keepalived高可用
keepalived简介
Keepalived 软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能。因此,Keepalived除了能够管理LVS软件外,还可以作为其他服务(例如:Nginx、Haproxy、MySQL等)的高可用解决方案软件。
Keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。
所以,Keepalived 一方面具有配置管理LVS的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。
keepalived官网Keepalived for Linux
keepalived的重要功能
keepalived 有三个重要的功能,分别是:
- 管理LVS负载均衡软件
- 实现LVS集群节点的健康检查
- 作为系统网络服务的高可用性(failover)
工作原理
Keepalived高可用之间是通过VRRP通信的
1) VRRP,全称 Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议,VRRP的出现是为了解决静态路由的单点故障。
2) VRRP是通过一种竟选协议机制来将路由任务交给某台 VRRP路由器的。
3) VRRP用 IP多播的方式(默认多播地址(224.0_0.18))实现高可用对之间通信。
4) 工作时主节点发包,备节点接包,当备节点接收不到主节点发的数据包的时候,就启动接管程序接管主节点的开源。备节点可以有多个,通过优先级竞选,但一般 Keepalived系统运维工作中都是一对。
5) VRRP使用了加密协议加密数据,但Keepalived官方目前还是推荐用明文的方式配置认证类型和密码。
Keepalived高可用对之间是通过 VRRP进行通信的, VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主挂了的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务。在 Keepalived服务对之间,只有作为主的服务器会一直发送 VRRP广播包,告诉备它还活着,此时备不会枪占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性.接管速度最快可以小于1秒。
keepalived配置文件
[root@master ~]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { //全局配置 notification_email { //定义报警收件人邮件地址 acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc //定义报警发件人邮箱 smtp_server 192.168.200.1 //邮箱服务器地址 smtp_connect_timeout 30 //定义邮箱超时时间 router_id LVS_DEVEL //定义路由标识信息,同局域网内唯一 vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { //定义实例 state MASTER //指定keepalived节点的初始状态,可选值为MASTER|BACKUP interface eth0 //VRRP实例绑定的网卡接口,用户发送VRRP包 virtual_router_id 51 //虚拟路由的ID,同一集群要一致 priority 100 //定义优先级,按优先级来决定主备角色,优先级越大越优先 nopreempt //设置不抢占 advert_int 1 //主备通讯时间间隔 authentication { //配置认证 auth_type PASS //认证方式,此处为密码 auth_pass 1111 //同一集群中的keepalived配置里的此处必须一致,推荐使用8位随机数 } virtual_ipaddress { //配置要使用的VIP地址 192.168.200.16 } } virtual_server 192.168.200.16 1358 { //配置虚拟服务器 delay_loop 6 //健康检查的时间间隔 lb_algo rr //lvs调度算法 lb_kind NAT //lvs模式 