
陈思欣--第一次个人编程作业
| 博客班级 | 2018级实验班 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 进一步了解git操作,展示数据 |
| 作业源代码 | Git |
| 学号 | 211812105 |
| 代码总行:89行 | |
| 耗时情况 | |
| 过程 | 用时 |
| ---- | ---- |
| 爬取数据 | 两天左右ba |
| 数据处理 | 2h |
| 词云图 | 1h |
| Git上传 | 2h |
| 获取数据思路 |
-
先找到《在一起》电视剧,弹幕一出来便可以找到弹幕所在的URL,在同一集里面出现多个多条弹幕的URL,如下图,从每个URL里面可以发现,同一集的URL在timetamp有区别,其他的区别对该URL不产生影响
![]()
-
找到第一集弹幕之间的关系后,找集与集之间的关系。首先先把第一集与第二集的弹幕URL放在一起作比较,可以发现,这两个的主要影响区别在于target_id的不同。如下图
![]()


在搜索页,同样F12,可以看到每一集的具体网址中包含弹幕target_id的内容,如下图。所以先获取target_id的后面部分
- 要找出target_id的前面一部分,听取了这位老师python爬虫爬取腾讯视频弹幕教程/Python的课,恍如大悟。根据requests.post获得整个的target_id值
![]()
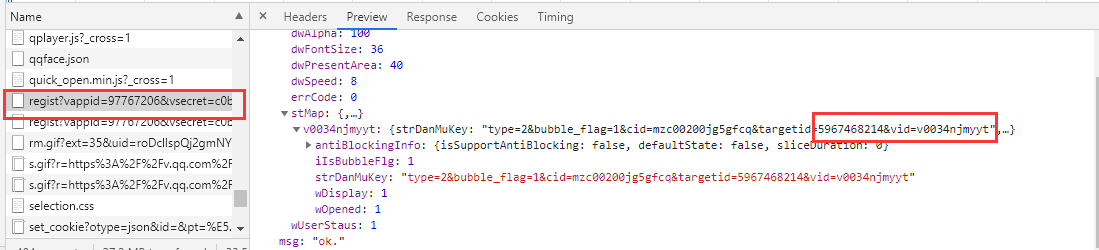
获得target_id和利用for循环获得时间戳,便可获得弹幕的json数据(实话实说,在这获取所有弹幕这个环节里,花了我好多的时间,一直报错,下文一起来感受下我的蠢吧)
`def get_comment(res):
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS = 'DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+HIGH:DH+HIGH:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+HIGH:RSA+3DES:!aNULL:!eNULL:!MD5'
header={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
for i in res:
for j in range(15,2500,30):
url='https://mfm.video.qq.com/danmu?&target_id=%s×tamp=%s'%(i,j)
url_1=url.replace('&vid=','%26vid%Dv')
print(url_1)
res=requests.get(url_1,headers=header,verify=False)
res2=res.json()
time.sleep(3)
for i in res2['comments']:
danmu=i["content"]
with open('danmu.txt','w+',encoding='utf-8')as f:
f.write(danmu+'\n')
time.sleep(1)`
最后得到的是所有的弹幕信息
数据处理
得到数据后,数据处理没错,可是,咋样处理,晕乎乎。后面看到了老师在题目中提到的结巴分词(好叭,没注意审题咯),后面利用结巴分词给弹幕做了归类
`import jieba
import jieba.analyse
jieba.load_userdict("dict_.txt")
txt = open("last_danmu-2.txt", "r", encoding='utf-8').read()
words = jieba.cut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(100):
word, count = items[i]
with open("last.txt","a+",encoding="utf-8")as f:
f.write("{0:<5}{1:>5}".format(word, count)+'\n')`
出来的效果,也还行嘿嘿😁
词云图
词云图词云图,好熟悉的一个词,好像之前做过……对!在上学期的人工智能有学过。so我翻啊翻啊,得,数据消失了╯﹏╰错付了。最后用的是TAGUL,请参考超简单:快速制作一款高逼格词云图
出来的效果是这样滴
Git上传
这个,我愣是没搞太明白,好像是那么几个代码,但是我还是没有彻底搞定陈思欣的第一次个人编程作业在上传的时候,一不小心两个文件被我同时上传了,我不懂为啥会两个一块上去,不过我看了使用Git Bash上传代码到新的分支,我貌似误打误撞撞对了
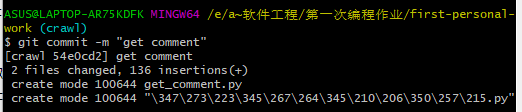
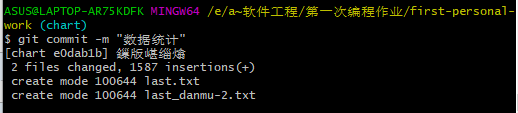
至于后面的合并额
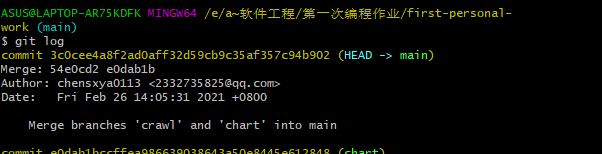
问题
- 在爬取的过程中一直会出现一个SSLError的错误,该开始以为是谷歌的版本升级后,anaconda版本更不上的原因,后面重新改版之后还是不行,我请教了上学期的爬虫老师,Python请求获得TLSV1_ALERT_INTERNAL_ERROR,大致明白了是什么原因,再加上sleep(3),后面很是顺利的获得了数据。
- Git问题了!也是看了网上很多大佬的代码,可是想象的和实际的还是有一些距离的,其实是自己基础不够。
好啦,就这样吧,后面要是有哪里写的有错还希望提醒一下啦,很愿意接受批评的嘿嘿😁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号