


Python运维开发基础03-语法基础
上节作业回顾(讲解+温习60分钟)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
#只用变量和字符串+循环实现“用户登陆验证接口功能”
user_One_name = "chensiqi1"
user_One_passwd = "666666"
user_Two_name = "chensiqi2"
user_Two_passwd = "666666"
error = ""
while True :
user_Name = input("请输入登录用户的用户名:")
if user_Name in error.split() :
print ("用户已经被锁定,请尝试登陆其他用户!")
elif user_Name == user_One_name or user_Name == user_Two_name :
for i in range(3) :
user_Passwd = input("请输入登陆用户名的密码:")
if user_Name == user_One_name and user_Passwd == user_One_passwd :
print ("{}用户登陆成功!".format(user_Name))
exit()
elif user_Name == user_Two_name and user_Passwd == user_Two_passwd :
print ("{}用户登陆成功!".format(user_Name))
exit()
else :
print ("用户账户或密码输入错误!请重新输入,您还有{}次机会。".format(2-i))
else :
print ("您的密码已经输错3次了,账户已经锁定!请尝试登陆其他用户。")
error = error + " " + user_Name
else :
print ("没有这个账户名,请重新输入!")
一,模块初识
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学两个简单的。
1.1 sys模块
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import sys
print (sys.argv)
#输出
[root@localhost scripts]# python3 test.py hello world #执行脚本时传递的参数获取到了
['test.py', 'hello', 'world']
1.2 os模块
实例(1):os.system()方法
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
os.system("df -h") #调用系统命令
#输出
[root@localhost scripts]# python3 test.py
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 18G 1.7G 15G 11% /
tmpfs 491M 0 491M 0% /dev/shm
/dev/sda1 485M 33M 427M 8% /boot
说明:
os.system()模块只是即时执行命令,然后显示输出结果,因此,不能通过赋值操作给某个变量再进行打印。例如:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
ccc = os.system("ls")
print (ccc)
print (ccc)
print (ccc)
print (ccc)
#输出
[root@localhost scripts]# python3 test.py
__init__.py sys.py test.py
0 #输出都是0,没有结果,变量不能赋值
0
0
0
实例(2):os.popen()方法
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
cmd_res = os.popen("ls").read()
print (cmd_res)
#输出
[root@localhost scripts]# python3 test.py
__init__.py
sys.py
test.py
说明:os.popen()模块,执行以后,是将数据放到了内存中,因此,如果将结果进行赋值操作,显示的只是一个内存地址,例如:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
ccc = os.popen("ls")
print (ccc)
#输出
[root@localhost scripts]# python3 test.py
<os._wrap_close object at 0x7fb2abe517f0>
说明:os.popen()执行后得到的是一个内存地址,因此,想要将内存地址的结果输出出来,就必须调用.read()方法。即,os.popen().read()
实例(3)os.mkdir()方法
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
import os
os.mkdir("new_dir") #在当前目录下创建目录
#输出
[root@localhost scripts]# python3 test.py
[root@localhost scripts]# ls
__init__.py new_dir sys.py test.py
1.3 自定义一个模块
(1)当前目录下随便写一个文件作为被调用的模板
[root@localhost scripts]# cat helloworld.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:Mr.chen
print ("hello world!")
[root@localhost scripts]# python3 helloworld.py
hello world!
(2)在当前目录下另外的文件调用模块
[root@localhost scripts]# ls
helloworld.py test.py
[root@localhost scripts]# cat test.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:Mr.chen
import helloworld #调用模块
[root@localhost scripts]# python3 test.py
hello world!