persistence_timeout 50 //持久化超时时间,单位是秒 protocol TCP //4层协议 sorry_server 192.168.200.200 1358 //定义备用服务器,当所有RS都故障时用sorry_server来响应客户端 real_server 192.168.200.2 1358 { //定义真实处理请求的服务器 weight 1 //给服务器指定权重,默认为1 HTTP_GET { url { path /testurl/test.jsp //指定要检查的URL路径 digest 640205b7b0fc66c1ea91c463fac6334d //摘要信息 } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } url { path /testurl3/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d } connect_timeout 3 //连接超时时间 nb_get_retry 3 //get尝试次数 delay_before_retry 3 //在尝试之前延迟多长时间 } } real_server 192.168.200.3 1358 { weight 1 HTTP_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334c } url { path /testurl2/test.jsp digest 640205b7b0fc66c1ea91c463fac6334c } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } }
vrrp_instance段配置
nopreempt #设置为不抢占。默认是抢占的,当高优先级的机器恢复后,会抢占低优先 级的机器成为MASTER,而不抢占,则允许低优先级的机器继续成为MASTER,即使高优先级 的机器已经上线。如果要使用这个功能,则初始化状态必须为BACKUP。
preempt_delay #设置抢占延迟。单位是秒,范围是0---1000,默认是0.发现低优先 级的MASTER后多少秒开始抢占
vrrp_script段配置
#作用:添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的VRRP Instance记录。 #注意:至少有一个VRRP实例调用它并且优先级不能为0.优先级范围是1-254. vrrp_script <SCRIPT_NAME> { ... } #选项说明: script "/path/to/somewhere" #指定要执行的脚本的路径。 interval <INTEGER> #指定脚本执行的间隔。单位是秒。默认为1s。 timeout <INTEGER> #指定在多少秒后,脚本被认为执行失败。 weight <-254 --- 254> #调整优先级。默认为2. rise <INTEGER> #执行成功多少次才认为是成功。 fall <INTEGER> #执行失败多少次才认为失败。 user <USERNAME> [GROUPNAME] #运行脚本的用户和组。 init_fail #假设脚本初始状态是失败状态。 #weight说明: 1. 如果脚本执行成功(退出状态码为0),weight大于0,则priority增加。 2. 如果脚本执行失败(退出状态码为非0),weight小于0,则priority减少。 3. 其他情况下,priority不变。
real_server段配置
weight <INT> #给服务器指定权重。默认是1 inhibit_on_failure #当服务器健康检查失败时,将其weight设置为0,而不是从Virtual Server中移除 notify_up <STRING> #当服务器健康检查成功时,执行的脚本 notify_down <STRING> #当服务器健康检查失败时,执行的脚本 uthreshold <INT> #到这台服务器的最大连接数 lthreshold <INT> #到这台服务器的最小连接数
tcp_check段配置
