关于Tcpdump抓包总结
一、简介
tcpdump是一个用于截取网络分组,并输出分组内容的工具。凭借强大的功能和灵活的截取策略,使其成为类UNIX系统下用于网络分析和问题排查的首选工具
tcpdump提供了源代码,公开了接口,因此具备很强的可扩展性,对于网络维护和入侵者都是非常有用的工具
tcpdump 支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息
When tcpdump finishes capturing packets, it will report counts of:
-
packets ``captured'' (this is the number of packets that tcpdump has received and processed);
-
packets ``received by filter'' (the meaning of this depends on the OS on which you're running tcpdump, and possibly on the way the OS was configured - if a filter was specified on the command line, on some OSes it counts packets regardless of whether they were matched by the filter expression and, even if they were matched by the filter expression, regardless of whether tcpdump has read and processed them yet, on other OSes it counts only packets that were matched by the filter expression regardless of whether tcpdump has read and processed them yet, and on other OSes it counts only packets that were matched by the filter expression and were processed by tcpdump);
-
packets ``dropped by kernel'' (this is the number of packets that were dropped, due to a lack of buffer space, by the packet capture mechanism in the OS on which tcpdump is running, if the OS reports that information to applications; if not, it will be reported as 0).
二、语法
完整的英文文档:https://www.tcpdump.org/tcpdump_man.html
-
-A 以ASCII格式打印出所有分组,并将链路层的头最小化。
-
-c 在收到指定的数量的分组后,tcpdump就会停止。
-
-C 在将一个原始分组写入文件之前,检查文件当前的大小是否超过了参数file_size 中指定的大小。如果超过了指定大小,则关闭当前文件,然后在打开一个新的文件。参数 file_size 的单位是兆字节(是1,000,000字节,而不是1,048,576字节)。
-
-d 将匹配信息包的代码以人们能够理解的汇编格式给出。
-
-dd 将匹配信息包的代码以C语言程序段的格式给出。
-
-ddd 将匹配信息包的代码以十进制的形式给出。
-
-D 打印出系统中所有可以用tcpdump截包的网络接口。
-
-e 在输出行打印出数据链路层的头部信息。
-
-E 用spi@ipaddr algo:secret解密那些以addr作为地址,并且包含了安全参数索引值spi的IPsec ESP分组。
-
-f 将外部的Internet地址以数字的形式打印出来。
-
-F 从指定的文件中读取表达式,忽略命令行中给出的表达式。
-
-i 指定监听的网络接口。
-
-l 使标准输出变为缓冲行形式,可以把数据导出到文件。
-
-L 列出网络接口的已知数据链路。
-
-m 从文件module中导入SMI MIB模块定义。该参数可以被使用多次,以导入多个MIB模块。
-
-M 如果tcp报文中存在TCP-MD5选项,则需要用secret作为共享的验证码用于验证TCP-MD5选选项摘要(详情可参考RFC 2385)。
-
-b 在数据-链路层上选择协议,包括ip、arp、rarp、ipx都是这一层的。
-
-n 不把网络地址转换成名字。
-
-nn 不进行端口名称的转换。
-
-N 不输出主机名中的域名部分。例如,‘nic.ddn.mil‘只输出’nic‘。
-
-t 在输出的每一行不打印时间戳。
-
-O 不运行分组分组匹配(packet-matching)代码优化程序。
-
-P 不将网络接口设置成混杂模式。
-
-q 快速输出。只输出较少的协议信息。
-
-r 从指定的文件中读取包(这些包一般通过-w选项产生)。
-
-S 将tcp的序列号以绝对值形式输出,而不是相对值。
