


Selenium实现微博自动化运营:关注、点赞、评论
目录
Selenium 是什么?
Selenium是一个用于Web应用程序测试的工具,可以模拟真正的用户操作,支持多种浏览器,如Firefox,Safari,Google Chrome,Opera等。
Selenium 模拟的就是一个真实的用户的操作行为,我们完全不用担心 cookie 追踪和隐藏字段的干扰。
正好,我们公司有一个妹纸团队运营的微博粉丝挺多,叫中公题库君,我们使用Selenium实现微博自动关注她,顺便点赞和评论一下
相关帮助链接
一、核心代码
talking is cheap,话不多说,上代码!
from selenium import webdriver
import time
# 注意这里使用了我本机的谷歌浏览器驱动
browser = webdriver.Chrome(executable_path='/Users/chenqionghe/.wdm/drivers/chromedriver/79.0.3945.36/mac64/chromedriver')
# 设置用户名、密码
username = "你的用户名"
password = "你的密码"
# 打开微博登录页
browser.get('https://passport.weibo.cn/signin/login')
browser.implicitly_wait(5)
time.sleep(1)
# 填写登录信息:用户名、密码
browser.find_element_by_id("loginName").send_keys(username)
browser.find_element_by_id("loginPassword").send_keys(password)
time.sleep(1)
# 点击登录
browser.find_element_by_id("loginAction").click()
time.sleep(1)
# 通过人机验证,找到那个小点点击一下
browser.find_element_by_class_name("geetest_radar_tip").click()
# 打开我们的中公题库君的首页
browser.get('https://m.weibo.cn/u/5430882137')
# 加关注
follow_button = browser.find_element_by_xpath('//div[@class="m-add-box m-followBtn"]')
follow_button.click()
time.sleep(1)
# 这时候弹出了选择分组的框,定位取消按钮
group_button = browser.find_element_by_xpath('//a[@class="m-btn m-btn-white m-btn-text-black"]')
group_button.click()
time.sleep(1)
