


Python运维开发基础07-文件基础
一,文件的基础操作
对文件操作的流程
创建初始操作模板文件
[root@localhost scripts]# seq 12 >> test
[root@localhost scripts]# ls
test test.py
[root@localhost scripts]# cat test
1
2
3
4
5
6
7
8
9
10
11
12
1.1 文件的按行读取(readline)
#文件的基本操作过程演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
f = open("test") #相对路径打开文件
first_line = f.readline() #读取文件的一行,并赋值
print (first_line) #打印第一行
for num in range(4) : #循环迭代4次
print (f.readline()) #在读一行继续打印(重复4次)
f.close() #关闭文件
#输出结果
[root@localhost scripts]# python3 test.py
1
2
3
4
5
特别提示:
只要文件没有执行f.close()进行关闭,那么继续f.readline()的话都是读取下一行
如果执行了f.close(),在重新进行f = open()的话,就会重新开始读行
#操作演示
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
f = open("test")
print (f.readline())
print (f.readline())
f.close()
f = open("test")
print (f.readline())
print (f.readline())
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
1
2
1
2
1.2 文件的按行读取和一次性读取(readline,read)
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
f = open("test")
print (f.readline()) #打印一行
print ("*"*50) #分隔标志
print (f.read()) #打印剩余所有行
f.close()
#输出结果:
[root@localhost scripts]# python3 test.py
1
**************************************************
2
3
4
5
6
7
8
9
10
11
12
1.3 文件的指针
一个文件被打开,如果从头到尾都被读了一遍,默认就不能再读了
#代码演示:
f = open("test")