connect_ip <IP ADDRESS> #连接的IP地址。默认是real server的ip地址 connect_port <PORT> #连接的端口。默认是real server的端口 bindto <IP ADDRESS> #发起连接的接口的地址。 bind_port <PORT> #发起连接的源端口。 connect_timeout <INT> #连接超时时间。默认是5s。 fwmark <INTEGER> #使用fwmark对所有出去的检查数据包进行标记。 warmup <INT> //指定一个随机延迟,最大为N秒。可防止网络阻塞。如果为0,则关闭该功能。 retry <INIT> #重试次数。默认是1次。 delay_before_retry <INT> #默认是1秒。在重试之前延迟多少秒
keepalived实现nginx负载均衡机高可用
| 主机名 | IP | 系统 |
| master | 192.168.248.80 | redhat8 |
| backup | 192.168.248.81 | redhat8 |
VIP地址定为192.168.248.254
准备工作
//安装keepalived [root@master ~]# systemctl disable --now firewalld [root@master ~]# sed -ri 's/^(SELINUX=).*/\1disabled/g' /etc/selinux/config [root@master ~]# setenforce 0 [root@master ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo [root@master ~]# sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo [root@master ~]# sed -i 's/$releasever/8/g' /etc/yum.repos.d/CentOS-Base.repo [root@master ~]# yum -y install epel-release [root@master ~]# yum -y install keepalived [root@backup ~]# systemctl disable --now firewalld [root@backup ~]# sed -ri 's/^(SELINUX=).*/\1disabled/g' /etc/selinux/config [root@backup ~]# setenforce 0 [root@backup ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo [root@backup ~]# sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo [root@backup ~]# sed -i 's/$releasever/8/g' /etc/yum.repos.d/CentOS-Base.repo [root@backup ~]# yum -y install epel-release [root@backup ~]# yum -y install keepalived //master上安装nginx [root@master ~]# yum -y install nginx [root@master ~]# echo "master" > /usr/share/nginx/html/index.html [root@master ~]# systemctl start nginx //backup上安装nginx [root@backup ~]# yum -y install nginx [root@backup ~]# echo "backup" > /usr/share/nginx/html/index.html [root@backup ~]# systemctl start nginx
配置主keepalived
notify的用法:
notify_master:当当前节点成为master时,通知脚本执行任务(一般用于启动某服务,比如nginx,haproxy等)
notify_backup:当当前节点成为backup时,通知脚本执行任务(一般用于关闭某服务,比如nginx,haproxy等)
notify_fault:当当前节点出现故障,执行的任务;
