2024数据采集与融合技术实践第四次作业
| 这个作业属于哪个课程 | <首页 - 2024数据采集与融合技术实践 - 福州大学 - 班级博客 - 博客园 (cnblogs.com)> |
|---|---|
| 这个作业要求在哪里 | <作业4 - 作业 - 2024数据采集与融合技术实践 - 班级博客 - 博客园 (cnblogs.com)> |
| 学号 | <102202126> |
一、作业内容
作业①
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
代码如下
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver import ChromeService from selenium.webdriver import ChromeOptions from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time import pymysql chrome_options = ChromeOptions() chrome_options.add_argument('--disable-gpu') chrome_options.binary_location = r'C:\Users\20733\AppData\Local\Google\Chrome\Application\chrome.exe' chrome_options.add_argument('--disable-blink-features=AutomationControlled') service = ChromeService(executable_path='C:/Users/20733/AppData/Local/Programs/Python/Python313/Scripts/chromedriver.exe') driver = webdriver.Chrome(service=service,options=chrome_options) driver.maximize_window() # 连接scrapy数据库,创建表 try: db = pymysql.connect( host='127.0.0.1', user='root', passwd='Cjkmysql.', port=3306, charset='utf8', database='chenoojkk',) cursor = db.cursor() cursor.execute('DROP