print (f.read())
print ("-"*50)
print (f.read()) #没有产生作用
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
1
2
3
4
5
6
7
8
9
10
11
12
--------------------------------------------------
这是为什么呢?因为文件的读取其实是有一个叫做指针的东西存在的,当你读了一行,指针就会出现在下一行上,最终直到文件的末尾.由于末尾没有下一行了,因此就不能再读了。如果我们想继续从头再读,那就需要调整文件指针的位置。
1.4 文件的编码
当我们在Linux读取文件的时候,不会有任何编码问题,因为Linux默认就是utf-8的格式。假如我们在windows上读取含有中文的文件内容,就会出现乱码。
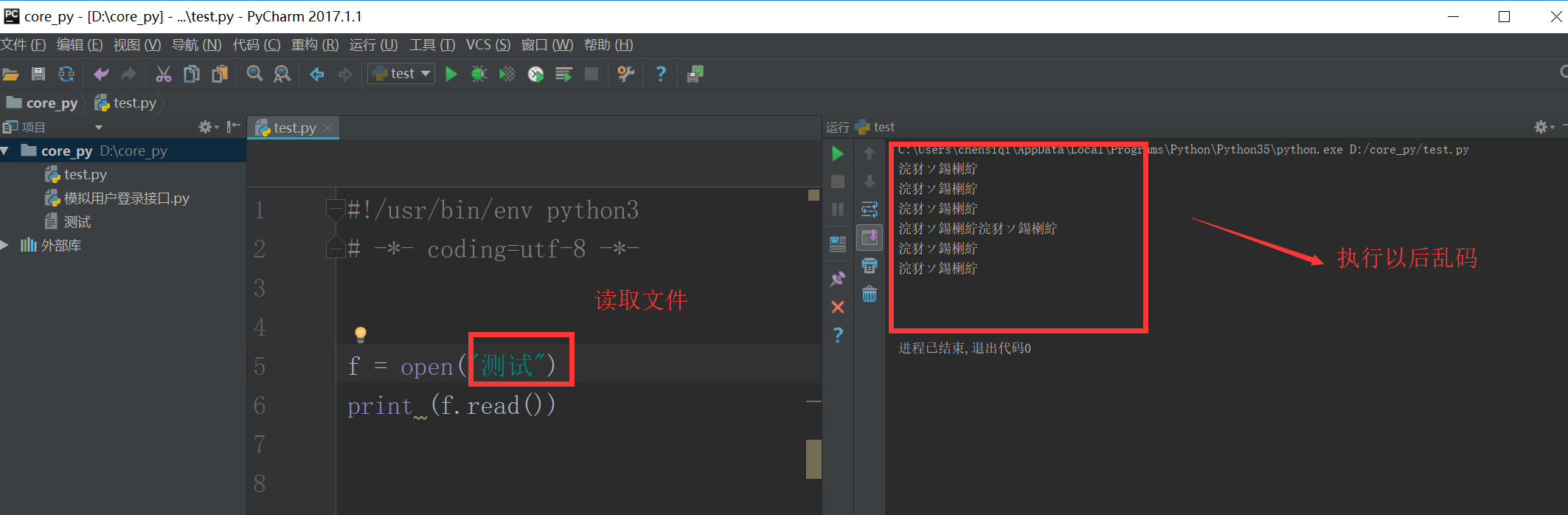
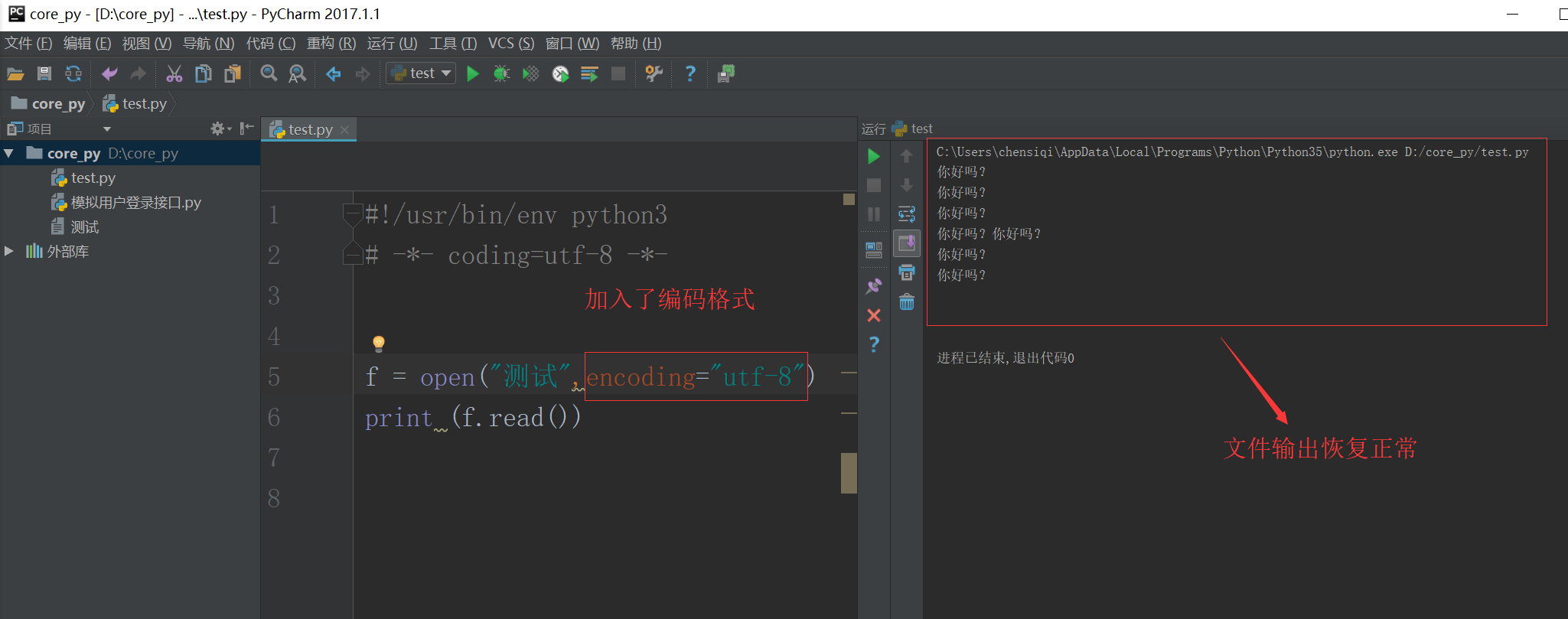
在Linux上就没有这个问题,因为Linux默认就是用utf-8去转码。
二,文件的基础打开模式
2.1 文件的读模式(r)
# 读模式(r)
f = open("test","r") #r,就表示以只读的方式打开文件,这种方式不可写入数据
print (f.read())
f.close()
#输出结果
1
2
3
4
5
6
7
8
9
10
11
12
如果不写r,默认就是r模式
2.2文件的写模式w(不能读,会清空源文件内容,文件不存在会创建)
# 写模式(w)
f = open("yunjisuan","w",encoding="utf-8")
for i in range(10) :
f.write("我写了{}行数据\n".format(i))
f.close()
#输出结果
[root@localhost scripts]# cat yunjisuan
我写了0行数据
我写了1行数据
我写了2行数据
我写了3行数据
我写了4行数据
我写了5行数据
我写了6行数据
我写了7行数据
我写了8行数据
我写了9行数据
特别提示:
如果写入的文件并不存在,则默认会创建这个文件
假如写入的文件存在,在写入的时候,会先清空源文件所有内容
2.3 文件的追加模式a(不可读;不存在则创建文件;存在则只追加内容)
# 追加模式(a)
f = open("yunjisuan","a",encoding="utf-8")
f.write("-"*50)
f.write("\n")
for i in range(10) :
f.write("我写了{}行数据\n".format(i))
f.close()
#输出结果
[root@localhost scripts]# cat yunjisuan
我写了0行数据
我写了1行数据