[root@master ~]# cd /etc/keepalived/ [root@master keepalived]# cp keepalived.conf{,.bak} [root@master keepalived]# cat keepalived.conf ! Configuration File for keepalived global_defs { router_id lb01 } vrrp_script nginx_check { script "/scripts/check_n.sh" #检测脚本 interval 5 weight -20 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 90 mcast_src_ip 192.168.248.80 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.248.254 } track_script { #track_script用于追踪脚本 nginx_check } notify_master "/scripts/notify.sh master 192.168.248.254" notify_backup "/scripts/notify.sh backup 192.168.248.254" } virtual_server 192.168.248.254 80 { delay_loop 6 lb_algo rr lb_kind DR persistence_timeout 50 protocol TCP real_server 192.168.248.80 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 192.168.248.81 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } } #在/scripts目录下创建脚本,内容如下 [root@master keepalived]# cat /scripts/check_n.sh #!/bin/bash nginx_status=`ps -ef|grep -v "grep" | grep "nginx"|wc -l` if [ $nginx_status -lt 1 ];then systemctl stop keepalived fi #notify使用脚本 [root@master keepalived]# cat /scripts/notify.sh #!/bin/bash VIP=$2 sendmail (){ subject="${VIP}'s server keepalived state is translate" content="`date +'%F %T'`: `hostname`'s state change to master" echo $content | mail -s "$subject" xxx@xx.com } case "$1" in master) nginx_status=`ps -ef|grep -v "grep"|grep "nginx"|wc -l` if [ $nginx_status -lt 1 ];then systemctl start nginx fi sendmail ;; backup) nginx_status=`ps -ef|grep -v "grep"|grep "nginx"|wc -l` if [ $nginx_status -gt 0 ];then systemctl stop nginx fi ;; *) echo "Usage:$0 master|backup VIP" ;; esac
配置备用keepalived
[root@backup ~]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id lb02 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 90 mcast_src_ip 192.168.248.81 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 192.168.248.254 } notify_master "/scripts/notify.sh master 192.168.248.254" notify_backup "/scripts/notify.sh backup 192.168.248.254" } virtual_server 