特别说明:
- 当我们import一个模块名字的时候,它首先会去被执行文件的当前目录下去找,如果有同样名字.py结尾的文件,就会将文件内容自动导入进来。如果当前目录下没有找到,那么他就回去Python的全局变量里去找。这点类似于shell脚本的include。
- 如果你将新写的那个模块文件移动走,那么import找不到了就会报错。但是假如你把它移动到/usr/local/python35/lib/python3.5/site-packages/路径下,你会神奇的发现模块又能找到了。
#随便移走模块文件测试
[root@localhost scripts]# mv helloworld.py /root/
[root@localhost scripts]# python3 test.py
Traceback (most recent call last):
File "test.py", line 5, in <module>
import helloworld
ImportError: No module named 'helloworld'
#将模块文件移动到/usr/local/python35/lib/python3.5/site-packages/路径下
[root@localhost scripts]# mv /root/helloworld.py /usr/local/python35/lib/python3.5/site-packages/
[root@localhost scripts]# python3 test.py
hello world! #正常了
这是什么原因呢?
- 这是因为Python将系统内置的模块库放在了/usr/local/python35/lib/python3.5/路径下;而第三方用户自己下载安装或者自己写的模块库默认是要放在/usr/local/python35/lib/python3.5/site-packages/路径下的。在这两个路径下,Python都能找的到。
- 那么,python是通过什么找到的呢?这是因为Python也有自己的环境变量。
#Python的环境变量
>>> import sys
>>> sys.path
['', '/usr/local/python35/lib/python35.zip', '/usr/local/python35/lib/python3.5', '/usr/local/python35/lib/python3.5/plat-linux', '/usr/local/python35/lib/python3.5/lib-dynload', '/usr/local/python35/lib/python3.5/site-packages']
1.4 pyc是什么?
假如我们将自己写的模块文件扔到了python27的site-packages目录下,然后在执行调用模块的文件的话,你会发现在site-packages目录下多了一个和模块名相同但是后缀为.pyc的文件。
#操作演示
[root@localhost scripts]# mv helloworld.py /usr/local/python27/lib/python2.7/site-packages/
[root@localhost scripts]# python -V
Python 2.7.13
[root@localhost scripts]# python test.py
hello world!
[root@localhost scripts]# ls /usr/local/python27/lib/python2.7/site-packages/helloworld.*
/usr/local/python27/lib/python2.7/site-packages/helloworld.py
/usr/local/python27/lib/python2.7/site-packages/helloworld.pyc #这个文件是个什么鬼?
1.4.1 Python是一门解释型语言?
- 我初学Python时,听到的关于Python的第一句话就是,Python是一门解释型语言,我就这样一直相信下去,知道发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对!
- 为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清这个问题,并且把一些基础概念给理清。
1.4.2 解释型语言和编译型语言
- 计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
- 编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
- 解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Shell。
- 通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
- 此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
- 用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