# 这时候我们就关注成功了,好,接下来,我们给题库君点赞和评论一下
# 找到第二条微博,因为第一条微博都是置顶的
second_weibo=browser.find_element_by_xpath("//div[@class='card m-panel card9 weibo-member card-vip'][3]")
second_weibo.text
js = "arguments[0].scrollIntoView();"
# 将下拉滑动条滑动到当前div区域
browser.execute_script(js, second_weibo)
# 给第二条微博点赞
selector="//div[@class='card m-panel card9 weibo-member card-vip'][2]//footer/div[@class='m-diy-btn m-box-col m-box-center m-box-center-a'][3]"
a=browser.find_element_by_xpath(selector)
a.click()
# 定位第二条微博的评论处,点击
selector="//div[@class='card m-panel card9 weibo-member card-vip'][2]//footer/div[@class='m-diy-btn m-box-col m-box-center m-box-center-a'][2]"
a=browser.find_element_by_xpath(selector)
text=a.text
a.click()
# 输出评论内容
wishes="I’m super saiyan, best wishes to you !"
if text=='评论':
# 光标定位到发表评论处
comment=browser.find_element_by_tag_name('textarea')
comment.click()
# 输入评论内容
comment.send_keys(wishes)
time.sleep(1)
# 定位发送按钮
sendBtn=browser.find_element_by_class_name('m-send-btn')
else:
# 光标定位到发表评论处
focus=browser.find_element_by_css_selector('span[class="m-box-center-a main-text m-text-cut focus"]')
focus.click()
# 点击评论
comment=browser.find_element_by_tag_name('textarea')
comment.click()
# 输入评论内容
comment.send_keys(wishes)
# 定位发送按钮
sendBtn=browser.find_element_by_class_name('btn-send')
# 发表评论
sendBtn.click()
二、步骤分解
1.打开浏览器
from selenium import webdriver
import time