-
-s 从每个分组中读取最开始的snaplen个字节,而不是默认的68个字节。
-
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc远程过程调用)和snmp(简单网络管理协议;)。
-
-t 不在每一行中输出时间戳。
-
-tt 在每一行中输出非格式化的时间戳。
-
-ttt 输出本行和前面一行之间的时间差。
-
-tttt 在每一行中输出由date处理的默认格式的时间戳。
-
-u 输出未解码的NFS句柄。
-
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息。
-
-vv 输出详细的报文信息。
-
-w 直接将分组写入文件中,而不是不分析并打印出来。
以太网帧的封包格式为:Frame=Ethernet Header +IP Header +TCP Header +TCP Segment Data
-
Ethernet Header =14 Byte =Dst Physical Address(6 Byte)+ Src Physical Address(6 Byte)+Type(2 Byte),以太网帧头以下称之为数据帧。
-
IP Header =20 Byte(without options field),数据在IP层称为Datagram,分片称为Fragment。
-
TCP Header = 20 Byte(without options field),数据在TCP层称为Stream,分段称为Segment(UDP中称为Message)。
-
54个字节后为TCP数据负载部分(Data Portion),即应用层用户数据。
Ethernet Header以下的IP数据报最大传输单位为MTU(Maximum Transmission Unit,Effect of short board),对于大多数使用以太网的局域网来说,MTU=1500。
TCP数据包每次能够传输的最大数据分段为MSS,为了达到最佳的传输效能,在建立TCP连接时双方将协商MSS值——双方提供的MSS值中的最小值为这次连接的最大MSS值。MSS往往基于MTU计算出来,通常MSS=MTU-sizeof(IP Header)-sizeof(TCP Header)=1500-20-20=1460。
这样,数据经过本地TCP层分段后,交给本地IP层,在本地IP层就不需要分片了。但是在下一跳路由(Next Hop)的邻居路由器上可能发生IP分片!因为路由器的网卡的MTU可能小于需要转发的IP数据报的大小。
这时候,在路由器上可能发生两种情况:
(1)如果源发送端设置了这个IP数据包可以分片(May Fragment,DF=0),路由器将IP数据报分片后转发。
(2)如果源发送端设置了这个IP数据报不可以分片(Don’t Fragment,DF=1),路由器将IP数据报丢弃,并发送ICMP分片错误消息给源发送端。
三、实例
1、默认启动
tcpdump -vv
普通情况下,直接启动tcpdump将监视第一个网络接口上所有流过的数据包。
2、过滤主机
tcpdump -i eth1 host 192.168.1.1 tcpdump -i eth1 src host 192.168.1.1 tcpdump -i eth1 dst host 192.168.1.1
抓取所有经过eth1,目的或源地址是192.168.1.1的网络数据
指定源地址,192.168.1.1
指定目的地址,192.168.1.1
3、过滤端口
tcpdump -i eth1 port 25 tcpdump -i eth1 src port 25 tcpdump -i eth1 dst port 25
抓取所有经过eth1,目的或源端口是25的网络数据
指定源端口
指定目的端口
4、网络过滤
tcpdump -i eth1 net 192.168 tcpdump -i eth1 src net 192.168 tcpdump -i eth1 dst net 192.168
5、协议过滤
tcpdump -i eth1 arp tcpdump -i eth1 ip tcpdump -i eth1 tcp tcpdump -i eth1 udp tcpdump -i eth1 icmp
6、常用表达式
非 : ! or "not" (去掉双引号) 且 : && or "and" 或 : || or "or"
抓取所有经过eth1,目的地址是192.168.1.254或192.168.1.200端口是80的TCP数
tcpdump -i eth1 '((tcp) and (port 80) and ((dst host 192.168.1.254) or (dst host 192.168.1.200)))'
抓取所有经过eth1,目标MAC地址是00:01:02:03:04:05的ICMP数据
tcpdump -i eth1 '((icmp) and ((ether dst host 00:01:02:03:04:05)))'
抓取所有经过eth1,目的网络是192.168,但目的主机不是192.168.1.200的TCP数据
tcpdump -i eth1 '((tcp) and ((dst net 192.168) and (not dst host 192.168.1.200)))'