1.4.3 Python到底是什么?
- 其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
- 当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
- 熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello- 只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
1.4.4 简述Python的运行过程
- 在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
- 我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
- 当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
- 当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
- 所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
二,数据类型初识
2.1 数字
2 是一个整数的例子
长整数不过是大一些的整数
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10**4.
int(整型)
- 在32位机器上,整数的位数为32位,取值范围为-2^312**31-1,即-21474836482147483647
- 在64位系统上,整数的位数为64位,取值范围为-2^63~2**63-1,即-9223372036854775808~9223372036854775807
>>> 2*3
6
>>> 2**3
8
long(长整型)
- 跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
- 注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
#在python27中
>>> type(2**30)
<type 'int'>
>>> type(2**40)
<type 'int'>
>>> type(2**50)
<type 'int'>
>>> type(2**64)
<type 'long'>
>>> type(2**100)
<type 'long'>
#在python3中
>>> type(2**50)
<class 'int'>
>>> type(2**10)
<class 'int'>
>>> type(2**500)
<class 'int'>
>>> type(2**5000)
<class 'int'>
>>> type(2**50000)
<class 'int'>
>>> type(2**64)
<class 'int'>
Python3中取消了长整型(long)的类型
float(浮点型)
- 浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
>>> type(2.33)
<class 'float'>
>>> type(2.3333333333333333)
<class 'float'>
2.2 布尔值
真或假
1或0
>>> 3==3
True
>>> 3==5
False
2.3 字符串
"hello world"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内存中重新开辟一块空间。
字符串格式化输出
name = "alex"
print "i am %s" % name
#输出
i am alex
字符串是%s;
整数 %d;
浮点数 %f
三,列表
列表是我们以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储,修改等操作
定义一个列表
>>> names = ["yunjisuan","benet","yun"]
通过下标访问列表中的元素,下标从0开始计数
>>> names[0]
'yunjisuan'
>>> names[1]
'benet'
>>> names[2]
'yun'
>>> names[-1] #还可以倒数
'yun'
>>> names[-2]
'benet'
>>> names[-3]
'yunjisuan'
3.1 切片:取多个元素
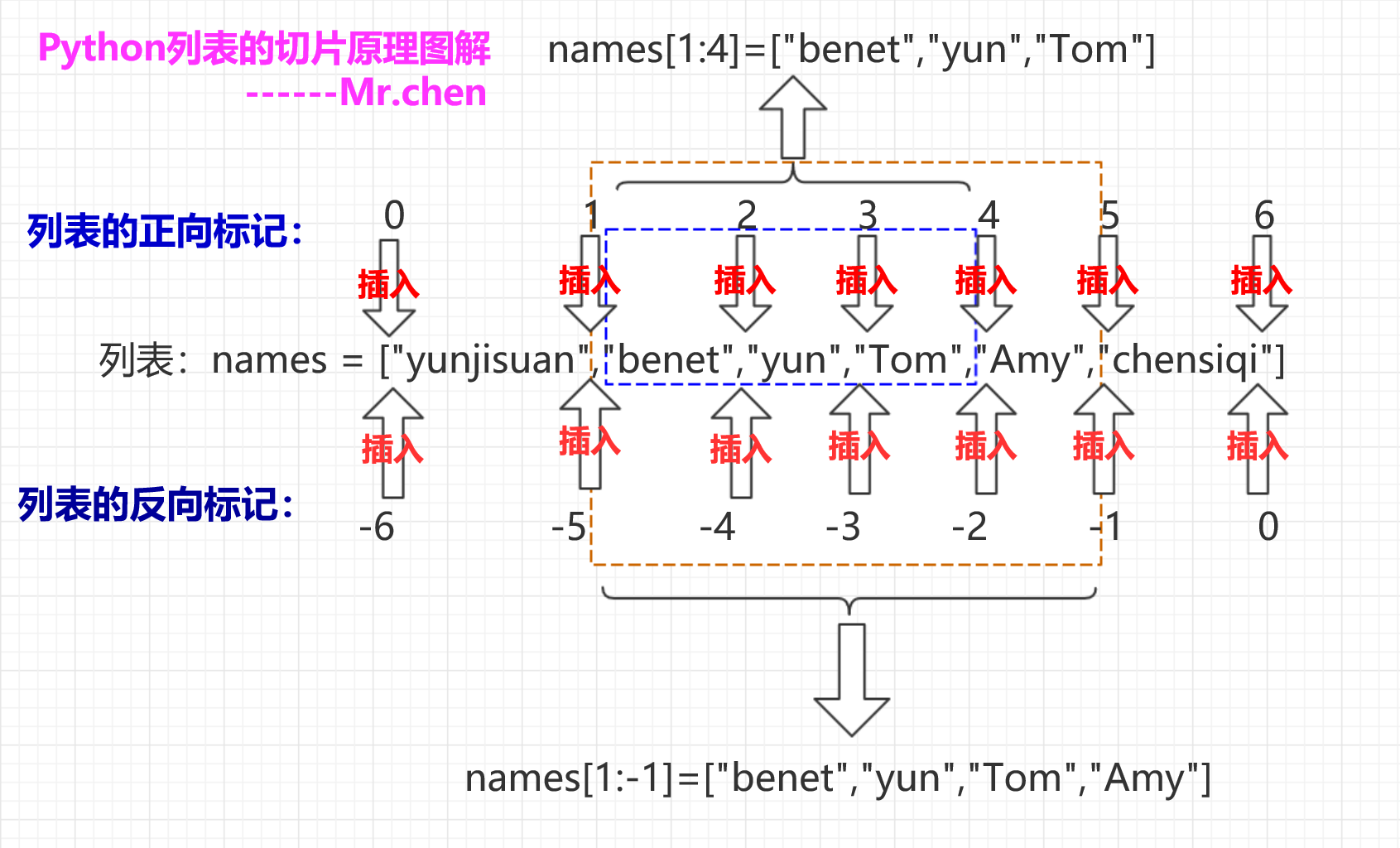
#代码演示
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names[1:4]
['benet', 'yun', 'Tom']
>>> names[1:-1]
['benet', 'yun', 'Tom', 'Amy']
>>> names[0:3]
['yunjisuan', 'benet', 'yun']
>>> names[:3]
['yunjisuan', 'benet', 'yun']
>>> names[3:]
['Tom', 'Amy', 'chensiqi']
>>> names[3:-1]
['Tom', 'Amy']