192.168.248.254 80 { delay_loop 6 lb_algo rr lb_kind DR persistence_timeout 50 protocol TCP real_server 192.168.248.80 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 192.168.248.81 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } } #notify脚本 [root@backup ~]# cat /scripts/notify.sh #!/bin/bash VIP=$2 sendmail (){ subject="${VIP}'s server keepalived state is translate" content="`date +'%F %T'`: `hostname`'s state change to master" echo $content | mail -s "$subject" xxx@xx.com } case "$1" in master) nginx_status=`ps -ef|grep -v "grep"|grep "nginx"|wc -l` if [ $nginx_status -lt 1 ];then systemctl start nginx fi sendmail ;; backup) nginx_status=`ps -ef|grep -v "grep"|grep "nginx"|wc -l` if [ $nginx_status -gt 0 ];then systemctl stop nginx fi ;; *) echo "Usage:$0 master|backup VIP" ;; esac
启动服务
//master上 [root@master ~]# systemctl enable --now keepalived [root@master ~]# systemctl enable --now nginx //backup上 [root@backup ~]# systemctl enable --now keepalived
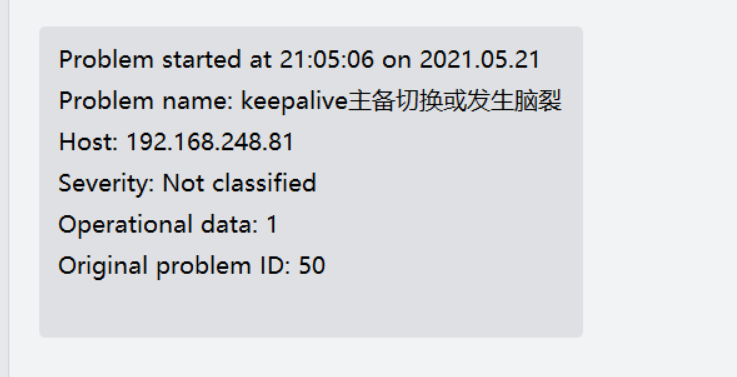
测试当master服务故障是否切换至backup
//手动停止master上的nginx服务 [root@master ~]# systemctl stop nginx
可以看到已经切换到backup上
重新启动master服务查看是否恢复到master服务
[root@master ~]# systemctl start nginx
[root@master ~]# systemctl start keepalived
对脑裂进行监控
对脑裂的监控应在备用服务器上进行,通过添加zabbix自定义监控进行。
监控什么信息呢?监控备上有无VIP地址
备机上出现VIP有两种情况:
- 发生了脑裂
- 正常的主备切换
监控只是监控发生脑裂的可能性,不能保证一定是发生了脑裂,因为正常的主备切换VIP也是会到备上的。
监控脚本如下:
注意:网卡要改成自己的网卡名称
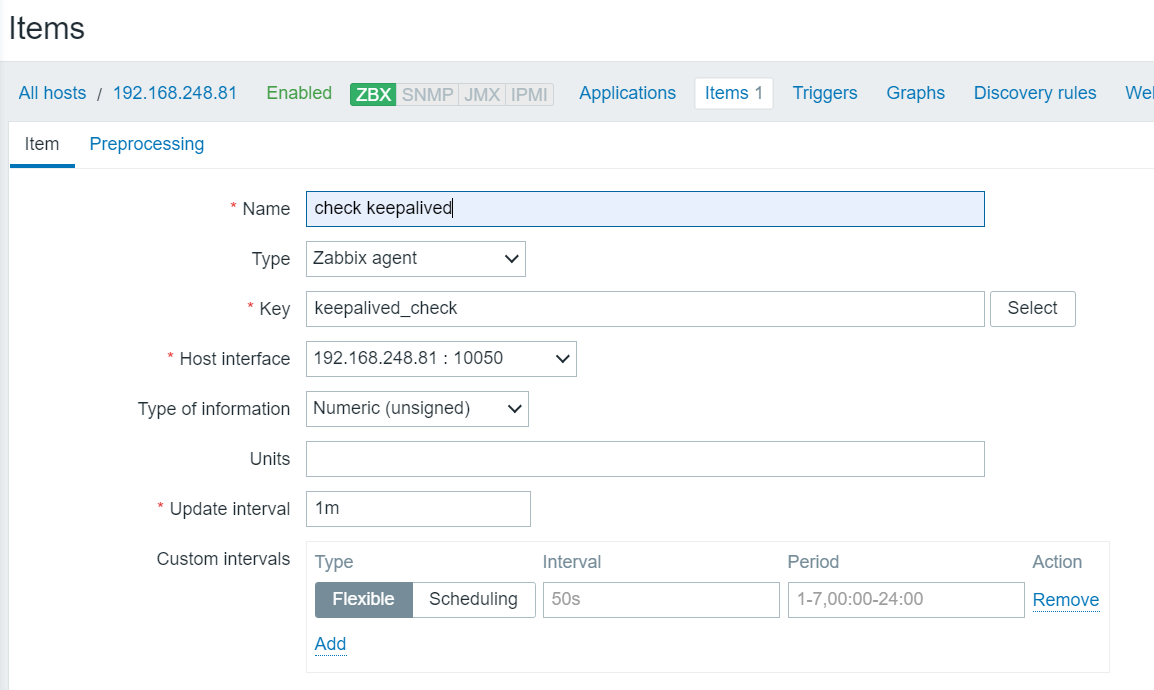
[root@backup zabbix_scripts]# cat check_keepalived.sh #!/bin/bash if [ `ip a show eth0 |grep 192.168.248.254|wc -l` -ne 0 ];then echo "1" else echo "0" fi [root@backup zabbix_scripts]# chmod +x check_keepalived.sh
在监控端测试是否能获取到值
[root@localhost zabbix-5.2.6]# zabbix_get -s 192.168.248.81 -p 10050 -k "keepalived_check" 0
配置zabbix监控
配置监控项
创建触发器
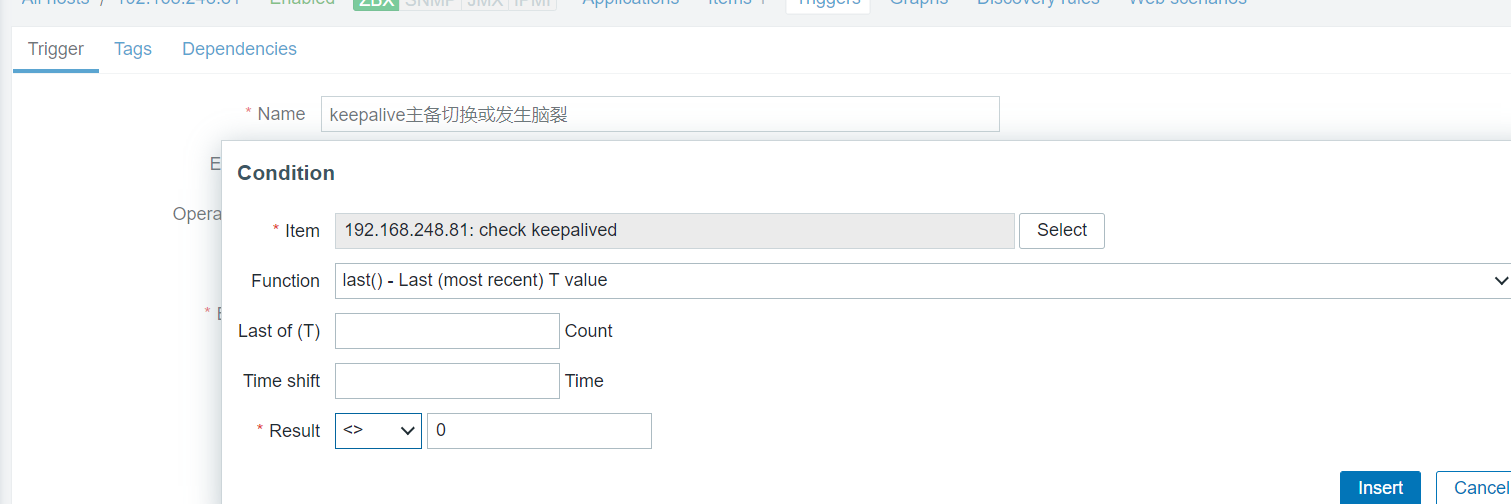
添加动作
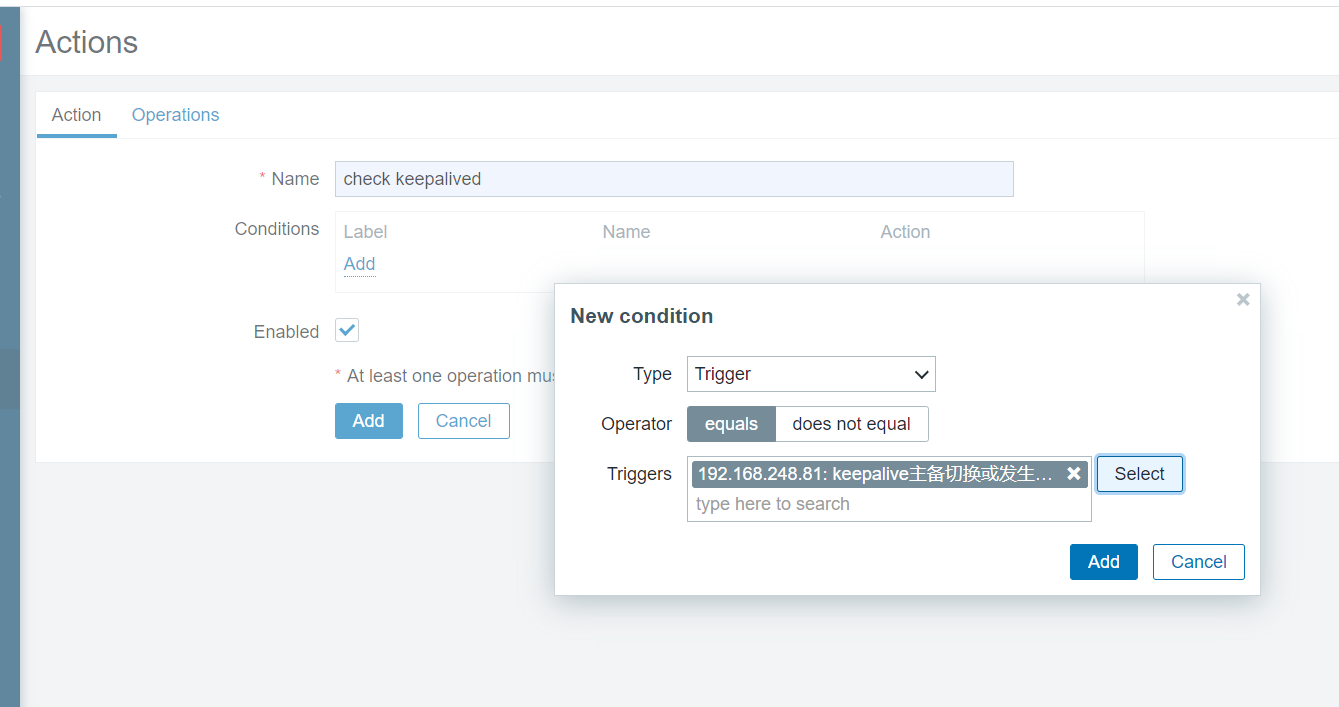

手动停掉服务测试告警
[root@master ~]# systemctl stop nginx