四、高级过滤方式
首先了解如何从包头过滤信息
proto[x:y] : 过滤从x字节开始的y字节数。比如ip[2:2]过滤出3、4字节(第一字节从0开始排) proto[x:y] & z = 0 : proto[x:y]和z的与操作为0 proto[x:y] & z !=0 : proto[x:y]和z的与操作不为0 proto[x:y] & z = z : proto[x:y]和z的与操作为z proto[x:y] = z : proto[x:y]等于z
操作符 : >, <, >=, <=, =, !=
1、IP头(IPV4)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| IHL |Type of Service| Total Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Identification |Flags| Fragment Offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time to Live | Protocol | Header Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | <-- optional +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | DATA ... | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
中文:
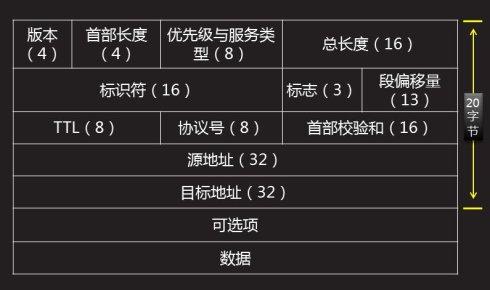
/*IP头定义,共20个字节*/
typedef struct _IP_HEADER
{
char m_cVersionAndHeaderLen; //版本信息(前4位),头长度(后4位)
char m_cTypeOfService; // 服务类型8位
short m_sTotalLenOfPacket; //数据包长度
short m_sPacketID; //数据包标识
short m_sSliceinfo; //分片使用
char m_cTTL; //存活时间
char m_cTypeOfProtocol; //协议类型
short m_sCheckSum; //校验和
unsigned int m_uiSourIp; //源ip
unsigned int m_uiDestIp; //目的ip
} __attribute__((packed))IP_HEADER, *PIP_HEADER ;
- 版本:指IP协议的版本,通信双方使用的IP协议版本必须一致。一般的值为0100(IPv4),0110(IPv6)。
-
首部长度:长度4比特。这个字段的作用是为了描述IP包头的长度,因为在IP包头中有变长的可选部分。该部分占4个bit位,单位为32bit(4个字节),即本区域值= IP头部长度(单位为bit)/(8*4),因此,一个IP包头的长度最长为“1111”,即15*4=60个字节。IP包头最小长度为20字节。
-
优先级与服务类型:长度8比特,定义了数据包传输的紧急程度以及时延、可靠性、传输成本等。
-
总长度:16比特,以字节为单位描述IP包的总长度(包括头部和数据两部分),最大值为65535。第二行中标识符、标志和段偏移量通常联合使用,用于数据拆分时的分组和重组。
-
标识符:对于上层发来的较大的数据包,往往需要拆分。路由器将一个大包进行拆分后,拆出来的所有部分被标上相同的值,该值即为标识符,用于告诉目的端哪些包属于同一个大包。
-
标志:长度3比特。该字段第一位不使用。第二位是DF(Don't Fragment)位,DF位设为1时表明路由器不能对该上层数据包分段。如果一个上层数据包无法在不分段的情况下进行转发,则路由器会丢弃该上层数据包并返回一个错误信息。第三位是MF(More Fragments)位,当路由器对一个上层数据包分段,则路由器会在除了最后一个分段的IP包的包头中将MF位设为1。
-
段偏移量:长度13比特,表示一个数据包在原先被拆分前的大包中的位置。接收端据此来还原和组装IP包。
-
TTL:表示IP包的生存时间,长度8比特。长度8比特。当IP包进行传送时,先会对该字段赋予某个特定的值。当IP包经过每一个沿途的路由器的时候,每个沿途的路由器会将IP包的TTL值减少1。如果TTL减少为0,则该IP包会被丢弃。这个字段可以防止由于路由环路而导致IP包在网络中不停被转发。
-
协议号:长度8比特,标识上一层即传输层在本次数据传输中所使用的协议。比如6代表TCP,17代表UDP等
-
首部校验和:长度16位。用来做IP头部的正确性检测,但不包含数据部分。 因为每个路由器要改变TTL的值,所以路由器会为每个通过的数据包重新计算这个值。
-
源地址:长度32比特,标识IP包的起源地址。
-
目标地址:长度32比特,表示IP包的目的地址。
-
可选项:可变长字段,主要用于测试,由起源设备跟据需要改写。
-
填充:因为IP包头长度(Header Length)部分的单位为32bit,所以IP包头的长度必须为32bit的整数倍。因此,在可选项后面,IP协议会填充若干个0,以达到32bit的整数倍。
2、IP选项
