数据采集与融合技术——实验三
作业①
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
实现过程
- 单线程实现过程及代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/%E4%BD%9C%E4%B8%9A3/1%E5%8D%95%E7%BA%BF%E7%A8%8B.py
1.解析网页
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码为汉字编码
url='http://www.weather.com.cn/'
header = 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
html=requests.get(url,header)
data=html.text
count = 1
#print(data)
2.正则表达式的构建
s1='<img src=\"(.*?)[png,jpg]\"'#匹配图片地址
s2='href=\"(.*?)\"'#匹配子网址
3.爬取该网页下及子网页的所有图片下载链接
for tag in tags:
tag = tag +'g'
print('下载图片的地址是:'+tag)
urllib.request.urlretrieve(tag, '陈硕爬取的书包图片' + str(count) + '.jpg')
count+=1
if count>104:
break
lis = re.findall(s2,data)
for li in lis:
ht = requests.get(li)
dt = ht.text
img_ls = re.findall(s1,dt)#匹配子网址中的图片地址
for img in img_ls:
img = img +'g'
print('下载图片的地址是:' + img)
urllib.request.urlretrieve(img, '陈硕爬取的书包图片' + str(count) + '.jpg')
count+=1
if count>104:
break
if count>104:
break
4.输出结果
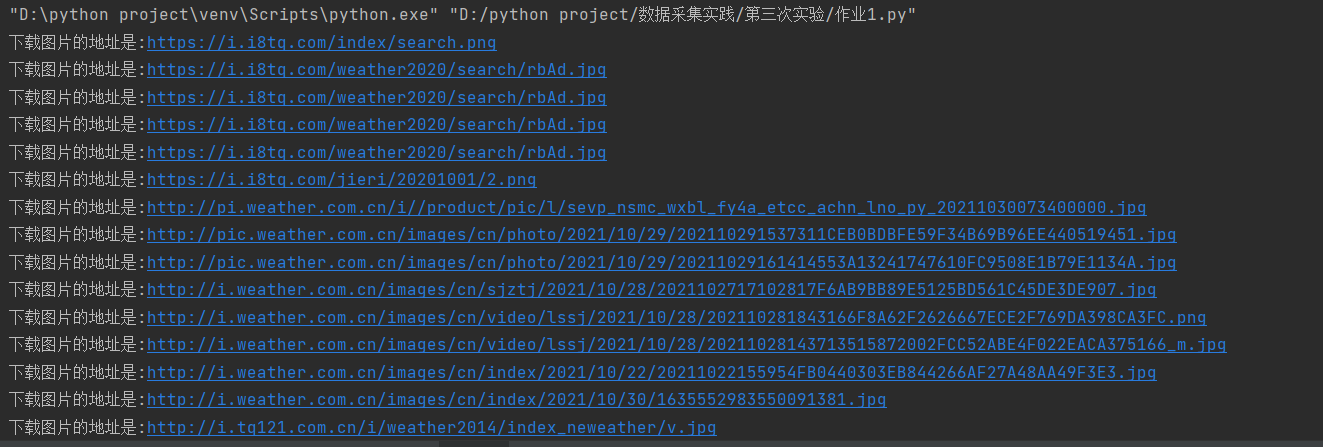
5.爬取下载结果
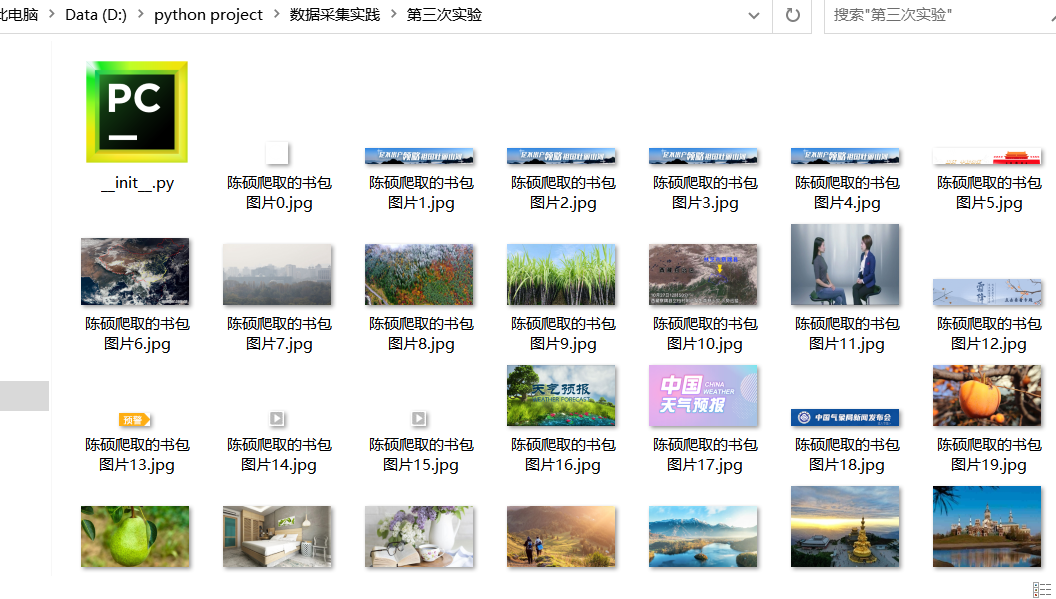
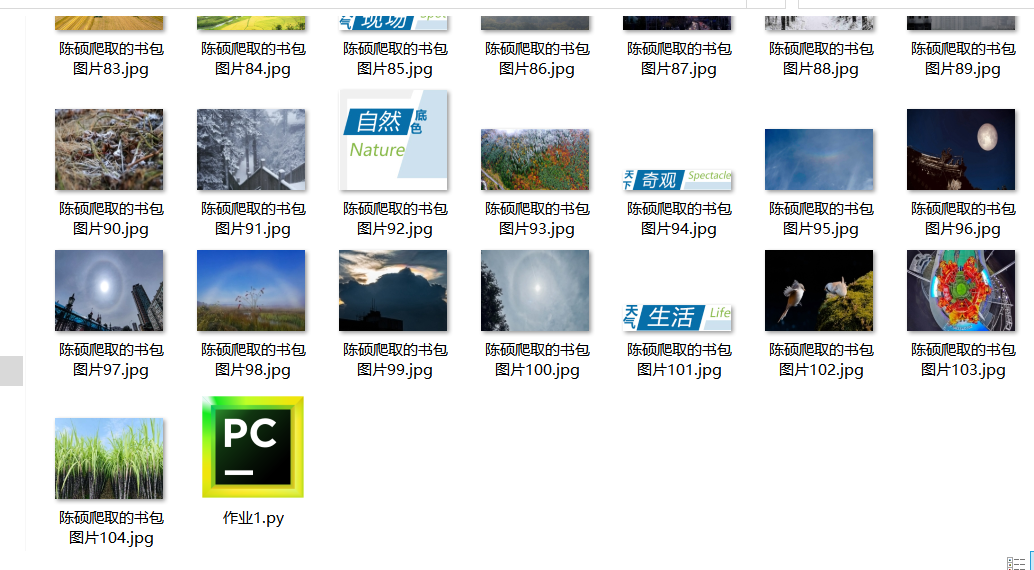
- 多线程实现过程及代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/%E4%BD%9C%E4%B8%9A3/1%E5%A4%9A%E7%BA%BF%E7%A8%8B.py