我写了2行数据
我写了3行数据
我写了4行数据
我写了5行数据
我写了6行数据
我写了7行数据
我写了8行数据
我写了9行数据
--------------------------------------------------
我写了0行数据
我写了1行数据
我写了2行数据
我写了3行数据
我写了4行数据
我写了5行数据
我写了6行数据
我写了7行数据
我写了8行数据
我写了9行数据
三,文件读取操作(r)的运用技巧
3.1 按行读取文件的内容
#读取文件的前5行
f = open("yunjisuan","r",encoding="utf-8")
for i in range(5) :
print (f.readline())
#读取文件的前8行,但是第5行不输出
f = open("yunjisuan","r",encoding="utf-8")
for i in range(8) :
data = f.readline()
if i != 4 :
print (data)
特别提示:
读取文件前8行,但是第5行不输出,不能写成如下形式。请同学们思考这是为什么?
#错误的实现访问
f = open("yunjisuan","r",encoding="utf-8")
for i in range(8) :
if i != 4 :
print (f.readline())
3.2 按行迭代输出一个文件的所有内容
#按行输出一个文件的所有内容
f = open("test","r",encoding="utf-8")
for line in f :
print (line)
#按行输出文件所有内容,第5行不输出
f = open("test","r",encoding="utf-8")
num = 1
for line in f :
if num != 5 :
print (line)
num += 1
3.3 优化文件的读取输出
为何输出时,有那么多的空行?
因为print本身就会在输出内容的后边加上\n的换行符,而从文件读取一行的行尾也是有一个\n的。因此在输出时,就变成了两次还行。所以我们需要去掉文件内容中附带\n.
#代码演示
f = open("test","r",encoding="utf-8")
for line in f :
print (line)
#输出结果
[root@localhost scripts]# python3 test.py
1
#都是空行
2
#因为在输出时有两个\n
3
4
5
#去掉多余的换行符再输出
f = open("test","r",encoding="utf-8")
for line in f :
print (line.strip())
#输出结果
[root@localhost scripts]# python3 test.py
1
2
3
4
5
3.4 f是个什么东西?