TABLE IF EXISTS stockT') sql = '''CREATE TABLE stockT(num varchar(32),id varchar(12),name varchar(32),Latest_quotation varchar(32),Chg varchar(12),up_down_amount varchar(12), turnover varchar(16),transaction_volume varchar(16),amplitude varchar(16),highest varchar(32), lowest varchar(32),today varchar(32),yesterday varchar(32))''' cursor.execute(sql) except Exception as e: print(e) def spider(page_num): cnt = 0 while cnt < page_num: spiderOnePage() driver.find_element(By.XPATH,'//a[@class="next paginate_button"]').click() cnt +=1 time.sleep(2) # 爬取一个页面的数据 def spiderOnePage(): time.sleep(3) trs = driver.find_elements(By.XPATH,'//table[@id="table_wrapper-table"]//tr[@class]') for tr in trs: tds = tr.find_elements(By.XPATH,'.//td') num = tds[0].text id = tds[1].text name = tds[2].text Latest_quotation = tds[6].text Chg = tds[7].text up_down_amount = tds[8].text turnover = tds[9].text transaction_volume = tds[10].text amplitude = tds[11].text highest = tds[12].text lowest = tds[13].text today = tds[14].text yesterday = tds[15].text cursor.execute('INSERT INTO stockT VALUES ("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")' % (num,id,name,Latest_quotation, Chg,up_down_amount,turnover,transaction_volume,amplitude,highest,lowest,today,yesterday)) db.commit() # 访问东方财富网 driver.get('https://www.eastmoney.com/') # 访问行情中心 driver.get(WebDriverWait(driver,15,0.48).until(EC.presence_of_element_located((By.XPATH,'/html/body/div[6]/div/div[2]/div[1]/div[1]/a'))).get_attribute('href')) # 访问沪深京A股 driver.get(WebDriverWait(driver,15,0.48).until(EC.presence_of_element_located((By.ID,'menu_hs_a_board'))).get_attribute('href')) # 爬取两页的数据 spider(2) driver.back() # 访问上证A股 driver.get(WebDriverWait(driver,15,0.48).until(EC.presence_of_element_located((By.ID,'menu_sh_a_board'))).get_attribute('href')) spider(2) driver.back() # 访问深证A股 driver.get(WebDriverWait(driver,15,0.48).until(EC.presence_of_element_located((By.ID,'menu_sz_a_board'))).get_attribute('href')) spider(2) try: cursor.close() db.close() except: pass time.sleep(3) driver.quit() -
输出信息:
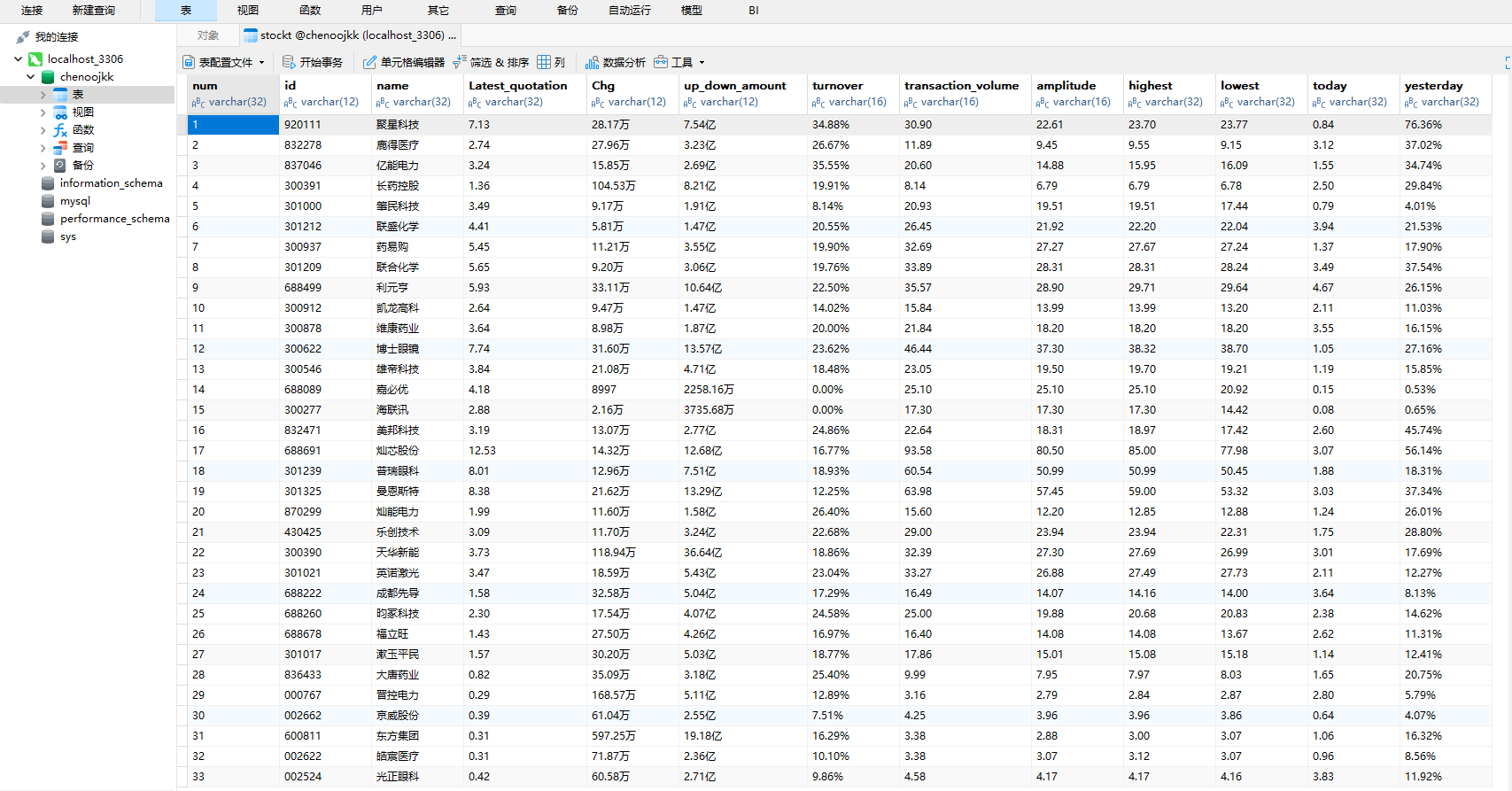
-
Gitee文件夹链接:陈家凯第四次实践作业
-
心得体会:
- 在实际操作中,使用Selenium爬虫抓取股票数据时,性能和效率之间需要做一定的平衡。虽然Selenium能够较好地应对动态加载的问题,但也牺牲了抓取速度。
- 数据存储的结构设计和优化也是需要重点关注的部分,特别是在处理大规模数据时,要确保数据库的高效查询和数据的完整性。
- 很多股票数据是通过JavaScript动态加载的,因此需要通过Selenium获取页面源代码,或者直接分析API请求,找到数据源。通常情况下,网站的数据以JSON形式返回,可以直接通过API接口进行获取,避免使用Selenium来模拟浏览器。
作业②
-
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
代码如下
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeService
from selenium.webdriver import ChromeOptions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pymysql
chrome_options = ChromeOptions()
chrome_options.add_argument('--disable-gpu')
chrome_options.binary_location = r'C:\Users\20733\AppData\Local\Google\Chrome\Application\chrome.exe'
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
# chrome_options.add_argument('--headless') # 无头模式
service = ChromeService(executable_path='C:/Users/20733/AppData/Local/Programs/Python/Python313/Scripts/chromedriver.exe')
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.maximize_window() # 使浏览器窗口最大化
# 连接MySql
try:
db = pymysql.connect( host='127.0.0.1', user='root', passwd='Cjkmysql.', port=3306, charset='utf8',
database='chenoojkk',)
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS courseMessage')
sql = '''CREATE TABLE courseMessage(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),
cProcess varchar(32),cBrief varchar(2048))'''
cursor.execute(sql)
except Exception as e:
print(e)
# 爬取一个页面的数据
def spiderOnePage():
time.sleep(5) # 等待页面加载完成
courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
current_window_handle = driver.current_window_handle
for course in courses:
cCourse = course.find_element(By.XPATH, './/h3').text # 课程名
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 大学名称
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 主讲老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 参与该课程的人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 课程进展
course.click() # 点击进入课程详情页,在新标签页中打开
Handles = driver.window_handles # 获取当前浏览器的所有页面的句柄
driver.switch_to.window(Handles[1]) # 跳转到新标签页
time.sleep(5) # 等待页面加载完成
# 爬取课程详情数据
# cBrief = WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'j-rectxt2'))).text
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')
cBrief = ""
for c in cBriefs:
cBrief += c.text
# 将文本中的引号进行转义处理,防止插入表格时报错
cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")
cBrief = cBrief.strip()
# 爬取老师团队信息
nameList = []
