


在DataFrame数据表里面提取需要的行
代码功能:
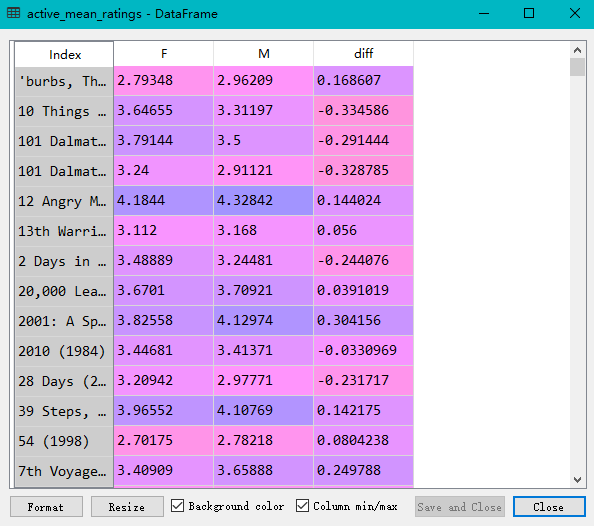
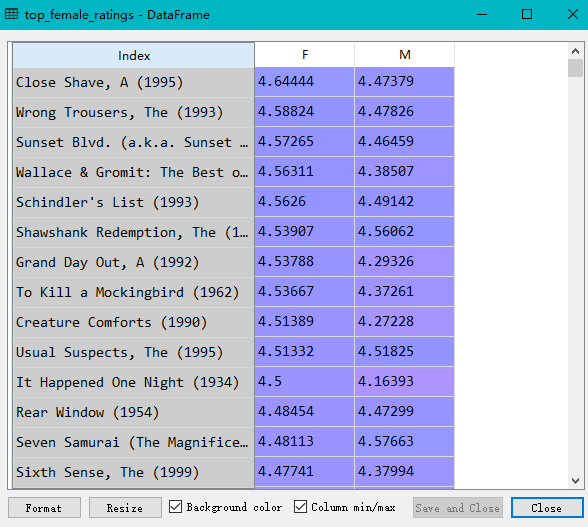
在DataFrame表格中使用loc(),得到我们想要的行,然后根据某一列元素的值进行排序
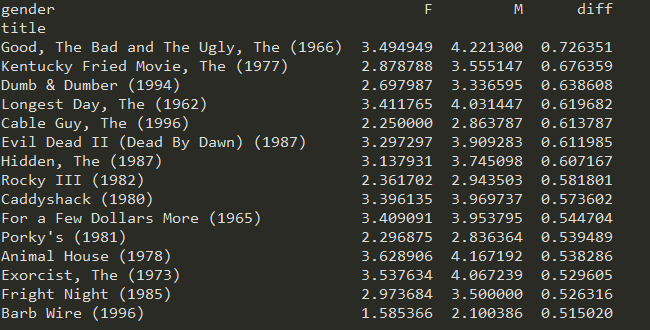
此代码中还展示了为DataFrame添加列,即直接name_DataFrame['diff']=___即可,同时可以依据新添加的列元素的值,来对dataframe进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import pandas as pdunames = ['user_id', 'gender', 'age','occupation','zip']users = pd.read_table('users.dat', sep='::',header=None, names=unames)rnames = ['user_id', 'movie_id', 'rating', 'timestamp']ratings = pd.read_table('ratings.dat', sep='::', header=None, names=rnames)mnames = ['movie_id', 'title', 'genres']movies = pd.read_table('movies.dat', sep='::', header=None, names=mnames)data = pd.merge(pd.merge(ratings,users),movies)mean_ratings = pd.pivot_table(data,index=['title'],values='rating',columns='gender')print(mean_ratings[:10])ratings_by_title = data.groupby('title').size()print(ratings_by_title[:10])active_titles = ratings_by_title.index[ratings_by_title >= 250]print(active_titles)active_mean_ratings = mean_ratings.loc[active_titles]top_female_ratings = active_mean_ratings.sort_index(by='F', ascending=False)active_mean_ratings['diff'] = active_mean_ratings['M'] - active_mean_ratings['F']sorted_by_diff = active_mean_ratings.sort_index(by='diff')print(sorted_by_diff[::-1][:15]) #注意对dataframe进行倒序访问的方法 |

标签:
Python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架