基于Flume的日志收集系统方案参考
前言
本文将简单介绍两种基于Flume的日志收集系统可能的架构方案,可根据不同的实际场景参考使用。
方案一
示例图如下:
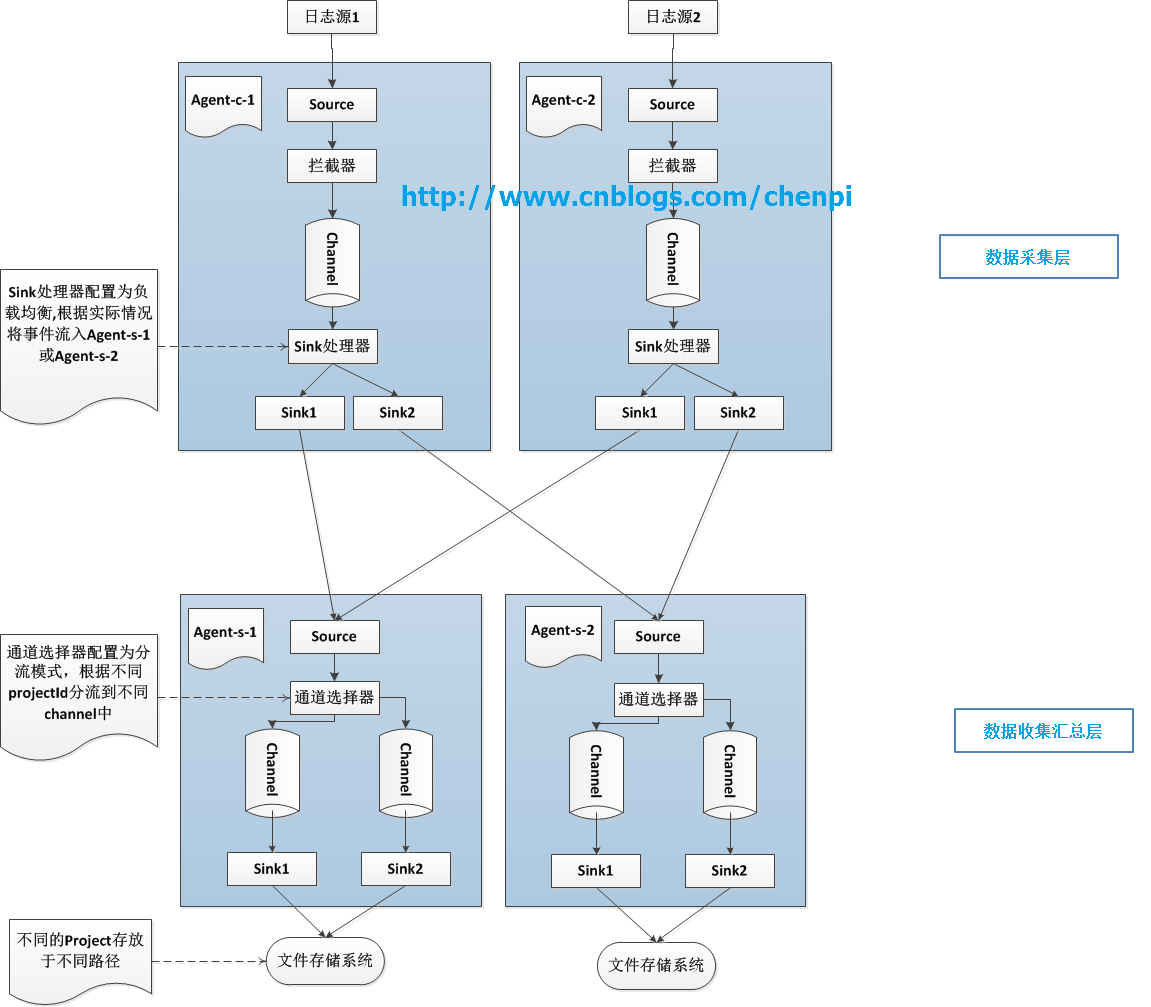
说明:
每个日志源(http上报、日志文件等)对应一个Agent-c用于收集对应日志, 收集来的日志可以流到Agent-s-1或Agent-s-2;
Agent-c的Sink处理器采用轮询负载均衡策略,一方面可以分担压力,另一方面可增加系统可用性,即使一个Agent-s出现故障,系统可正常运行;
最后,Agent-s-1和Agent-s-2的通道处理器配置为分流模式,将不同project的事件分流到不同Channel中,最后交由不同的Sink处理,并存入到对应存储系统中;
以上数据采集层和数据汇总层均支持水平扩展;
方案二
示例图如下:

说明:
与方案一不同的是,该方案支持将事件流输出到kafka队列中,实现方式是在Agent-c上配置通道选择器,配置为复制模式,复制一份相同的事件流到其它通道Sink3上,最终输出到kafka队列。
补充
以上图例仅供参考,参考。。。
实际上,由于Source、Channel、SInk等组件都支持自定义实现,所以方案可以非常自由,我们可以自定义Sink组件,实现事件写入到本地存储系统的同时,写入到kafka队列中,只有想不到,没有做不到;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号