“一般”的IP头是20字节,但IP头有选项设置,不能直接从偏移21字节处读取数据。IP头有个长度字段可以知道头长度是否大于20字节。
通常第一个字节的二进制值是:01000101,分成两个部分:
0100 = 4 表示IP版本 0101 = 5 表示IP头32 bit的块数,5 x 32 bits = 160 bits or 20 bytes
如果第一字节第二部分的值大于5,那么表示头有IP选项。
下面介绍有过滤方法
0100 0101 : 第一字节的二进制
0000 1111 : 与操作
<=========
0000 0101 : 结果
正确的过滤方法
tcpdump -i eth1 'ip[0] & 15 > 5'
或者
tcpdump -i eth1 'ip[0] & 0x0f > 5'
3、分片标记
当发送端的MTU大于到目的路径链路上的MTU时就会被分片,分片信息在IP头的第七和第八字节:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Bit 0: 保留,必须是0
Bit 1: (DF) 0 = 可能分片, 1 = 不分片
Bit 2: (MF) 0 = 最后的分片, 1 = 还有分片
Fragment Offset字段只有在分片的时候才使用。
要抓带DF位标记的不分片的包,第七字节的值应该是:
01000000 = 64
tcpdump -i eth1 'ip[6] = 64'
4、抓分片包
- 匹配MF,分片包
tcpdump -i eth1 'ip[6] = 32'
最后分片包的开始3位是0,但是有Fragment Offset字段。
- 匹配分片和最后分片
tcpdump -i eth1 '((ip[6:2] > 0) and (not ip[6] = 64))'
测试分片可以用下面的命令:
ping -M want -s 3000 192.168.1.1
5、匹配小TTL
TTL字段在第九字节,并且正好是完整的一个字节,TTL最大值是255,二进制为11111111。
可以用下面的命令验证一下:
$ ping -M want -s 3000 -t 256 192.168.1.200 ping: ttl 256 out of range
+-+-+-+-+-+-+-+-+
| Time to Live |
+-+-+-+-+-+-+-+-+
- 在网关可以用下面的命令看看网络中谁在使用traceroute
tcpdump -i eth1 'ip[8] < 5'
6、抓大于X字节的包
- 大于600字节
tcpdump -i eth1 'ip[2:2] > 600'
7、更多的过滤方式
首先还是需要知道TCP基本结构
- TCP头
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Port | Destination Port | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Acknowledgment Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Data | |C|E|U|A|P|R|S|F| | | Offset| Res. |W|C|R|C|S|S|Y|I| Window | | | |R|E|G|K|H|T|N|N| | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Checksum | Urgent Pointer | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | data | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+

/*TCP头定义,共20个字节*/
typedef struct _TCP_HEADER
{
short m_sSourPort; // 源端口号16bit
short m_sDestPort; // 目的端口号16bit
unsigned int m_uiSequNum; // 序列号32bit
unsigned int m_uiAcknowledgeNum; // 确认号32bit
short m_sHeaderLenAndFlag; // 前4位:TCP头长度;中6位:保留;后6位:标志位
short m_sWindowSize; // 窗口大小16bit
short m_sCheckSum; // 检验和16bit
short m_surgentPointer; // 紧急数据偏移量16bit
}__attribute__((packed))TCP_HEADER, *PTCP_HEADER;
/*TCP头中的选项定义
kind(8bit)+Length(8bit,整个选项的长度,包含前两部分)+内容(如果有的话)
KIND =
1表示 无操作NOP,无后面的部分
2表示 maximum segment 后面的LENGTH就是maximum segment选项的长度(以byte为单位,1+1+内容部分长度)
3表示 windows scale 后面的LENGTH就是 windows scale选项的长度(以byte为单位,1+1+内容部分长度)
4表示 SACK permitted LENGTH为2,没有内容部分
