', '©', '°', '#', '¥', '×', '>', '£', '÷', '$', '%', 'µ', '¶', '<'} #chr(i) , i是整数,返回对应的Unicode码的字符串格式。
Difference between abstract class and interface in Python
Python没有正式的接口协议,不像java有明显的抽象和接口。如果想要实现一个接口,其实就是一个抽象类。
Java使用接口是因为它没有多重继承。而Python可以有多重继承。
我的理解:
- 抽象类,就是一些类共有的特征。
- 接口,接口中的方法,被不相关的类使用,仅仅是因为这些类都要用到这个接口中的方法。
- 抽象类,提供方法给它的子类。
- 接口,提供方法给第三方使用者。
- 抽象类可以既有抽象方法也可以有concrete method有型的方法。
- 接口,只有一堆抽象方法。
set类中的add方法,来自MutableSet吗?❌
set类的父类就是object。除了自身方法,就是object的方法。
MutableSet继承自Set,而Set继承Collection, Collection多重继承Size, Container, Iterable。
所以两者没不相关的。
看源码:https://github.com/python/cpython/blob/master/Objects/setobject.c
static PyMethodDef set_methods[] = { {"add", (PyCFunction)set_add, METH_O, add_doc}, {"clear", (PyCFunction)set_clear, METH_NOARGS, clear_doc}, {"__contains__",(PyCFunction)set_direct_contains, METH_O | METH_COEXIST, contains_doc}, {"copy", (PyCFunction)set_copy, METH_NOARGS, copy_doc}, {"discard", (PyCFunction)set_discard, METH_O, discard_doc}, #后面的代码略
set_pop(PySetObject *so, PyObject *Py_UNUSED(ignored)) { /* Make sure the search finger is in bounds */ setentry *entry = so->table + (so->finger & so->mask); setentry *limit = so->table + so->mask; PyObject *key; if (so->used == 0) { PyErr_SetString(PyExc_KeyError, "pop from an empty set"); return NULL; } while (entry->key == NULL || entry->key==dummy) { entry++; if (entry > limit) entry = so->table; } key = entry->key; entry->key = dummy; entry->hash = -1; so->used--; so->finger = entry - so->table + 1; /* next place to start */ return key; }
上面的是set实例的pop方法的源码,返回key。可以在交互看到:
>>> a = {1, 2}
>>> a.pop()
1
dict, set的速度优势
除了Cpython做的优化,这里主要讲述hash table。要理解它们的优势和缺点,也要讲述它们背后的hash tables。
- efficient
- 为什么是无序的unordered
- 为何不是所有对象都能做key
- Why does the order of the dict keys or set elements depend on insertion order, and may change during the lifetime of the structure?
- ⚠️,为何不要在迭代时,进行add操作?
A Performance Experiment(一个实验,表明用dict,set查找的速度比list快多了)
Hash Tables in Dictionaries
概述一下如何用hashtable来实现一个dict。
- hash table是一个sparse array(有很多空白元素cell的数组)。这种cell也叫做buckets桶/表元。
- 一个dict的hash table,每个key/value对儿都占据一个bucket。每个bucket由对key的引用和对value的引用2部分组成。
- 所有的bucket的占用空间大小都一样。因此可以通过偏移量来查找buckets。⚠️不理解
- 一个hash table,有三分之一的cell/buckets是空的。如果到达阀值,hashtable会被复制到更大的空间。
- 如果要把一个对象放入hash table,首先计算它的key的hash值,使用内建函数hash()得到hash值。
散列值和相等性质
如果2个对象是相等的,那么散列值也是相等的。但是整数1和浮点1.0比较 1 == 1.0为真,但它们内部的结构是不一样的。所以如果它们在一个散列表内,多作为key,就会产生散列冲突。但如果散列表足够大,就能避免。
⚠️其实还是不清楚。
Hash Tables algorithm
- 为了获得my_dict[search_key]的值,Python 首先调用hash(search_key)得到hash value。
- 用hash value的最低几位的数字当作偏移量,在散列表中找bucket。⚠️偏移量???
- 找到了bucket,但是,是空的,raise KeyError
- 非空,则检查search_key==found_key 是否为真,如果相等则返回foud_value。
- 如果不匹配,这是a hash collision。
遇到散列冲突:
原因是,寻找bucket的方法的原因。如果冲动,就重新来,从hash value内再取一段数字。
⚠️,具体偏移量和散列值的关系,本节未讲清楚。
我的理解,往hash table内新插入一个对象,如果这个对象的key的hash value的部分bit数字和bucket的内存位置的部分数字匹配来,那么就把这个对象的引用存入这个bucket中。当查找这个对象,也是如此匹配。
dict的实现及其导致的后果
1. keys必须是可散列的。
2 dict在内存上开销巨大。 因为使用了散列表,而散列表必须是稀疏的。
3.key的查询速度很快。典型的空间换时间。
4.key的顺序取决于插入时的顺序。
5.⚠️往字典里添加新的键可能会改变已有key的顺序。原因就是,可能会产生扩容操作,那么会重新把字典的已有元素添加到新的表里,这个过程有可能会发生散列冲突,导致新散列表中键的次序变化。所以在迭代时不要修改dict.
所有dict的特点也适用于set
总结
Dictionaries are a keystone of Python。
除了基本dict类,标准库提供了特殊的map类,便于扩展,和特殊用处。
update()是一个强大的新增和修改的方法。
⚠️,本章没有过于全部学习。学习了了6成的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号