#代码演示:
>>> f = open("test","r",encoding="utf-8")
>>> print (r)
>>> print (f)
<_io.TextIOWrapper name='test' mode='r' encoding='utf-8'>
由上述操作可知,f只是一个内存对象。这个内存对象是指向文件的,也就是说,它是一行一行从文件中拿数据的。因此,可以用在读取大文件上。
3.5 read,readline,readlines区别
#代码演示:
f = open("test","r",encoding="utf-8")
print (f.readline()) #输出readline的值
f.close()
f = open("test","r",encoding="utf-8")
print (type(f.readline())) #输出readline的类型
f.close()
f = open("test","r",encoding="utf-8")
print (f.readlines()) #输出readlines的值
f.close()
f = open("test","r",encoding="utf-8")
print (type(f.readlines())) #输出readlines的类型
f.close()
f = open("test","r",encoding="utf-8")
print (f.read()) #输出read的值
f.close()
f = open("test","r",encoding="utf-8")
print (type(f.read())) #输出read的类型
f.close()
输出结果
[root@localhost scripts]# python3 test.py
1 #readline()是按行读取输出
<class 'str'> #输出为字符串格式
['1\n', '2\n', '3\n', '4\n', '5\n'] #readlines()将所有值输出
<class 'list'> #输出为列表格式
1
2
3
4 #read()也是将所有值输出
5
<class 'str'> #输出为字符串格式
由上述实验可知,由于readlines()和read()都是一次性将所有值输出,因此均不适合大文件的读取。而readline()是按行读取输出,适合读取大型文件。
3.6 为何迭代文件所有内容只能用f这个对象而不是readline()
#代码演示:
f = open("test","r",encoding="utf-8")
for line in f.readline():
print (line)
f.close()
print ("-"*50)
f = open("test","r",encoding="utf-8")
for line in f:
print (line)
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
1 #迭代readline仍旧只输出了一行
--------------------------------------------------
1 #代码f则输出了文件所有内容
2
3
4
5
由测试可知,readline()执行一次才能读取一行数据然后输出一行数据。因此,我们可以通过频繁执行readline()来获取文件内容,但是我们无法去直接迭代它。而f是一个指向内存的地址,其实它还是一个我们以后会学的迭代器这么个东西。在这里我们不要深究。记住就好。
3.7 去掉计数器迭代一个文件所有内容,并且第4行不输出
#代码演示:
f = open("test","r",encoding="utf-8")
for index,line in enumerate(f):
if index+1 != 4:
print (index+1,line)
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
1 1
2 2
3 3
5 5
3.8 文件的指针(tell,seek)
创建文件模板
[root@localhost scripts]# cat test
I am a students!
who are you ?
I am a students!
who are you ?
I am a students!
who are you ?
I am a students!
who are you ?
代码操作
f = open("test","r",encoding="utf-8")
print (f.tell()) #查看指针位置
f.readline() #按行读取
print (f.tell())
f.readline()
print (f.tell())
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
0
17 #指针是按字符计算的,一个字符计算1
31
#代码演示:
f = open("test","r",encoding="utf-8")
print (f.tell())
f.read(4)
print(f.tell())
f.close()
#输出结果
[root@localhost scripts]# python3 test.py
0
4
指针回调
#代码演示:
f = open("test","r",encoding="utf-8")
print (f.tell())
print (f.readline())
print(f.tell())
f.seek(0) #将指针回调到0位置
print (f.tell())
print (f.readline())
f.close()
#输出演示:
[root@localhost scripts]# python3 test.py
0
I am a students!
17
0
I am a students!
四,文件写入操作(w)的运用技巧
4.1 文件的缓冲原理(buffer)
我们知道当我们写入文件内容的时候,如果目标文件不存在默认会创建一个空文件,如果目标文件存在内容,那么默认会清空目标文件。然后才会写入我们想要写入的数据,但是它是如何写入数据的呢?一行一行写入?还是一次性写入呢?