5表示这是一个SACK包 LENGTH为2,没有内容部分
8表示时间戳,LENGTH为10,含8个字节的时间戳
*/
16位源端口号和16位目的端口号。
32位序号:一次TCP通信过程中某一个传输方向上的字节流的每个字节的编号,通过这个来确认发送的数据有序,比如现在序列号为1000,发送了1000,下一个序列号就是2000。
32位确认号:用来响应TCP报文段,给收到的TCP报文段的序号加1,三握时还要携带自己的序号。
4位头部长度:标识该TCP头部有多少个4字节,共表示最长15*4=60字节。同IP头部。
6位保留。6位标志。URG(紧急指针是否有效)ACK(表示确认号是否有效)PSH(提示接收端应用程序应该立即从TCP接收缓冲区读走数据)RST(表示要求对方重新建立连接)SYN(表示请求建立一个连接)FIN(表示通知对方本端要关闭连接)
16位窗口大小:TCP流量控制的一个手段,用来告诉对端TCP缓冲区还能容纳多少字节。
16位校验和:由发送端填充,接收端对报文段执行CRC算法以检验TCP报文段在传输中是否损坏。
16位紧急指针:一个正的偏移量,它和序号段的值相加表示最后一个紧急数据的下一字节的序号。
标志位字段(U、A、P、R、S、F):占6比特。各比特的含义如下:
- URG:紧急指针(urgent pointer)有效。
- ACK:确认序号有效。
- PSH:接收方应该尽快将这个报文段交给应用层。
- RST:重建连接。
- SYN:发起一个连接。
- FIN:释放一个连接。
- 窗口大小字段:占16比特。此字段用来进行流量控制。单位为字节数,这个值是本机期望一次接收的字节数。
- TCP校验和字段:占16比特。对整个TCP报文段,即TCP头部和TCP数据进行校验和计算,并由目标端进行验证。
- 紧急指针字段:占16比特。它是一个偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。
- 选项字段:占32比特。可能包括"窗口扩大因子"、"时间戳"等选项。
- 抓取源端口大于1024的TCP数据包
tcpdump -i eth1 'tcp[0:2] > 1024'
- 匹配TCP数据包的特殊标记
TCP标记定义在TCP头的第十四个字节
+-+-+-+-+-+-+-+-+
|C|E|U|A|P|R|S|F|
|W|C|R|C|S|S|Y|I|
|R|E|G|K|H|T|N|N|
+-+-+-+-+-+-+-+-+
- 只抓SYN包,第十四字节是二进制的00000010,也就是十进制的2
tcpdump -i eth1 'tcp[13] = 2'
- 抓SYN, ACK (00010010 or 18)
tcpdump -i eth1 'tcp[13] = 18'
- 抓SYN或者SYN-ACK
tcpdump -i eth1 'tcp[13] & 2 = 2'
- 抓PSH-ACK
tcpdump -i eth1 'tcp[13] = 24'
- 抓所有包含FIN标记的包(FIN通常和ACK一起,表示幽会完了,回见)
tcpdump -i eth1 'tcp[13] & 1 = 1'
- 抓RST
tcpdump -i eth1 'tcp[13] & 4 = 4'
8、常用的字段偏移名字
tcpdump考虑了一些数字恐惧症者的需求,提供了部分常用的字段偏移名字:
-
icmptype (ICMP类型字段)
-
icmpcode (ICMP符号字段)
-
tcpflags (TCP标记字段)
ICMP类型值有:
icmp-echoreply, icmp-unreach, icmp-sourcequench, icmp-redirect, icmp-echo, icmp-routeradvert, icmp-routersolicit, icmp-timxceed, icmp-paramprob, icmp-tstamp, icmp-tstampreply, icmp-ireq, icmp-ireqreply, icmp-maskreq, icmp-maskreply
TCP标记值:
tcp-fin, tcp-syn, tcp-rst, tcp-push, tcp-push, tcp-ack, tcp-urg
这样上面按照TCP标记位抓包的就可以写直观的表达式了:
- 只抓SYN包
tcpdump -i eth1 'tcp[tcpflags] = tcp-syn'
- 抓SYN, ACK
tcpdump -i eth1 'tcp[tcpflags] & tcp-syn != 0 and tcp[tcpflags] & tcp-ack != 0'
9、抓SMTP数据
tcpdump -i eth1 '((port 25) and (tcp[(tcp[12]>>2):4] = 0x4d41494c))'
抓取数据区开始为"MAIL"的包,"MAIL"的十六进制为0x4d41494c。
10、抓HTTP GET数据
tcpdump -i eth1 'tcp[(tcp[12]>>2):4] = 0x47455420'
"GET "的十六进制是47455420
11、抓SSH返回
tcpdump -i eth1 'tcp[(tcp[12]>>2):4] = 0x5353482D'
"SSH-"的十六进制是0x5353482D
