数据分组分析—-groupby
代码功能:
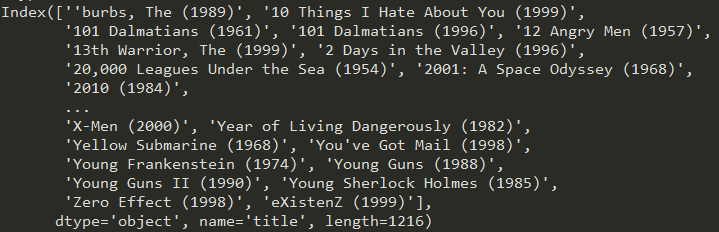
对于综合表格data,基于title进行分组处理,并统计每一组的size,得到的是一个series序列,此序列可以放入索引中使用,index()
import pandas as pd unames = ['user_id', 'gender', 'age','occupation','zip'] users = pd.read_table('users.dat', sep='::',header=None, names=unames) rnames = ['user_id', 'movie_id', 'rating', 'timestamp'] ratings = pd.read_table('ratings.dat', sep='::', header=None, names=rnames) mnames = ['movie_id', 'title', 'genres'] movies = pd.read_table('movies.dat', sep='::', header=None, names=mnames) data = pd.merge(pd.merge(ratings,users),movies) mean_ratings = pd.pivot_table(data,index=['title'],values='rating',columns='gender') print(mean_ratings[:10]) ratings_by_title = data.groupby('title').size() print(ratings_by_title[:10]) active_titles = ratings_by_title.index[ratings_by_title >= 250] print(active_titles)
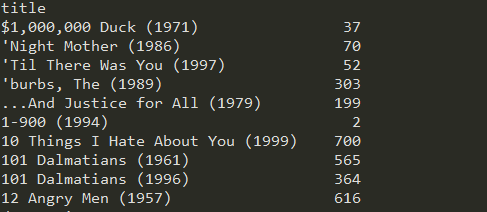
对得到的序列使用index()过滤处理后,不知道是个什么内行的量,打印出来结果如下: