
爬虫综合大作业
爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
1.选择主题:豆瓣电影网,复仇者联盟4 用户评论

2.爬取对象:爬取复仇者联盟4 里的短评
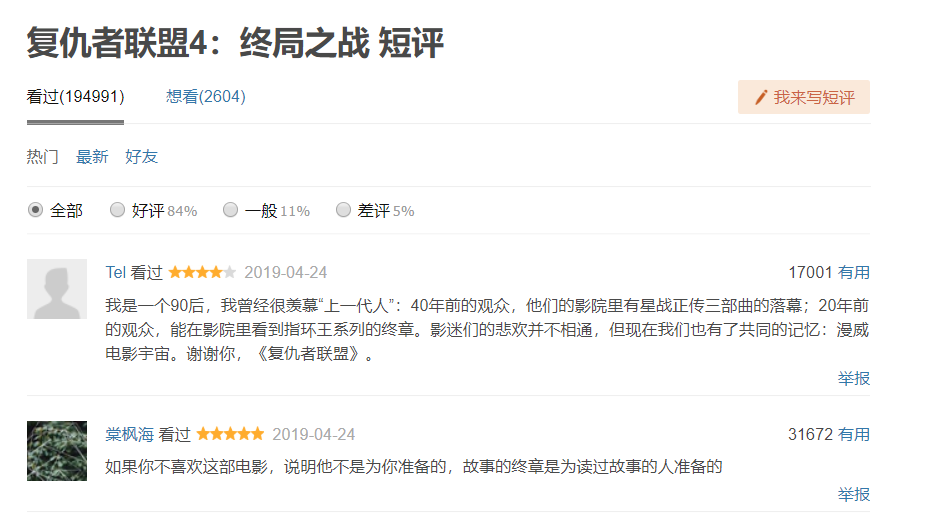
爬取网址规律:每一页的网址都只有改变一个地方 start = (开始为0,每加一页数值加20)


3.了解爬取对象的限制与约束:在未登录的情况下只能查看到一部分的评论
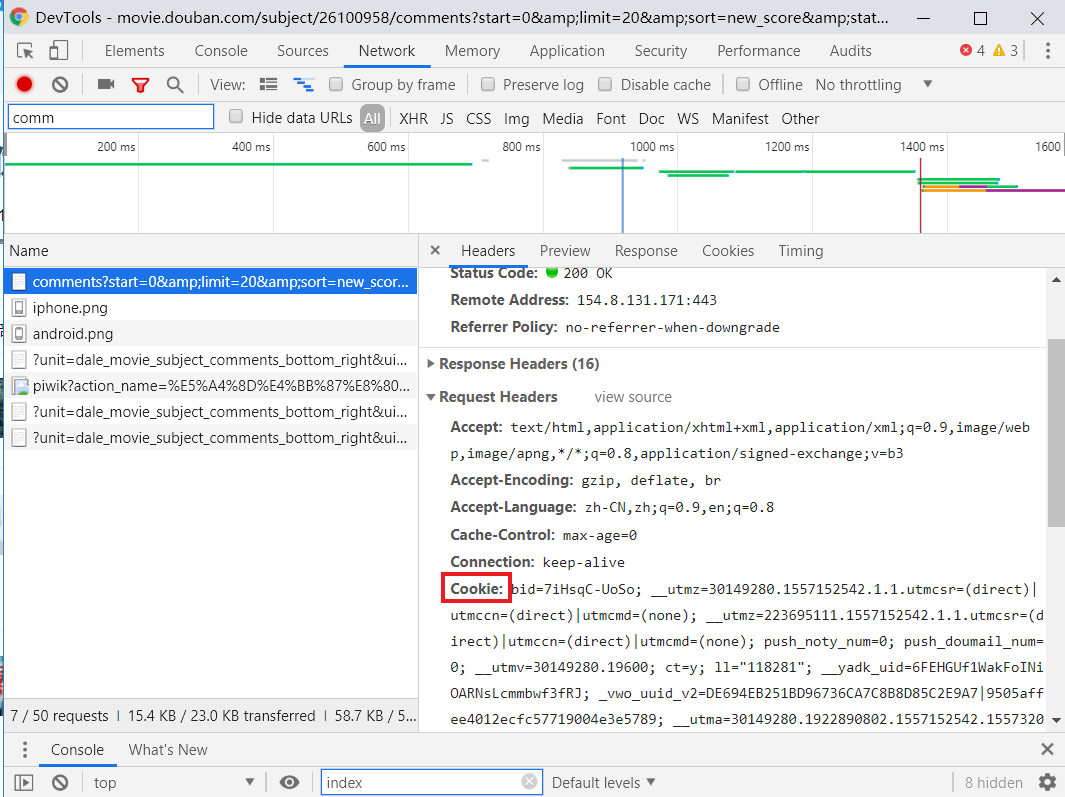
解决办法:在发送获取网页信息之时把cookie信息也一起发送。
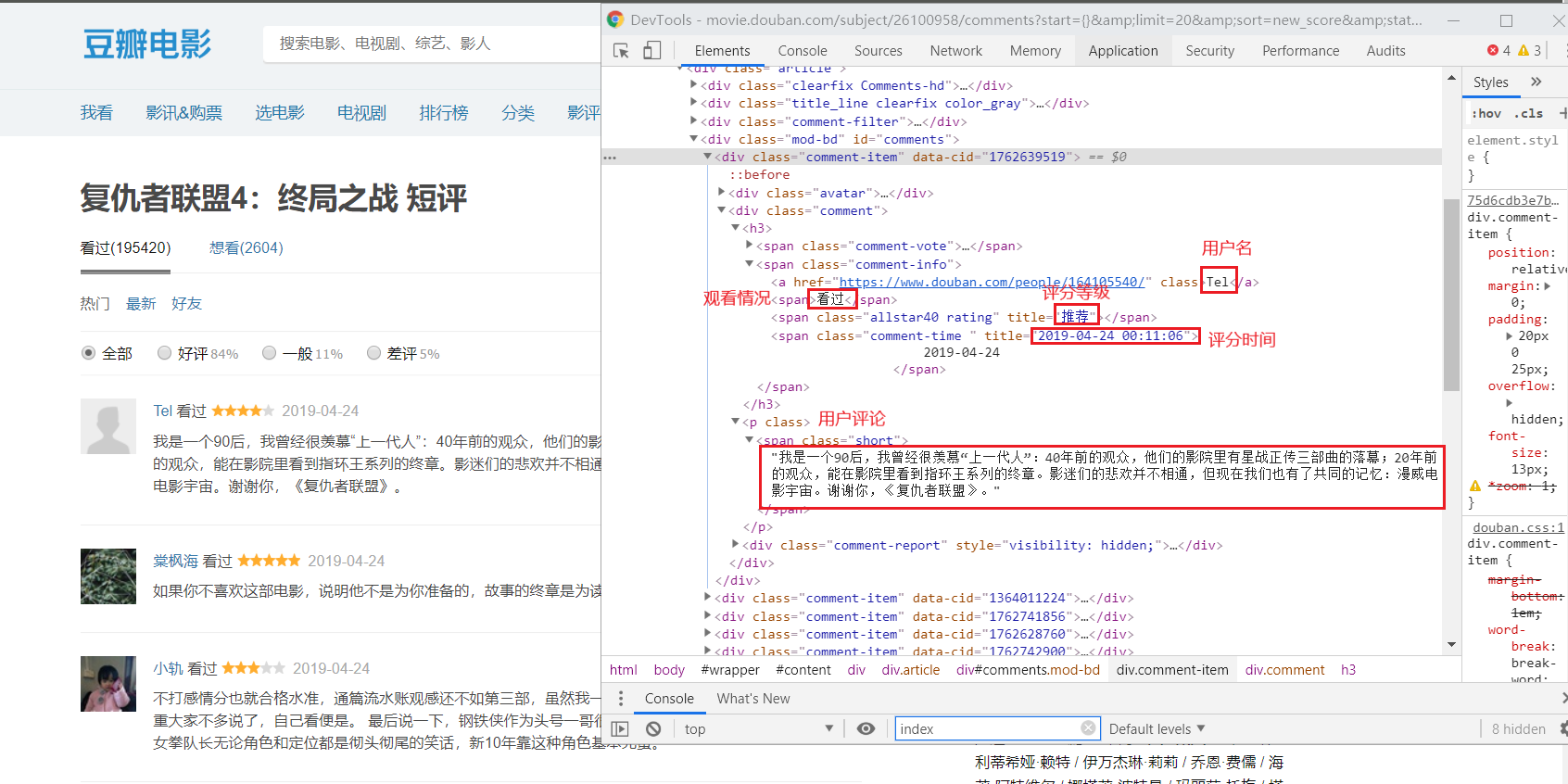
爬取相应内容:
import pandas
import requests
from bs4 import BeautifulSoup
import time
import random
import re
def getHtml(url):
cookies = {'PHPSESSID':'Cookie: bid=7iHsqC-UoSo; ap_v=0,6.0; __utma=30149280.1922890802.1557152542.1557152542.1557152542.1;
__utmc=30149280; __utmz=30149280.1557152542.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1923787146.1557152542.1557152542.1557152542.1;
__utmb=223695111.0.10.1557152542; __utmc=223695111; __utmz=223695111.1557152542.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none);
_pk_ses.100001.4cf6=*; push_noty_num=0; push_doumail_num=0; __utmt=1; __utmv=30149280.19600; ct=y; ll="118281";
__utmb=30149280.12.9.1557154640902; __yadk_uid=6FEHGUf1WakFoINiOARNsLcmmbwf3fRJ;
_vwo_uuid_v2=DE694EB251BD96736CA7C8B8D85C2E9A7|9505affee4012ecfc57719004e3e5789;