>>> names[0::2]
['yunjisuan', 'yun', 'Amy']
>>> names[::2]
['yunjisuan', 'yun', 'Amy']
3.2 追加(append):默认追加到末尾
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names.append("我是新来的")
>>> names
['yunjisuan', 'benet', 'yun', 'Tom', 'Amy', 'chensiqi', '我是新来的']
3.3 插入(insert):插入列表指定位置
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names.insert(2,"挤走元素yun,强行插到yun前面")
>>> names
['yunjisuan', 'benet', '挤走元素yun,强行插到yun前面', 'yun', 'Tom', 'Amy', 'chensiqi']
>>> names.insert(5,"挤走元素Amy,强行插在Amy前面")
>>> names
['yunjisuan', 'benet', '挤走元素yun,强行插到yun前面', 'yun', 'Tom', '挤走元素Amy,强行插在Amy前面', 'Amy', 'chensiqi']
3.4 修改:对列表中的元素赋值进行替换
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names[2] = "该换人了"
>>> names
['yunjisuan', 'benet', '该换人了', 'Tom', 'Amy', 'chensiqi']
3.5 删除:
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> del names[2] #删除列表指定位置的元素
>>> names
['yunjisuan', 'benet', 'Tom', 'Amy', 'chensiqi']
>>> names.remove("Tom") #删除指定内容的元素
>>> names
['yunjisuan', 'benet', 'Amy', 'chensiqi']
>>> names.remove("xxxx") #找不到内容会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
>>> names.pop() #删除列表最后一个元素
'chensiqi'
>>> names
['yunjisuan', 'benet', 'Amy']
3.6 扩展:将两组列表合并
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> b = [1,3,5]
>>> names.extend(b)
>>> names
['yunjisuan', 'benet', 'yun', 'Tom', 'Amy', 'chensiqi', 1, 3, 5]
3.7 拷贝:
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names_copy = names.copy()
>>> names_copy
['yunjisuan', 'benet', 'yun', 'Tom', 'Amy', 'chensiqi']
3.8 统计:统计列表某个元素的拥有个数
#代码演示:
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> names.count("Amy")
1
>>> names.append("Amy")
>>> names
['yunjisuan', 'benet', 'yun', 'Tom', 'Amy', 'chensiqi', 'Amy']
>>> names.count("Amy")
2
3.9 排序&翻转
#代码演示:
#在Python2.7里
>>> names = ["Tom","Amy","benet","1","2","3"]
>>> names
['Tom', 'Amy', 'benet', '1', '2', '3']
>>> names.sort() #排序
>>> names
['1', '2', '3', 'Amy', 'Tom', 'benet']
>>> names.reverse() #翻转
>>> names
['benet', 'Tom', 'Amy', '3', '2', '1']
#在Python3.0里
>>> names = ["yunjisuan","benet","yun","Tom","Amy","chensiqi"]
>>> b = [1,3,5]
>>> names.extend(b)
>>> names
['yunjisuan', 'benet', 'yun', 'Tom', 'Amy', 'chensiqi', 1, 3, 5]
>>> names.sort()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: int() < str() #Python3.0里不同数据类型不能放在一起排序了。
