

使用透视表pivot_table
功能:从一张大而全的表格中提取出我们需要的信息来分析
import pandas as pd unames = ['user_id', 'gender', 'age','occupation','zip'] users = pd.read_table('users.dat', sep='::',header=None, names=unames) rnames = ['user_id', 'movie_id', 'rating', 'timestamp'] ratings = pd.read_table('ratings.dat', sep='::', header=None, names=rnames) mnames = ['movie_id', 'title', 'genres'] movies = pd.read_table('movies.dat', sep='::', header=None, names=mnames) data = pd.merge(pd.merge(ratings,users),movies) mean_ratings = pd.pivot_table(data,index=['title'],values='rating',columns='gender') print(mean_ratings[:10])
表头里面的信息就是title, gender, 表中的内容为rating.
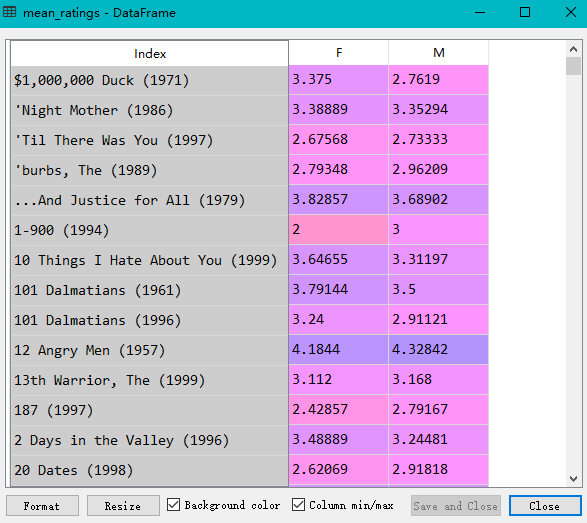
使用切片浏览前十行数据:
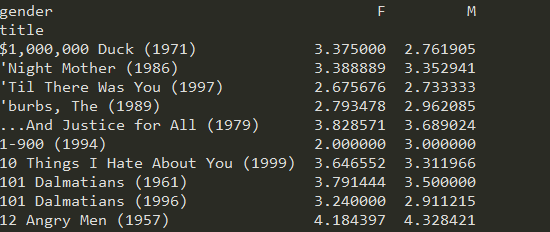
理论依据:


