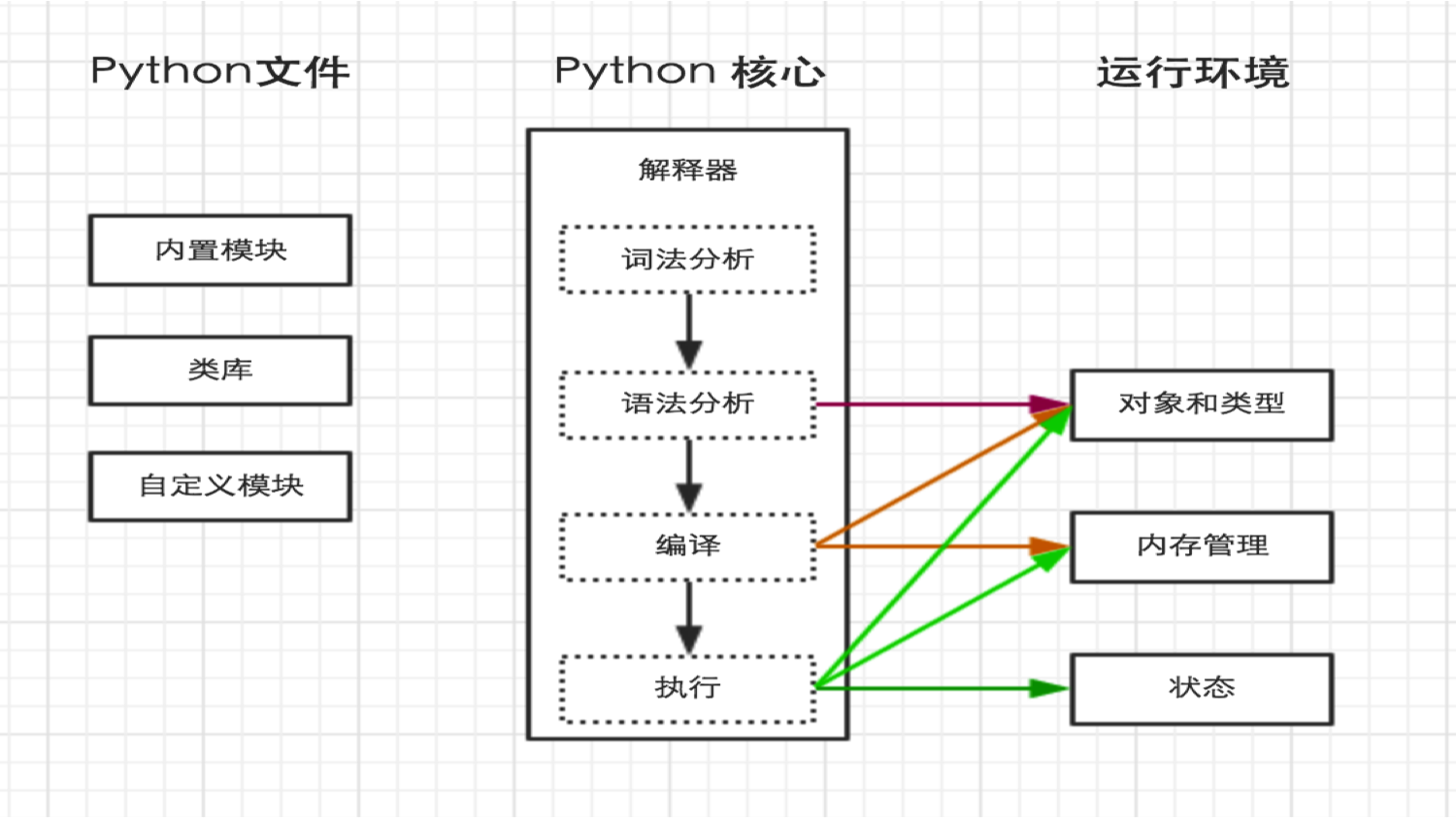
一、Python内部执行过程
1、Python的后缀名可以是任意?
print("hello,world") 保存成 .py / .txt / .sb / .aaa 都可以用在cmd用Python执行
2、导入模块时,如果不是.py文件,就会报错
3、以后文件后缀名都要是 .py
二、解释器
指定由Python解释器执行Python脚本
如果想类似执行shell脚本一样执行hello.py脚本,例如: ./hello.py ,那么需要在hello.py文件的头部指定解释器,如下:
#!/usr/bin/env python print("hello,world")
如此一来,执行: ./hello.py 即可。
注意:执行前需要给予 hello.py 执行权限,chmod 755 hello.py
Python交互式环境的提示符: >>>
Windows命令行模式的提示符: C:>
在Python交互式环境下直接输入代码,按回车,就可以立刻得到代码执行结果,但是在命令行模式下,执行 Python ##.py文件时,并不会。
在命令行模式下,可以执行python进入Python交互式环境,也可以执行python hello.py运行一个.py文件
两种文本编辑器:Sublime Text 、 Notepad++
执行python文件,在命令行中,切换到该Python文件所在的目录下,然后输入 Python ###.py命令就可以了。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
Python交互模式主要是为了调试Python代码用的,也便于初学者学习,它不是正式运行Python代码的环境!
Python的交互模式和直接运行.py文件有什么区别呢?