#代码演示:
f = open("yun","w",encoding="utf-8")
f.write("我好吗?\n")
f.write("我好吗?\n")
f.write("我好吗?\n")
decide = input("稍等一下:") #我们执行完写入代码利用用户输入代码卡住这里,看看f.write()写入操作到底写入文件了没有
f.close()
当我们执行上述代码后,卡在用户输入界面,我们去看那个文件是否被写入了内容,查看的结果是空的,文件里什么都没有。
[root@localhost scripts]# cat yun
#空空如也
- 这是为什么呢?这是因为,当我们将数据写入文件的时候,如果一行一行进行数据写入,那么需要不断的进行I/O操作,而控制我们写入速度的是线程,而操作线程的又是CPU,所以我们的写入速度是非常快的。而磁盘的I/O速度,是非常慢的。如果我们一行一行进行数据写入,那么就会让我们线程一直等在这里,这会非常的没有效率。
- 因此,文件会默认先将数据写入到内存的(buffer)里,然后在一次性写入到文件中。
- 在代码里就是当文件被关闭时,默认数据从(buffer)一次性写入到文件中。
#当执行了代码f.close()之后...
[root@localhost scripts]# cat yun
我好吗?
我好吗?
我好吗?
那么写入到缓冲buffer的这个动作,我们可以看的到吗?作为开发,我们当然能看到。
#代码演示
f = open("yun","w",encoding="utf-8")
f.write("我好吗?\n")
f.write("我好吗?\n")
f.write("我好吗?\n")
print(f.buffer) #打印buffer的内存地址
decide = input("稍等一下:")
f.close()
#输出结果
<_io.BufferedWriter name='yun'> #只是一个指向文件名的内存地址,这个就是buffer。数据是存在内存中的。
4.2 文件的写入刷新(flush)
- 当我们写入数据时候,我们已经知道了实际是写入到内存的缓冲区buffer的。当最后遇到f.close()时,数据才会被一次性写入到文件。
- 但是,假如我们就需要随时刷新数据进入文件呢?我们怎么办?
#代码演示:
f = open("yun","w",encoding="utf-8")
f.write("我好吗?\n")
f.write("我好吗?\n")
f.flush() #即时刷新buffer中的数据到文件
f.write("我好吗?\n")
decide = input("稍等一下:")
f.close()
#输出结果
[root@localhost scripts]# cat yun
我好吗?
我好吗?
由上述实验,我们可知当我们想要即时将buffer里的数据刷新到文件里,那么我们只需要执行f.flush即可。
4.3 通过flush刷新规则实现文件的安装进度条显示
平时我们用的print输出其实默认在输出一个换行符的。如此Linux才会换行显示
#代码演示:
print (1)
print (2)
print (3)
#输出结果
1
2
3
可是我们知道进度条都是一行显示的因此我们不能用print,我们需要用一种叫做标准输出的东西,在sys模块里。
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys
sys.stdout.write("1") #默认不输出换行符
sys.stdout.write("2")
sys.stdout.write("3")
#输出结果
123
特别提示:
sys.stdout.write()标准输出只能输出str格式的字符串
应用这个输出我们就可以实现进度条了。
#代码演示:
import sys,time
for i in range(20):
sys.stdout.write("#")
time.sleep(0.1)
#输出结果
####################
虽然我们已经设置了,每次输出间隔0.1秒,但是我们发现20个#仍旧是一次性输出的。这是因为,标准输出也是等到你整个进程都结束了才输出#号,因此我们修改一下
#代码演示:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys,time
for i in range(20):
sys.stdout.write("#")
sys.stdout.flush() #刷新每次的写入到屏幕
time.sleep(0.1)
如上修改过的代码就可以实现Linux安装进度条显示了。
五 文件追加操作(a)的运用技巧
5.1 文件的追加截断(truncate)
截取文件的一部分内容,然后写回源文件
文件初始模版:
[root@localhost scripts]# cat yun
123456789012345678901234567890 #一共30个字符
执行代码:
#代码演示
f = open("yun","a",encoding="utf-8")
f.truncate(20)
#执行结果
[root@localhost scripts]# cat yun
12345678901234567890 #只剩下了20个字符
六,作业
1,继续完成阶段性作业