>>> name = [8,6,3,1,4,7,9,10] #Python3.0数字的排序与翻转
>>> name.sort()
>>> name
[1, 3, 4, 6, 7, 8, 9, 10]
>>> name.reverse()
>>> name
[10, 9, 8, 7, 6, 4, 3, 1]
>>> name = ["chen","bent","yunjisuan","zabbix","Tom","cat"] #Python3.0字符串的排序与翻转
>>> name.sort()
>>> name
['Tom', 'bent', 'cat', 'chen', 'yunjisuan', 'zabbix']
>>> name.reverse()
>>> name
['zabbix', 'yunjisuan', 'chen', 'cat', 'bent', 'Tom']
3.10 获取下标(index):找出列表中指定内容的元素的下标
#代码演示:
>>> names = ["chen","bent","yunjisuan","zabbix","Tom","cat"]
>>> names.index("Tom") #找出列表中指定内容元素的下标号
4
>>> names.append("Tom")
>>> names.count("Tom") #列表中有两个“Tom”
2
>>> names.index("Tom") #只能返回找到的第一个Tom的下标
4
>>> names.index("xxxx") #如果找不到符合条件的元素会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'xxxx' is not in list
3.11 获取元素个数(len)
#代码演示:
>>> List = ["a","b","c","d","e","f",33]
>>> len(List)
7
四,元组
元组其实和列表差不多,也是存一组数,只不过它一旦创建,便不能再修改,所以又叫只读列表
语法:
>>> names = ("yunjisuan","benet","Tom") #创建一个元组
>>> names[2]="xxx" #试图修改元组的元素会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
元组只有两个方法,一个是count,一个是index,完毕。
#代码演示:
>>> names = ("yunjisuan","benet","Tom")
>>> names.count("benet")
1
>>> names.index("benet")
1
五,利用列表知识来优化"用户登陆验证接口程序"
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# author:Mr.chen
#利用列表功能优化“用户登陆验证接口功能”
user_name_list = ["chensiqi1","chensiqi2"]
user_passwd_list = ["666666","666666"]
error = []
while True :
user_Name = input("请输入登录用户的用户名:")
if user_Name in error :
print ("用户已经被锁定,请尝试登陆其他用户!")
elif user_Name in user_name_list :
user_Name_index = user_name_list.index(user_Name)
for i in range(3) :
user_Passwd = input("请输入登陆用户名的密码:")
if user_Passwd == user_passwd_list[user_Name_index] :
print ("{}用户登陆成功!".format(user_Name))
exit()
else :
print ("用户账户或密码输入错误!请重新输入,您还有{}次机会。".format(2-i))
else :
print ("您的密码已经输错3次了,账户已经锁定!请尝试登陆其他用户。")
error.append(user_Name)
else :
print ("没有这个账户名,请重新输入!")
六,逻辑引导与作业
逻辑引导:
- 我们学习了列表这种数据类型,它可以让我们集中式的存取多个数据,这大大方便了我们存取数据所遇到的问题。并且我们还利用列表优化了“登陆接口的程序”。
- 但是,我们仍旧有很多麻烦,比如创建账号时,账号都是有密码的。我们虽然利用列表+元组合并的方式暂时解决了账号和密码没有相互联系的问题。可是,如果我们是在购物呢?购物的时候,商品是有很多种类型的,而种类和商品名称之间是有很多关系的。比如家用电器--->小家电--->电视机---->[彩色电视机,黑白电视机]。这些数据和数据之间是有着包含关系的,这用列表来表示就非常的麻烦。我们只能创建多个列表。然后通过人为定义列表名称来添加联系。
- 那么,Python有没有一种数据类型,可以很方便的表示数据和数据之间的关联关系,从而让调用存取数据之间可以按类型检索呢?这就需要我们学习下一节的知识-->字典(dict)
作业:请闭眼写出以下程序
程序:购物车程序
需求:
北京IT职业教育培训中心,欢迎来校咨询。微信号:yinsendemogui(添加时请注明博客园)