tcpdump -i eth1 '(tcp[(tcp[12]>>2):4] = 0x5353482D) and (tcp[((tcp[12]>>2)+4):2] = 0x312E)'
五、比较常用的方式
如果是为了查看数据内容,建议用tcpdump -s 0 -w filename把数据包都保存下来,然后用wireshark的Follow TCP Stream/Follow UDP Stream来查看整个会话的内容。-s 0是抓取完整数据包,否则默认只抓68字节。用tcpflow也可以方便的获取TCP会话内容,支持tcpdump的各种表达式。
1、UDP头
0 7 8 15 16 23 24 31
+--------+--------+--------+--------+
| Source | Destination |
| Port | Port |
+--------+--------+--------+--------+
| | |
| Length | Checksum |
+--------+--------+--------+--------+
| |
| DATA ... |
+-----------------------------------+
/*UDP头定义,共8个字节*/
typedef struct _UDP_HEADER
{
unsigned short m_usSourPort; // 源端口号16bit
unsigned short m_usDestPort; // 目的端口号16bit
unsigned short m_usLength; // 数据包长度16bit
unsigned short m_usCheckSum; // 校验和16bit
}__attribute__((packed))UDP_HEADER, *PUDP_HEADER;
- 抓DNS请求数据
tcpdump -i eth1 udp dst port 53
2、系统测试
-c参数对于运维人员来说也比较常用,因为流量比较大的服务器,靠人工CTRL+C还是抓的太多,甚至导致服务器宕机,于是可以用-c参数指定抓多少个包。
time tcpdump -nn -i eth0 'tcp[tcpflags] = tcp-syn' -c 10000 > /dev/null
上面的命令计算抓10000个SYN包花费多少时间,可以判断访问量大概是多少。
3、tcpdump 与wireshark
Wireshark(以前是ethereal)是Windows下非常简单易用的抓包工具。但在Linux下很难找到一个好用的图形化抓包工具。
还好有Tcpdump。我们可以用Tcpdump + Wireshark 的完美组合实现:在 Linux 里抓包,然后在Windows 里分析包。
tcpdump tcp -i eth1 -t -s 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./target.cap
-
tcp: ip icmp arp rarp 和 tcp、udp、icmp这些选项等都要放到第一个参数的位置,用来过滤数据报的类型
-
-i eth1 : 只抓经过接口eth1的包
-
-t : 不显示时间戳
-
-s 0 : 抓取数据包时默认抓取长度为68字节。加上-S 0 后可以抓到完整的数据包
-
-c 100 : 只抓取100个数据包
-
dst port ! 22 : 不抓取目标端口是22的数据包
-
src net 192.168.1.0/24 : 数据包的源网络地址为192.168.1.0/24
-
-w ./target.cap : 保存成cap文件,方便用ethereal(即wireshark)分析
4、使用tcpdump抓取HTTP包
tcpdump -XvvennSs 0 -i eth0 tcp[20:2]=0x4745 or tcp[20:2]=0x4854
0x4745 为"GET"前两个字母"GE",0x4854 为"HTTP"前两个字母"HT"。
tcpdump 对截获的数据并没有进行彻底解码,数据包内的大部分内容是使用十六进制的形式直接打印输出的。显然这不利于分析网络故障,通常的解决办法是先使用带-w参数的tcpdump 截获数据并保存到文件中,然后再使用其他程序(如Wireshark)进行解码分析。当然也应该定义过滤规则,以避免捕获的数据包填满整个硬盘。
基本上tcpdump总的的输出格式为:系统时间 来源主机.端口 > 目标主机.端口 数据包参数
参考资料
https://linuxwiki.github.io/NetTools/tcpdump.html
https://www.cnblogs.com/ggjucheng/archive/2012/01/14/2322659.html
https://blog.wains.be/2007/2007-10-01-tcpdump-advanced-filters/ (原文)
https://www.cnblogs.com/shenpengyan/p/5912567.html
- 作者:踏雪无痕
- 出处:http://www.cnblogs.com/chenpingzhao/
- 本文版权归作者和博客园共有,如需转载,请联系 pingzhao1990#163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号