1.将urllib.request.urlretrieve方法封装为download方法,再使用threading进行并发处理。
def download(url,name):
urllib.request.urlretrieve(url)
for tag in tags:
tag = tag +'g'
print('下载图片'+str(count)+'的地址是:'+tag)
T = threading.Thread(target=download(tag, '陈硕爬取的书包图片' + str(count) + '.jpg'))
T.setDaemon(False)
T.start()
count+=1
if count>104:
break
lis = re.findall(s2,data)
for li in lis:
ht = requests.get(li)
dt = ht.text
img_ls = re.findall(s1,dt)#匹配子网址中的图片地址
for img in img_ls:
img = img +'g'
print('下载图片' + str(count) + '的地址是:' + tag)
T = threading.Thread(target=download(img, '陈硕爬取的书包图片' + str(count) + '.jpg'))
T.setDaemon(False)
T.start()
count+=1
心得体会
- 复习了并发的使用,对并发有了更加深刻的了解。
- 复习了正则表达式的写法
作业②
-
要求:使用scrapy框架复现作业①。
-
输出信息:同作业①
实现过程
代码实现:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A3/%E7%AC%AC%E4%BA%8C%E9%A2%98
1.编写weather.py爬虫主程序
# -*- coding:utf-8 -*-
import scrapy
from ..items import Exp3Item
#031904104 陈硕
class WeatherSpider(scrapy.Spider):
name = 'weather'
start_urls = ['http://p.weather.com.cn/txqg/index.shtml']
global count
count = 0 # 计数,爬取学号后三位104项后就停止
def get_urllist(self,response):
urls = response.xpath('//div[@class="tu"]/a/@href').extract()#匹配子网址