# 注意这里使用了我本机的谷歌浏览器驱动
browser = webdriver.Chrome(executable_path='/Users/chenqionghe/.wdm/drivers/chromedriver/79.0.3945.36/mac64/chromedriver')

2.访问微博登录页
# 打开微博登录页
browser.get('https://passport.weibo.cn/signin/login')
browser.implicitly_wait(5)
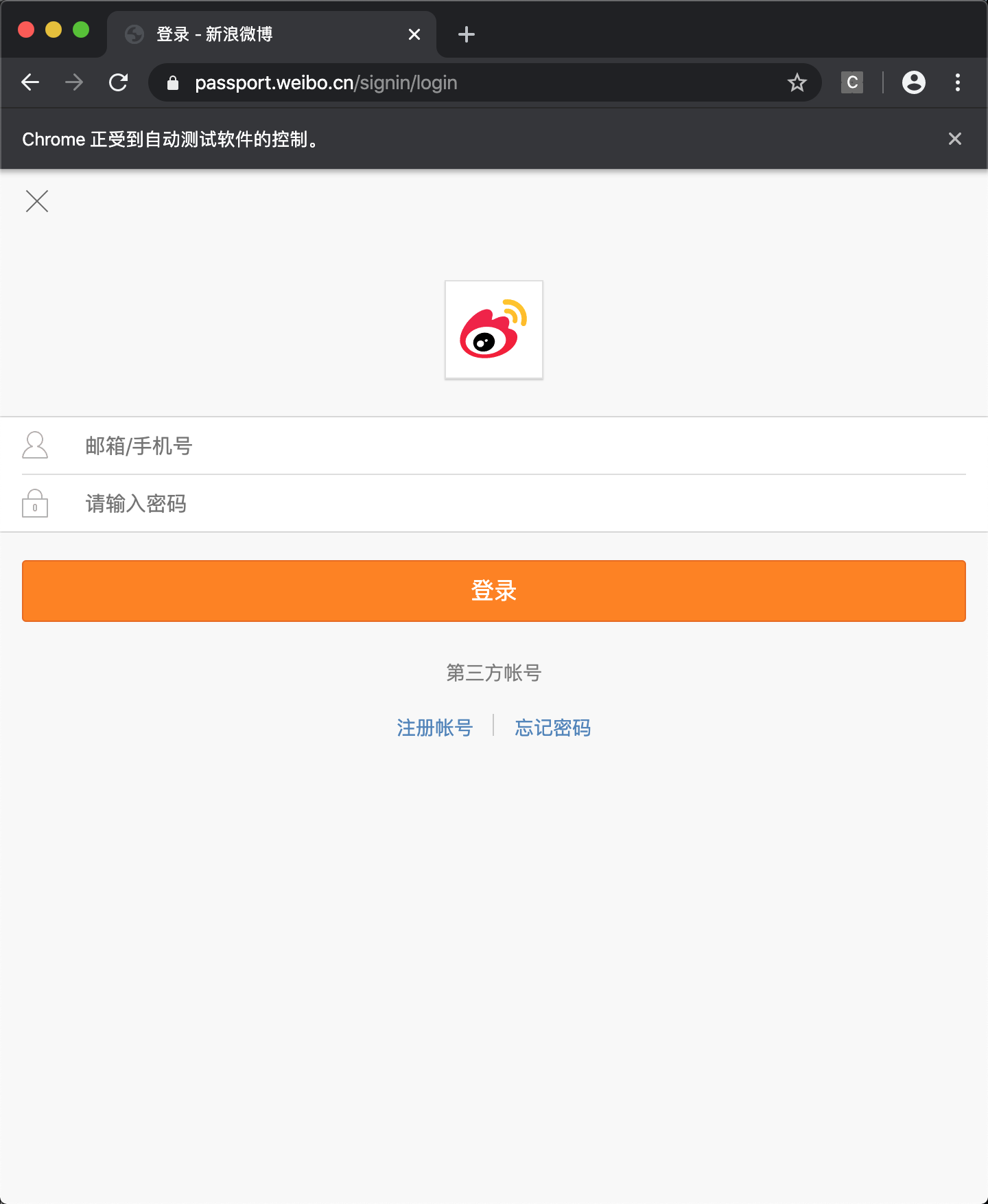
可以看到,已经打开了页面
3.输入账号密码
# 填写登录信息:用户名、密码
username = "你的用户名"
password = "你的密码"
browser.find_element_by_id("loginName").send_keys(username)
browser.find_element_by_id("loginPassword").send_keys(password)
time.sleep(1)

4.点击登录
# 点击登录
browser.find_element_by_id("loginAction").click()
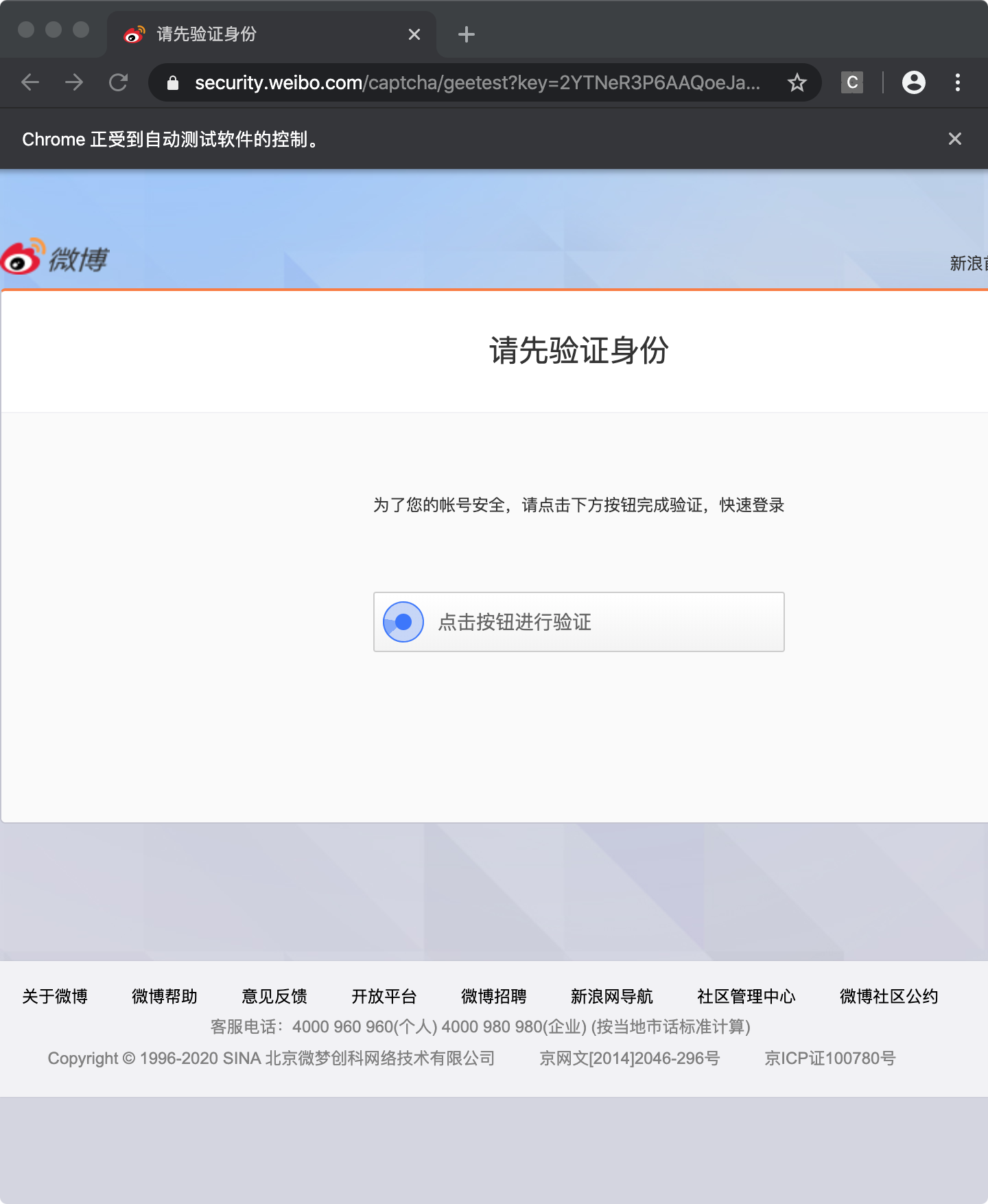
5.通过人机验证
找到那个小点点击一下
browser.find_element_by_class_name("geetest_radar_tip").click()
登录成功,如下所示
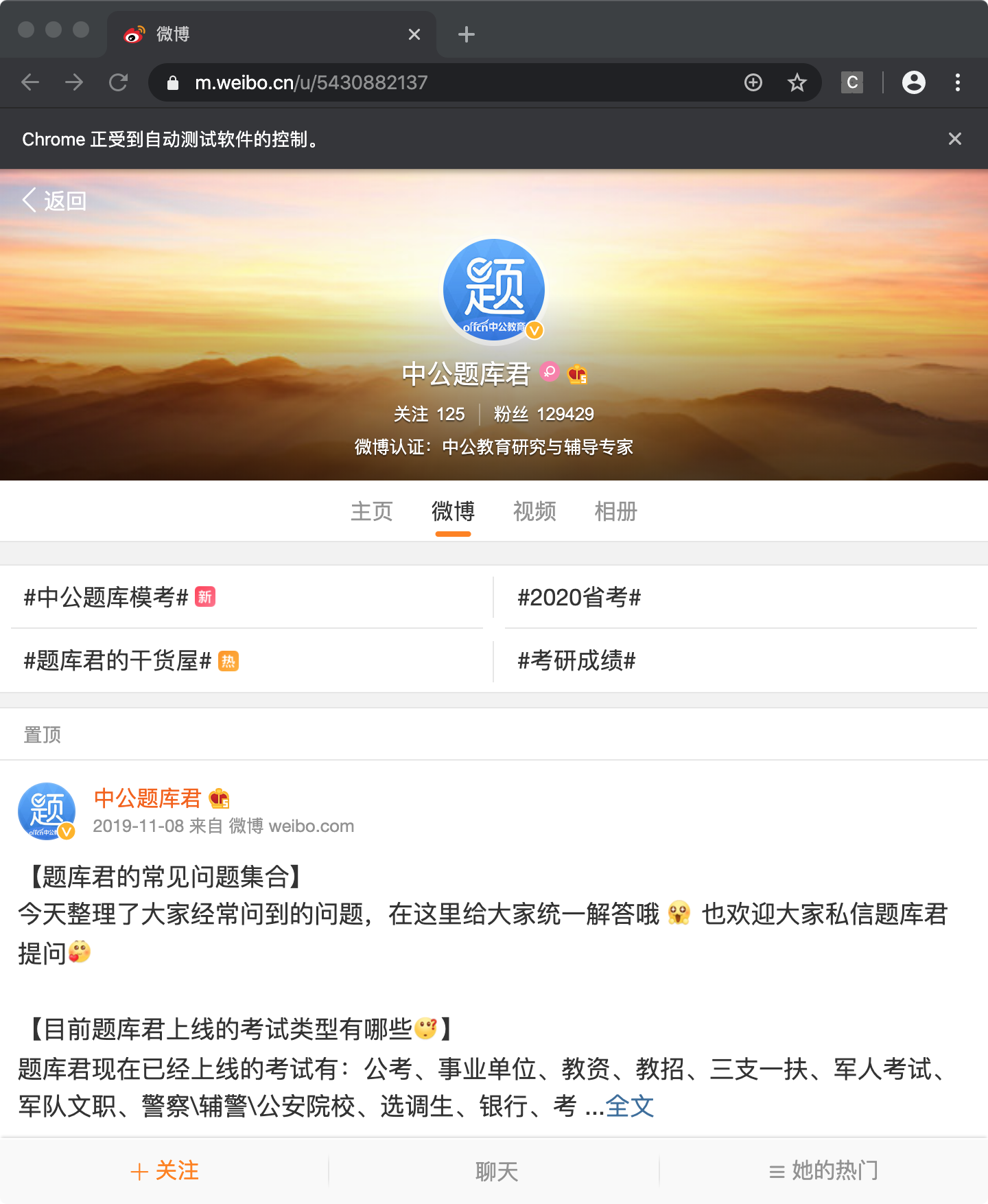
6.访问我们的中公题库君首页
