


机器学习之二:K-近邻(KNN)算法
一、概述
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
二、原理
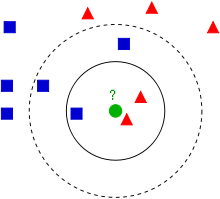
基本思路是:如果一个样本在特征空间中的 k 个最相似即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
三、优缺点
1、优点:
1)精度高,对异常值不敏感、无数据输入假定;
2)KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。
3)由于 KNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN 方法较其他方法更为适合。
4)KNN 算法不仅可以用于分类,还可以用于回归。
2、缺点:
1)计算复杂度高:KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
2)空间复杂度高:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
四、注意的问题
1、K的选择
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
2、距离衡量
常用的欧氏距离,马氏距离,夹角余弦距离等。
3、分类样本平衡
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。此时可压缩样本较多的数据类别,或者采用权重系数评判测试点属于哪个类别
五、算法步骤
1)算距离:计算已知类别数据集中的点与当前点之前的距离;
2)找邻居:找出距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻出现频率最高的类别作为测试对象的预测分类
六、示例代码(Python)
from numpy import *
import operator
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
print 'dataSetSize=',dataSetSize
diffMat = tile(inX,(dataSetSize,1)) - dataSet
print tile(inX,(dataSetSize,1))
print 'diffMat=',diffMat
sqDiffMat = diffMat**2
print 'sqDiffMat=',sqDiffMat
sqDistances = sqDiffMat.sum(axis=1)
print 'sqDistances=',sqDistances
distances = sqDistances**0.5
print 'distances=',distances
sortedDistIndicies = distances.argsort()
print sortedDistIndicies
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
print sortedClassCount
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
group,labels = createDataSet()
print classify0([0,0],group,labels,3)
七、算法行业应用
八、算法的相关改进
KD树,样本压缩技术
九、参考文献
http://www.stanford.edu/~hastie/Papers/dann_IEEE.pdf