for url in urls:
if self.count>104:
break
yield scrapy.Request(url=url, callback=self.get_imgurl)
def get_imgurl(self, response):
global count
item = Exp3Item()
img_url=response.xpath('//div[@class="buttons"]/span/img/@src')
for i in img_url:
count+=1
url=i.extract()
if self.count<=104:
item['img_url']=url
yield item
pass
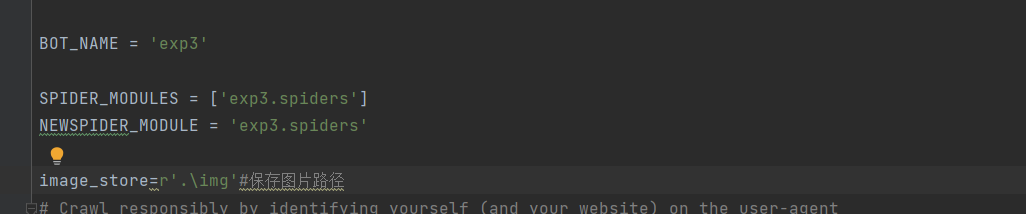
2.setting.py
将机器人协议改为False,设置存储路径,以及爬虫优先级
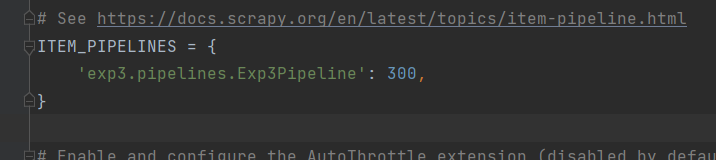
3.编写pipelines.py文件
import requests
class Exp3Pipeline:
def open_spider(self, spider):
self.num = 1
def process_item(self, item, spider):
url = item['img_url']
resp = requests.get(url)
img = resp.content
with open('D:\image\%d' % (self.num) + '.jpg', 'wb') as f:
f.write(img)
print('%d' % (self.num))
self.num += 1
return item
4.编写item.py
import scrapy
class Exp3Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_url = scrapy.Field() #图片url地址
pass
5.编写run.py,模拟命令行运行爬虫
# -*- coding:utf-8 -*-
from scrapy import cmdline
import sys
sys.path.append(r'D:\python project\exp3\exp3spiders\weather')#添加爬虫路径,防止报错找不到路径
cmdline.execute('scrapy crawl weather'.split())#运行爬虫
6.爬取结果