browser.get('https://m.weibo.cn/u/5430882137')
7.加一下关注
#加关注
follow_button = browser.find_element_by_xpath('//div[@class="m-add-box m-followBtn"]')
follow_button.click()
time.sleep(1)
# 这时候弹出了选择分组的框,定位取消按钮
group_button = browser.find_element_by_xpath('//a[@class="m-btn m-btn-white m-btn-text-black"]')
group_button.click()
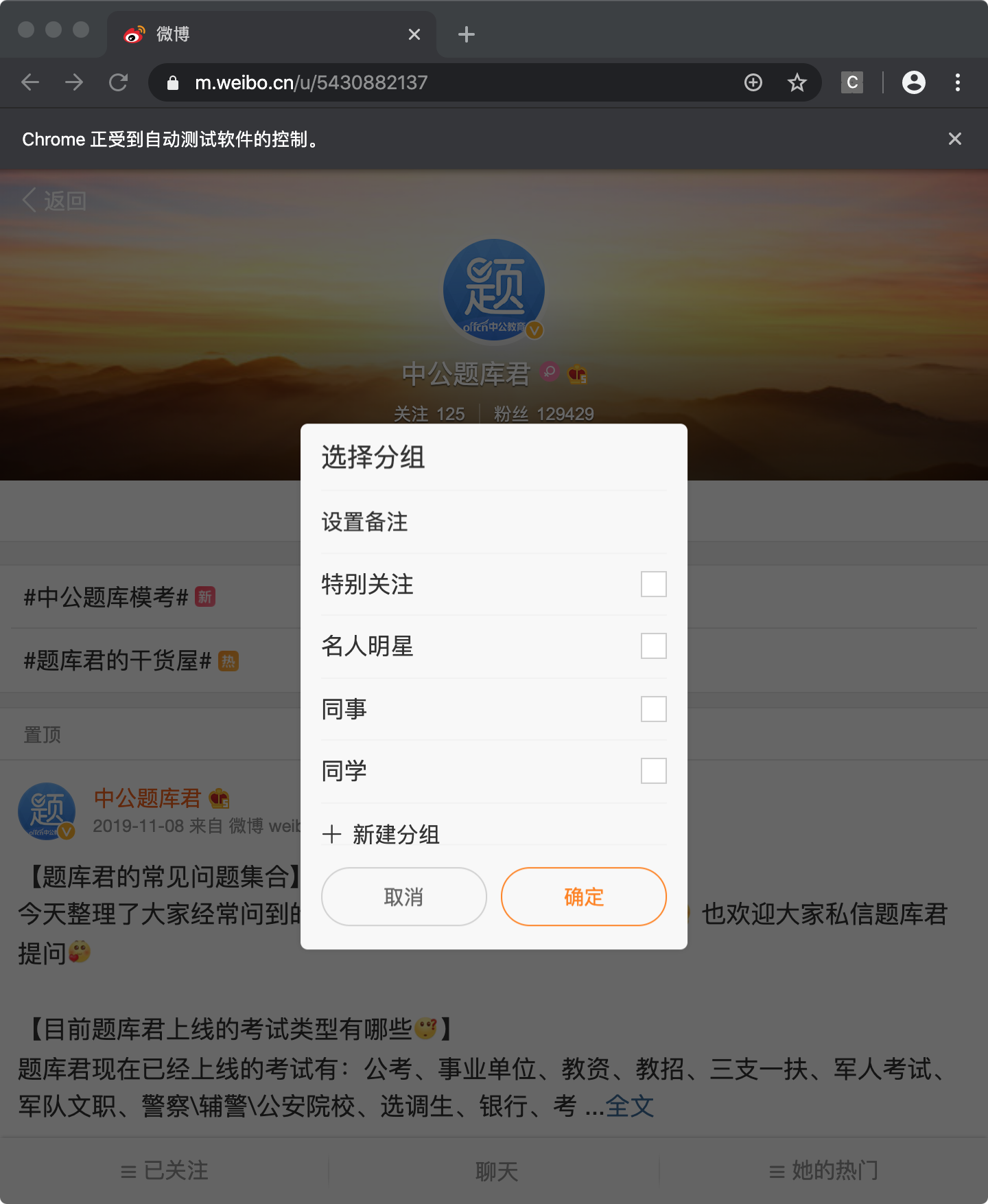
关注成功后,让选择分组,这里我直接找到取消按钮点击了一下
这时候我们就关注成功了,好,接下来,我们找到题库君非置顶的第一条微博评论一下
8.定位到第2条微博
因为第1条一般是置顶的,定位到第2条微博页面处
# 找到第二条微博,因为第一条微博都是置顶的
second_weibo=browser.find_element_by_xpath("//div[@class='card m-panel card9 weibo-member card-vip'][2]")
second_weibo.text
js = "arguments[0].scrollIntoView();"