_pk_id.100001.4cf6=1f5148bca7bc0b13.1557152543.1.1557155093.1557152543.; dbcl2="196009385:lRmza0u0iAA"' }
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = requests.get(url,headers=headers,cookies=cookies,verify=False);
req.encoding='utf8'
soup = BeautifulSoup(req.text,"html.parser")
return soup;
def getText(soup):
comment = []
for pl in soup.select('.comment-item'):
comment_b = {}
user=pl.select('.comment-info')[0]('a')[0].text
look=pl.select('.comment-info')[0]('span')[0].text
score = pl.select('.comment-info')[0]('span')[1]['title']
time = pl.select('.comment-time ')[0]['title']
pNum = pl.select('.votes')[0].text
text = pl.select('.short')[0].text
text2=text.replace('\n', ' ')
comment_b['用户名']=user
comment_b['观看情况']=look
comment_b['评分情况']=score
comment_b['评论时间']=time
comment_b['评论']=text2
comment_b['赞同次数']=pNum
comment.append(comment_b)
print('-----------------爬取成功 ',len(comment),' 条----------------')
return comment;
url = 'https://movie.douban.com/subject/26100958/comments?start={}&limit=20&sort=new_score&status=P';
# url= 'https://movie.douban.com/subject/26100958/reviews?start={}'
comment=[]
for i in range(25):
soup=getHtml(url.format(i*20))
comment.extend(getText(soup))
time.sleep(random.random() * 3)
print(len(comment))
# print(getText(soup))
print('--------------------------总共爬取 ',len(comment),' 条-------------------------')
print(comment)
f1 = pandas.DataFrame(comment)
f1.to_csv(r'E:\f4.csv',encoding='utf_8_sig')
爬取到的评论信息:
这次我们爬取到的信息有:用户名、观看情况、评分情况、评论、评论时间和赞同次数

评论整理:将爬取到的评论信息进行处理,最后经过词频统计。将出现次数最多排名TOP20的词语做成词云。
import pandas as pd
import jieba
import csv
pinglun =[]
csv_reader = csv.reader(open(r'C:\Users\Shinelon\Desktop\f4.csv',encoding='utf-8'))
for row in csv_reader:
pinglun.append(row[4])
text=' '.join(pinglun)
# 加入所分析对象的专业词汇
with open(r'C:\Users\Shinelon\Desktop\最火复仇者联盟词库大全【官方推荐】.txt', 'r', encoding='utf-8') as f:
jinyong = f.read().split('\n')
jieba.load_userdict(jinyong)
newtext = jieba.lcut(text)
with open(r'C:\Users\Shinelon\Desktop\爬虫\python 3.22\stops_chinese.txt', 'r', encoding='utf-8') as f:
stops = f.read().split('\n')