- 报错: ERROR: Spider error processing <GET http://p.weather.com.cn/txqg/index.shtml> (referer: None)

通过查询资料,发现可能是两个方面的问题: - ①.xpath表达式解析错误(会导致爬虫解析dom失败),在询问过大佬后,我重构了表达式,这方面应该没问题
- ② 机器人协议为设置为False,在检查过setting文件后,发现已经修改,应该不是这个问题。
但是这两个问题都解决后,还是报错。
心得体会
- 复习了scrapy的使用,对scrapy有了一个更深的了解,确切感受到scrapy爬取速度确实比较快。
作业③
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
候选网站: https://movie.douban.com/top250
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
实现过程
代码链接:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A3/%E7%AC%AC%E4%B8%89%E9%A2%98
1.items类
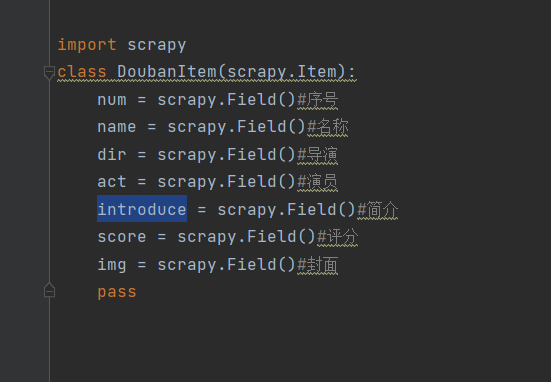
2.settings
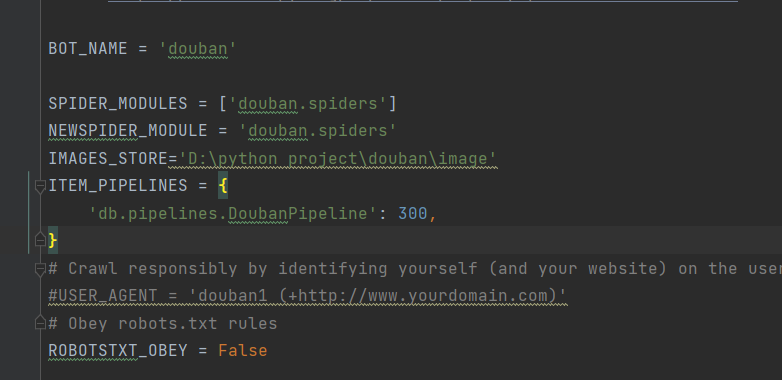
3.爬虫db.py
# -*- coding:utf-8 -*-
from urllib.request import Request
import scrapy
import re
from douban.items import DoubanItem
class DbSpider(scrapy.Spider):
def start_requests(self):
##翻页处理
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
yield Request(url=url, callback=self.parse1)
##xpath选择对应的项目内容传入item
def parse1(self, response):
global count
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 获取每个电影项目
movies = selector.xpath(
"//ol[@class='grid_view']/li")
##选择每个电影标签下的对应标签内容
for i in movies:
image = i.xpath("./div[@class='item']/div[@class='pic']/a/img/@src").extract_first()