# 将下拉滑动条滑动到当前div区域
browser.execute_script(js, second_weibo)
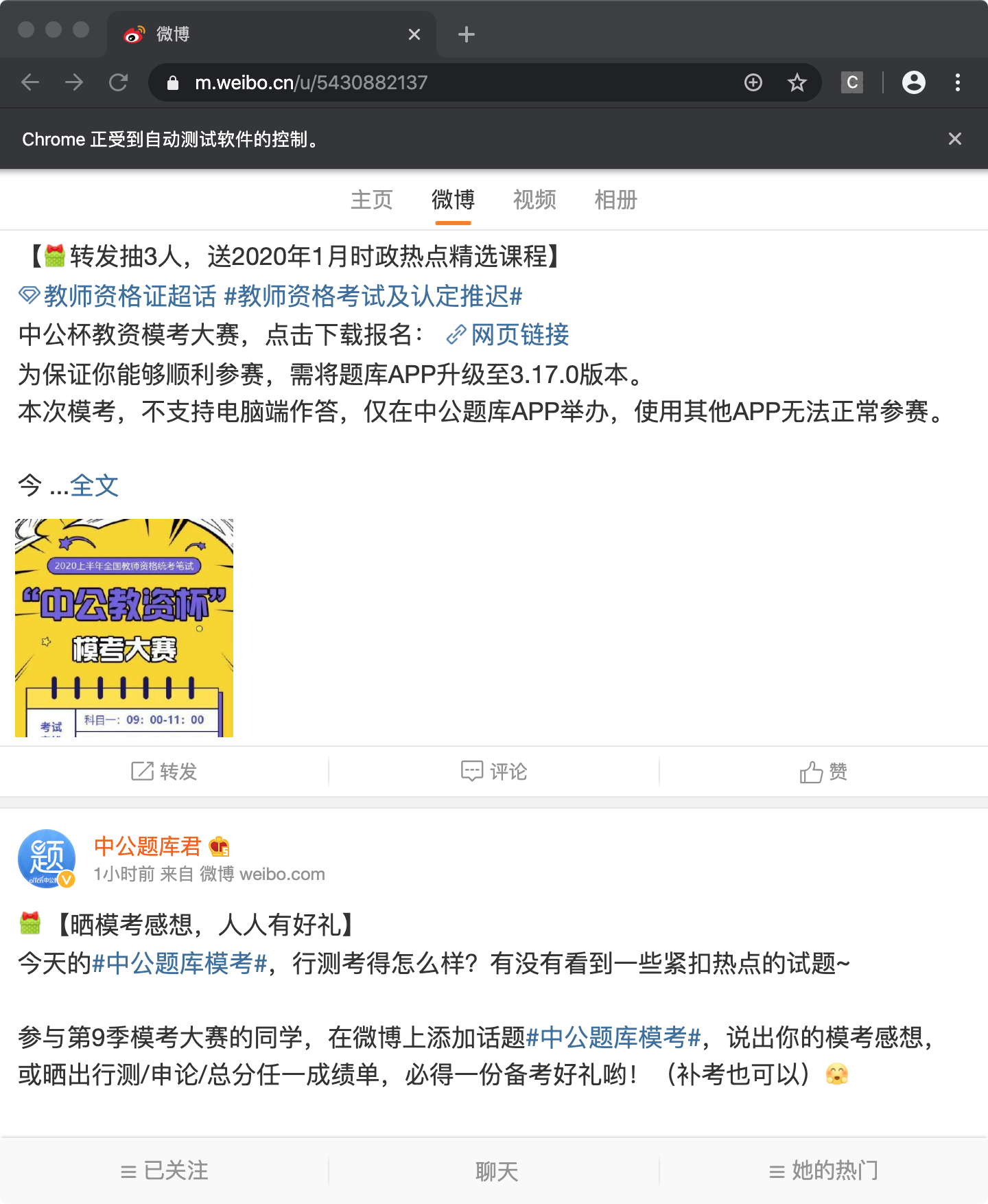
9.开始点赞
# 给第二条微博点赞
selector="//div[@class='card m-panel card9 weibo-member card-vip'][2]//footer/div[@class='m-diy-btn m-box-col m-box-center m-box-center-a'][2]"
a=browser.find_element_by_xpath(selector)
a.click()
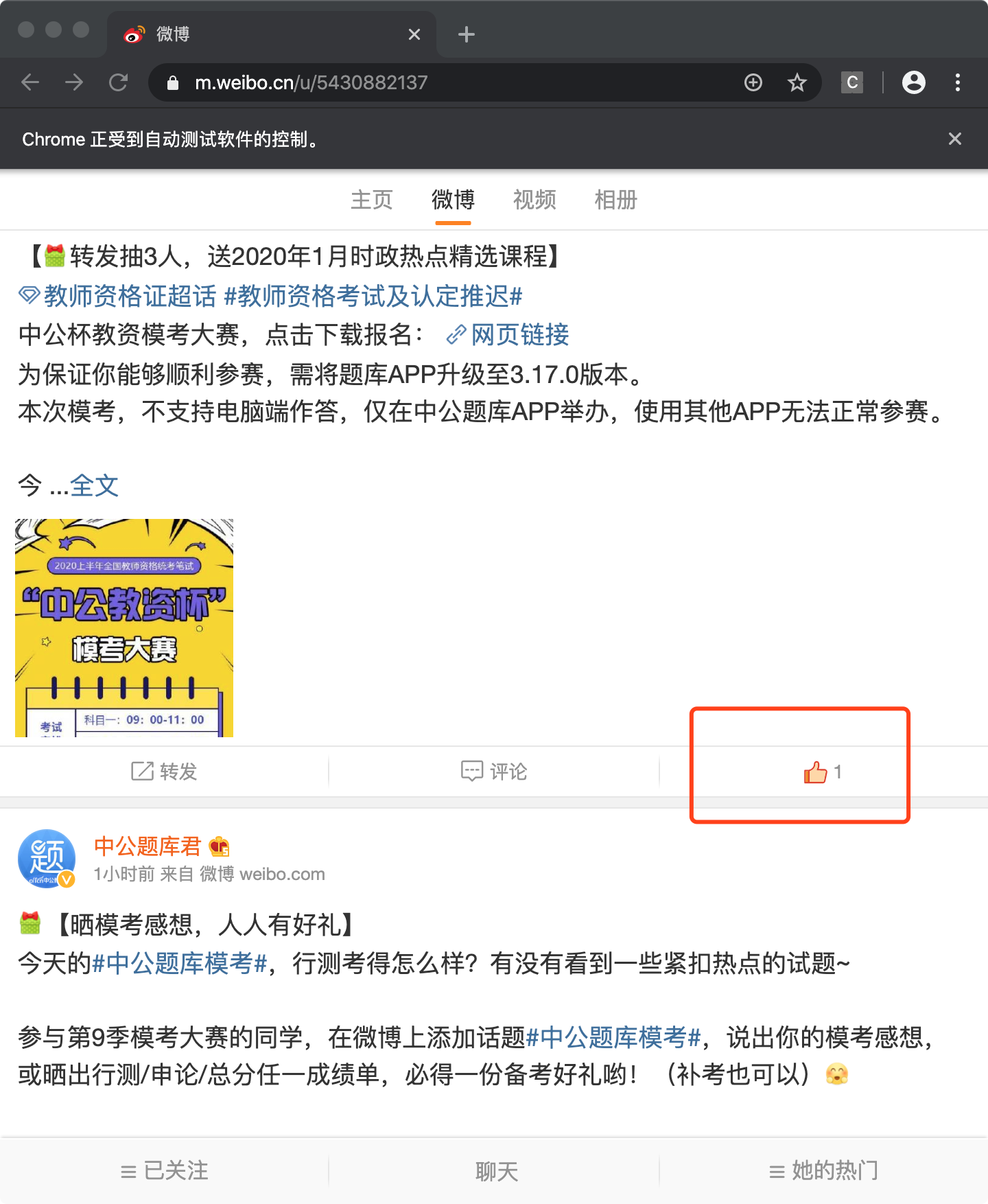
可以看到,点赞成功了
10.点击评论
#定位第二条微博的评论处
selector="//div[@class='card m-panel card9 weibo-member card-vip'][2]//footer/div[@class='m-diy-btn m-box-col m-box-center m-box-center-a'][2]"
a=browser.find_element_by_xpath(selector)
text=a.text
a.click()
这里的逻辑是,点击了,如果还没有人评论,评论框显示的文字叫<评论>,如果已经有人评论了会显示评论数量
# 输入评论内容
wishes="I’m super saiyan, best wishes to you !"