直接输入python进入交互模式,相当于启动了Python解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行。
直接运行.py文件相当于启动了Python解释器,然后一次性把.py文件的源代码给执行了,你是没有机会以交互的方式输入源代码的。
三、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
报错:ascii码无法表示中文
1 #!/usr/bin/env python 2 3 print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 print "你好,世界"
注意:
1、/usr/bin/env 在Windows下其实并不需要
2、/usr/bin/env 是Python在Linux下的路径,当在Linux系统通过命令: ./name.py 执行Python文件时,告诉Linux使用Python解释器。
3、# -*- coding:utf8 -*-,在Python2中要加上才能显示中文,否则报错;在Python3中可以不加。
4、utf8:中文用3字节; gbk:中文用2字节
四、注释
单行注视:# 被注释内容
多行注释:""" 被注释内容 """
五、执行脚本传入参数
Python有大量的模块,类库有三种:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
例如:
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import sys 5 6 print sys.argv
六、pyc文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
注意:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
七、变量
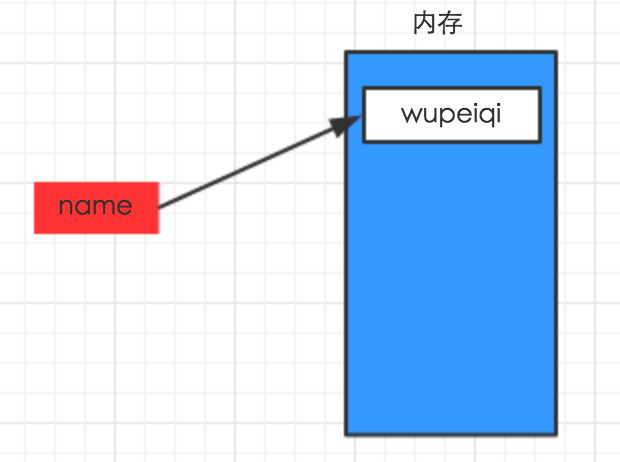
1、声明变量
name = "tom"
# name:变量名, tom:变量的内容, =:赋值号
变量的作用:通过符号指代内存中的某个内容
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
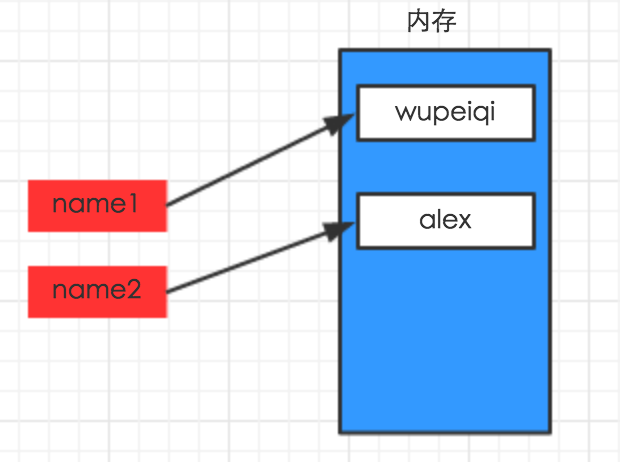
2、变量的赋值
name1 = "wupeiqi" name2 = "alex"
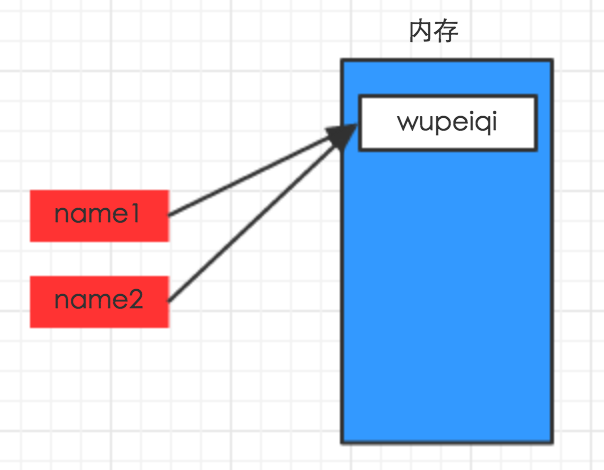
name1 = "wupeiqi" name2 = name1
八、输入
获得用户输入:input函数
例如:
>>> name = input("请输入用户名:") 请输入用户名:tom >>> name 'tom'
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
>>> import getpass >>> pwd = getpass.getpass() Passwd: >>> pwd 123456
注意:Python自带的ide不支持隐藏回显,用Windows的cmd就可以
九、流程控制和缩进
示例一:用户登录验证
#!/usr/bin/env python # -*- coding: utf-8 -*- # 加载getpass库 import getpass name = input('请输入用户名:') pwd = getpass.getpass('请输入密码:') if name == "tom" and pwd == "111111": print "欢迎,tom!" else: print "用户名和密码错误"
示例二:根据用户输入内容输出其权限
# 根据用户输入内容打印其权限 # alex --> 超级管理员 # eric --> 普通管理员 # tony,rain --> 业务主管 # 其他 --> 普通用户 name = raw_input('请输入用户名:') if name == "alex": print "超级管理员" elif name == "eric": print "普通管理员" elif name == "tony" or name == "rain": print "业务主管" else: print "普通用户"
十、while循环
1、基本循环
while <条件>: <循环体> # 如果条件为真,执行循环体 # 如果条件为假,不执行循环体
2、
break:结束循环
continue:跳过当前循环,直接开始下一次循环
要特别注意,不要滥用break和continue语句。break和continue会造成代码执行逻辑分叉过多,容易出错。大多数循环并不需要用到break和continue语句,上面的两个例子,都可以通过改写循环条件或者修改循环逻辑,去掉break和continue语句。
有些时候,如果代码写得有问题,会让程序陷入“死循环”,也就是永远循环下去。这时可以用Ctrl+C退出程序,或者强制结束Python进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号