name = i.xpath(
"./div[@class='item']/div[@class='info']/div[@class='hd']//span[@class='title']/text()").extract_first()
dir = i.xpath(
"./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='']/text()").extract_first()
desp = i.xpath(
"./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='quote']/span/text()").extract_first()
grade = i.xpath(
"./div[@class='item']/div[@class='info']/div[@class='bd']/div/span[@class='rating_num']/text()").extract_first()
print(image)
##正则转换导演和主演,便于后续获取相应内容
dir = dir.replace(' ', '')
dir = dir.replace('\n', '')
dir = dir + '\n'
director = re.findall(r'导演:(.*?)\s', dir)
actor = re.findall(r'主演:(.*?)\n', dir)
count += 1
item = DoubanItem()
# 保存到对应item
item['num'] = str(count)
item['name'] = str(name)
item['dir'] = str(director[0])
if (len(actor) != 0): ##由于有动画片没有演员或者由于导演名过长导致演员无法显示,actor可能为空
item['act'] = str(actor[0])
else:
item['actor'] = 'null'
item['introduce'] = str(desp)
item['score'] = str(grade)
item['img'] = str(image)
yield item
pass
4.pipeline类
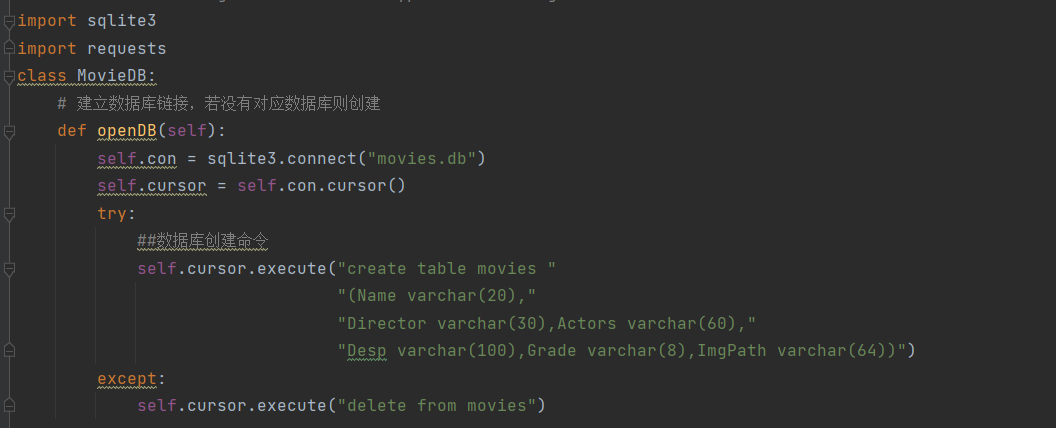
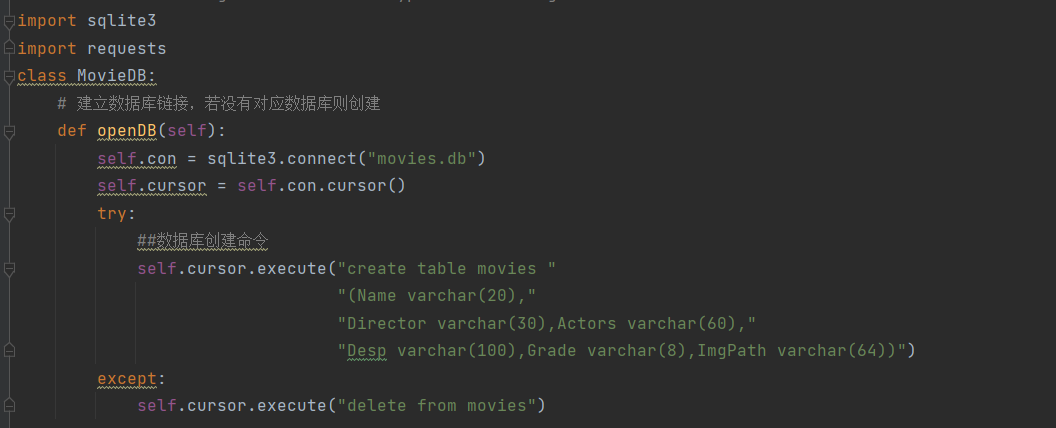
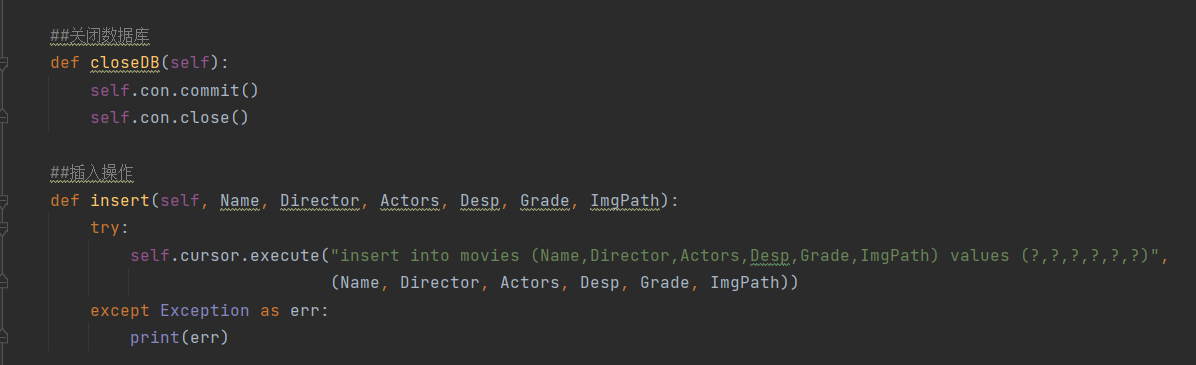
心得体会
进一步加深了对scrapy框架的了解,不过对管道类的使用还是不太熟悉,还要加强。