newtext2 = [text1 for text1 in newtext if text1 not in stops]
te = {};
for w in newtext2:
if len(w) == 1:
continue
else:
te[w] = te.get(w, 0) + 1
print(te)
# 次数排序
tesort = list(te.items())
tesort.sort(key=lambda x: x[1], reverse=True)
# 输出次数前TOP20的词语
for i in range(0, 20):
print(tesort[i])
pd.DataFrame(data=tesort[0:20]).to_csv('fu4c.csv', encoding='utf-8')
生成词云图:

电影评分情况统计:对获取到的用户评分情况进行统计。
import pandas as pd
import jieba
import csv
pingfen =[]
csv_reader = csv.reader(open(r'C:\Users\Shinelon\Desktop\f4.csv',encoding='utf-8'))
for row in csv_reader:
pingfen.append(row[3])
del pingfen[0]
# 将词语与其出现的次数以键/值对方式存储
te = {};
for w in pingfen:
te[w] = pingfen.count(w);
print(te.items())
temp = 1;
pingfenlist = {}
for i in te.items():
if(temp<6):
pingfenlist[i[0]] = i[1]
else:
break
temp = temp + 1
print(pingfenlist)
pd.DataFrame(data=list(pingfenlist.items())).to_csv('pingfen.csv', encoding='utf-8')
评分情况图表:
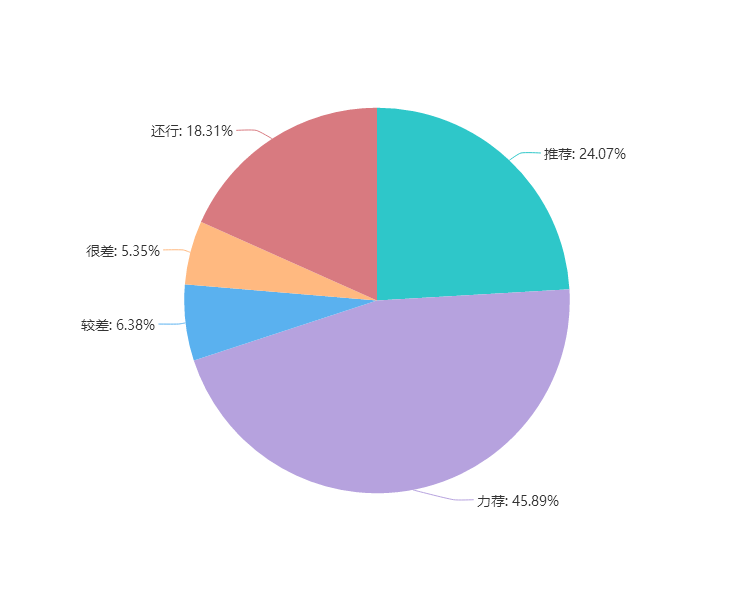
总结:
在本次爬取到的影片评论信息复仇者联盟4中我们可以看出70%观众对这部影片还是持有着推荐的态度。认为该影片值得一看。
而在用户评论中出现次数最多的‘漫威’、‘复联’、‘英雄’、‘钢铁侠’、‘美队’、‘雷神’、‘灭霸’等词可以看出本片大概的主题内容。
总的来说,复仇者联盟4,还是可以一看。