if text=='评论':
# 光标定位到发表评论处
comment=browser.find_element_by_tag_name('textarea')
comment.click()
# 输入评论内容
comment.send_keys(wishes)
time.sleep(1)
# 定位发送按钮
sendBtn=browser.find_element_by_class_name('m-send-btn')
else:
# 光标定位到发表评论处
focus=browser.find_element_by_css_selector('span[class="m-box-center-a main-text m-text-cut focus"]')
focus.click()
# 点击评论
comment=browser.find_element_by_tag_name('textarea')
comment.click()
# 输入评论内容
comment.send_keys(wishes)
# 定位发送按钮
sendBtn=browser.find_element_by_class_name('btn-send')
# 发表评论
sendBtn.click()
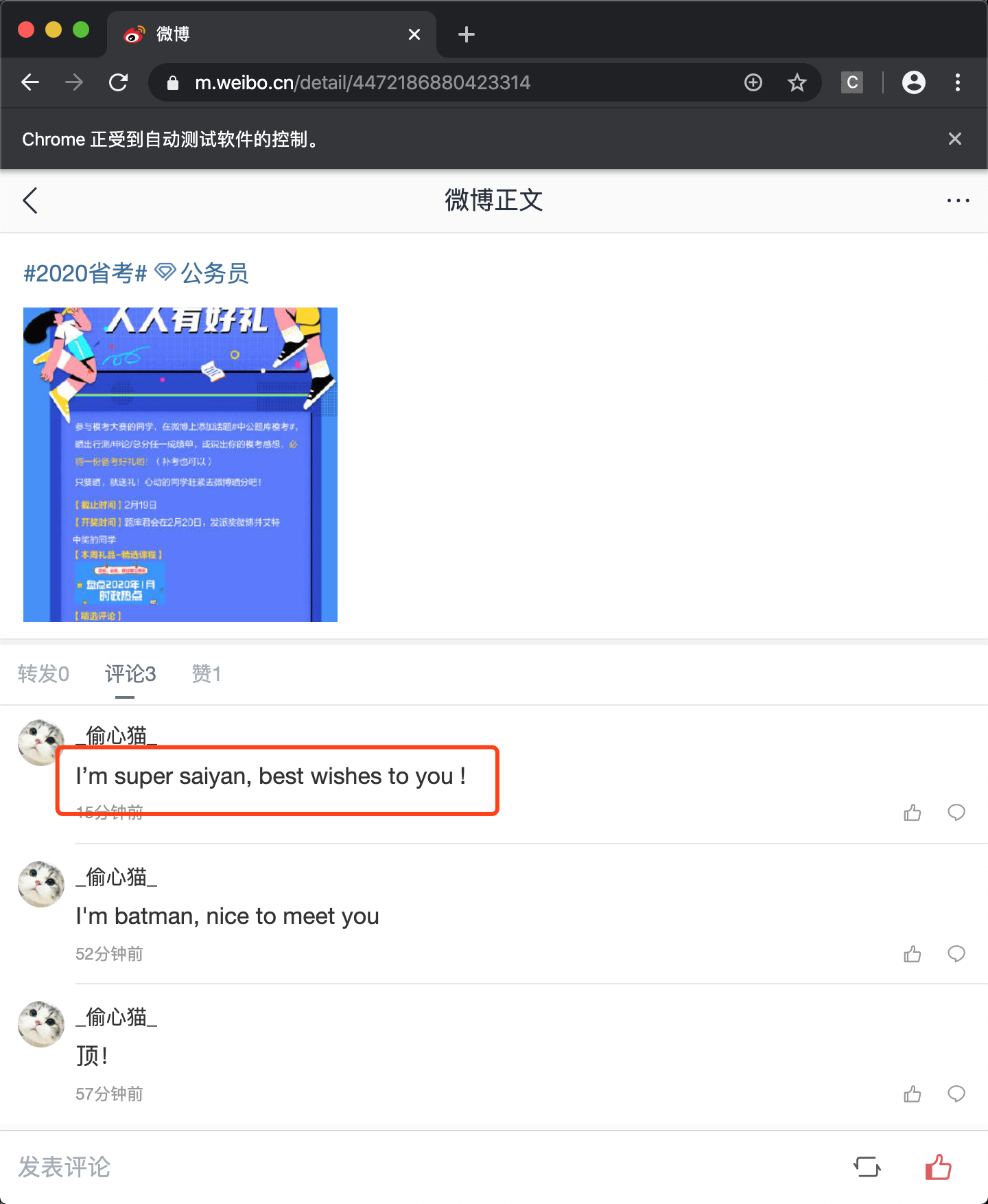
哈哈,看到已经评论成功了,到此,通过Selenium实现了微博自动化:关注、点赞、评论,感觉还挺好玩的~
三、自动化运营常用工具
- Selenium
用于 Web 测试的工具,支持多种浏览器和自动化测试 - Puppeteer
一个Nodejs的库,支持调用Chrome的API来操纵Web,能进行无头浏览模。
相比较Selenium或是PhantomJs,它最大的特点就是它的操作Dom可以完全在内存中进行模拟既在V8引擎中处理而不打开浏览器,而且关键是这个是Chrome团队在维护,会拥有更好的兼容性和前景。 - PhantomJS
基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于webkit浏览器做的事情,它都能做到,可以实现诸如网络监测、网页截屏、无需浏览器的 Web 测试、页面访问自动化等。 - lxml
python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 - Scrapy
Python开发的爬虫框架,功能强大,可以用于数据挖掘、监测和自动化测试。
Scrapy就像爬虫界的AK47,做某些大批量数据采集时简单易用,而requests就像瑞士军刀,经过专业训练的高手用它来杀敌于无形。
小的项目或者深度定制建议使用requests,大的项目,并发量大的建议使用scrapy