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
# 如果有下一页的标签,就点击它,然后继续爬取
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
while len(nextButton) != 0:
nextButton[0].click()
time.sleep(3)
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
cTeam = ','.join(nameList)
driver.close() # 关闭新标签页
driver.switch_to.window(current_window_handle) # 跳转回原始页面
try:
cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
except Exception as e:
print(e)
# 访问中国大学慕课
driver.get('https://www.icourse163.org/')
# 访问国家精品课程
driver.get(WebDriverWait(driver,15,0.48).until(EC.presence_of_element_located((By.XPATH,'//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a'))).get_attribute('href'))
spiderOnePage() # 爬取第一页的内容
count = 1
'''翻页操作'''
# 下一页的按钮
next_page = driver.find_element(By.XPATH,'//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
# 如果还有下一页,那么该标签的class属性为_3YiUU
while next_page.get_attribute('class') == '_3YiUU ':
if count == 5:
break
count += 1
next_page.click() # 点击按钮实现翻页
spiderOnePage() # 爬取一页的内容
next_page = driver.find_element(By.XPATH,'//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
try:
cursor.close()
db.close()
except:
pass
time.sleep(3)
driver.quit()
输出信息:
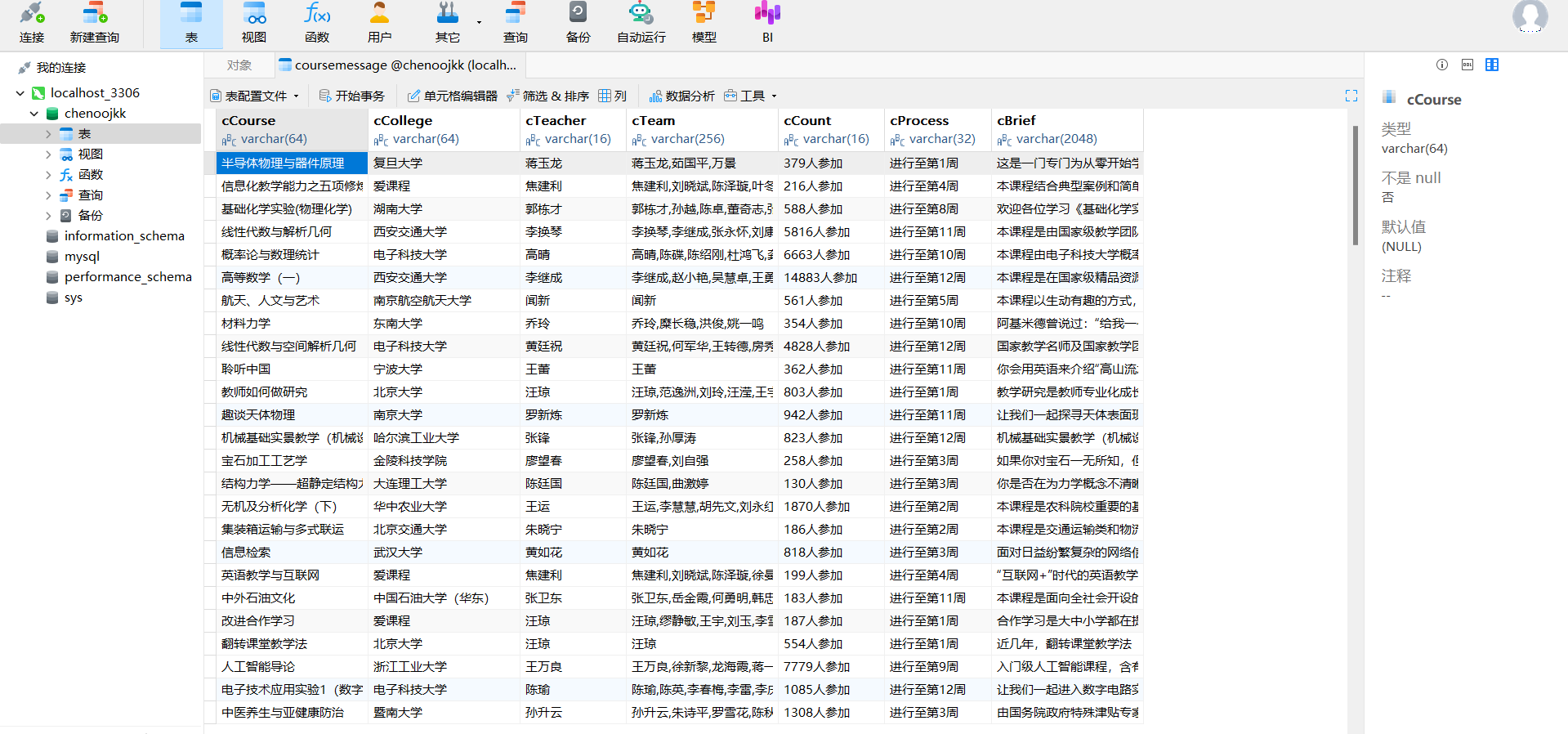
Gitee文件夹链接:陈家凯第四次实践作业
心得体会:
- 元素定位方式的选择:Selenium提供了多种方式来查找页面元素,例如
find_element_by_xpath、find_element_by_id、find_element_by_class_name等。选择合适的定位方式是保证爬虫稳定性的关键。一般来说,XPath 更为灵活,适用于复杂的网页结构,但效率较低;而 ID 和 Class 定位效率较高,但有时网页结构不规范,ID和Class可能变化频繁。 - 合理使用显式和隐式等待:在抓取动态加载的网页时,显式等待(
WebDriverWait) 是非常重要的。由于MOOC网课程信息的很多内容是通过JavaScript动态加载的,直接抓取页面可能导致获取到的内容为空或不完整。我使用了WebDriverWait等待特定元素加载完成后再进行抓取,确保数据的完整性和准确性。隐式等待(implicitly_wait)也有其用处,它会在查找每个元素时等待一定时间,但显式等待能更精确地控制等待时间。 - 避免元素定位失败:爬虫中常见的一个问题是页面结构的变化或加载错误导致元素定位失败。我通过添加异常处理机制(如
try-except)来捕获定位失败的情况,并根据实际情况进行重试或跳过错误元素。
作业③
-
要求:
-
掌握大数据相关服务,熟悉Xshell的使用
-
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
-
-
环境搭建:
- 任务一:开通MapReduce服务
-
实时分析开发实战:
-
任务一:Python脚本生成测试数据
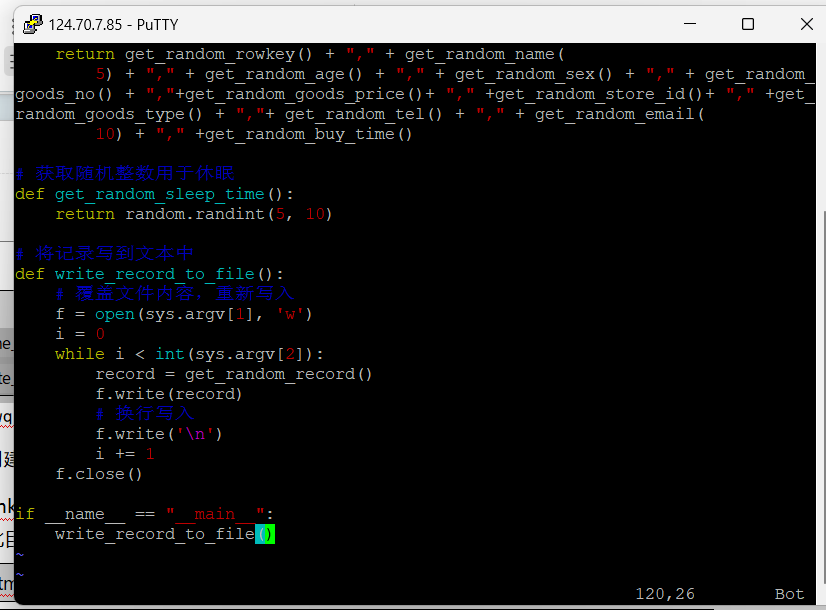
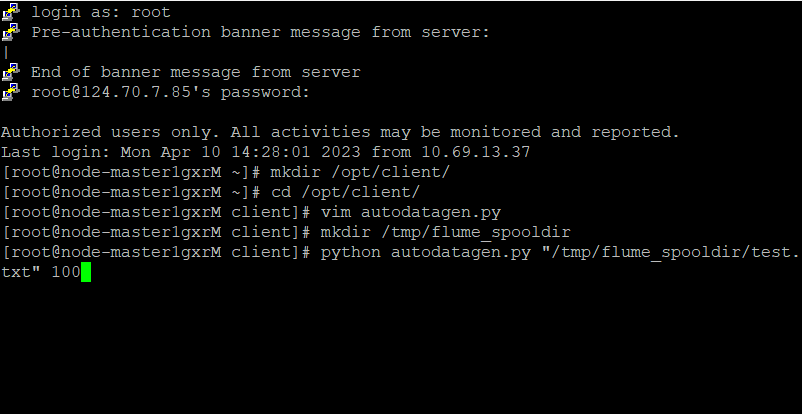
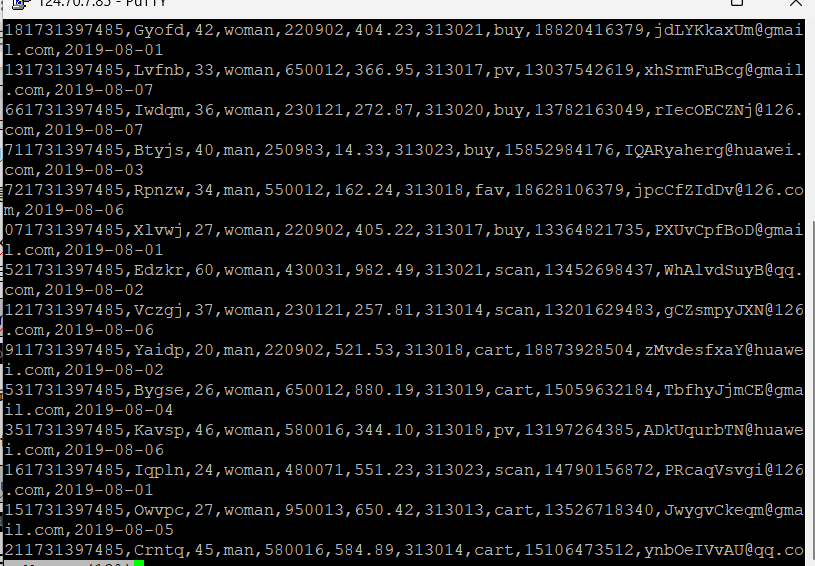
-
任务二:配置Kafka

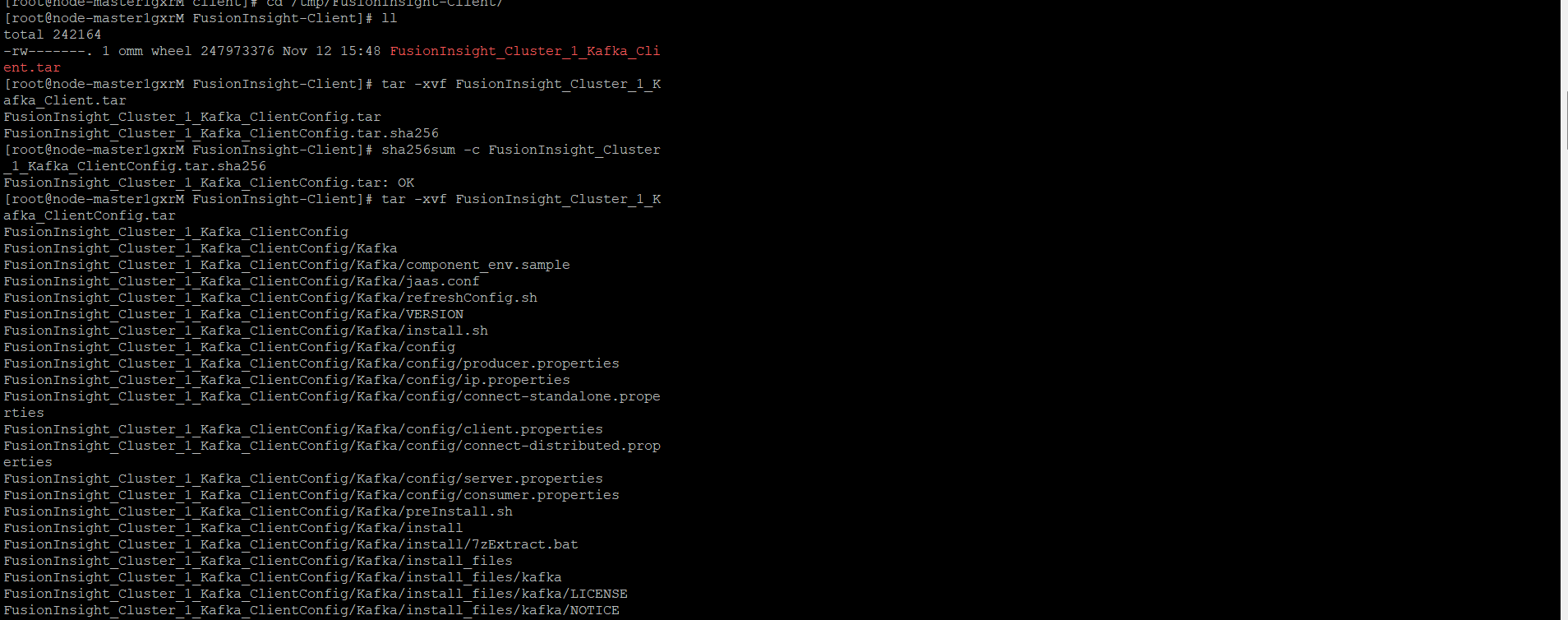
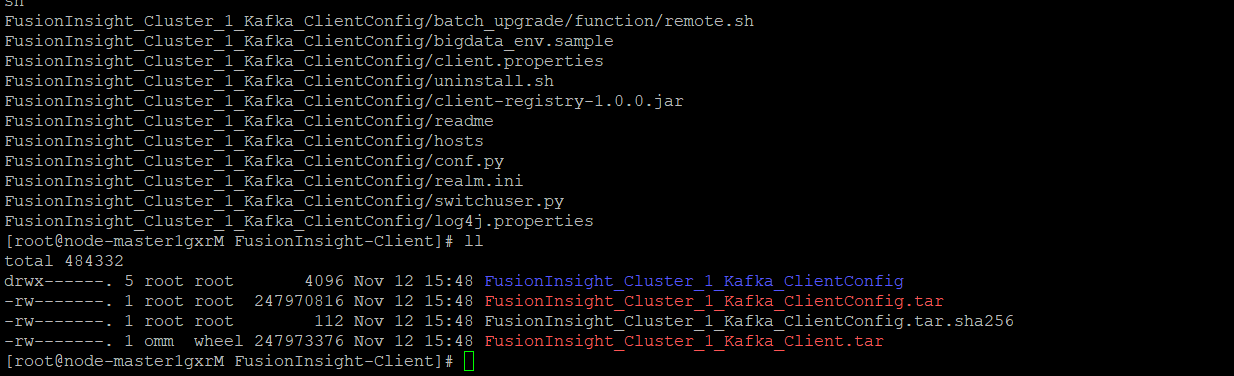
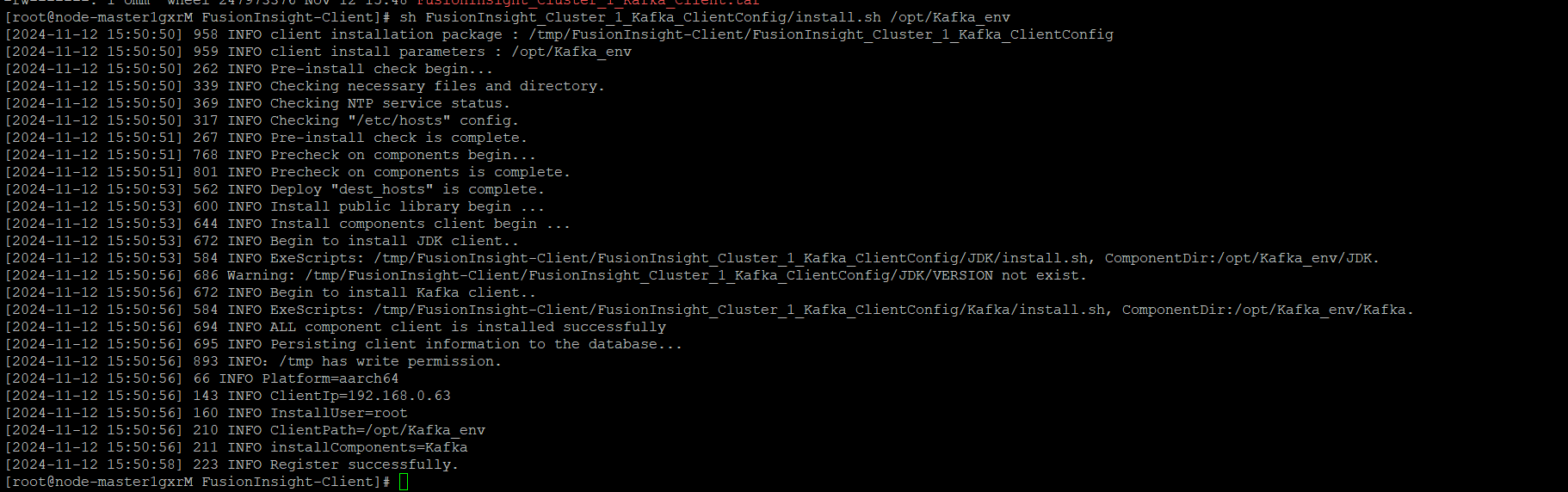


-
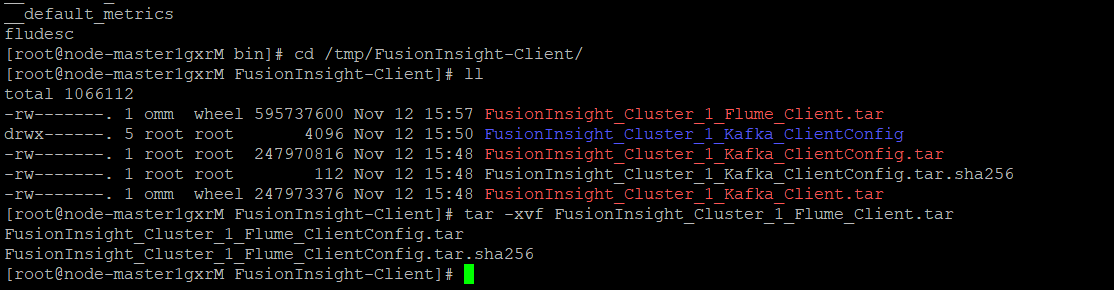
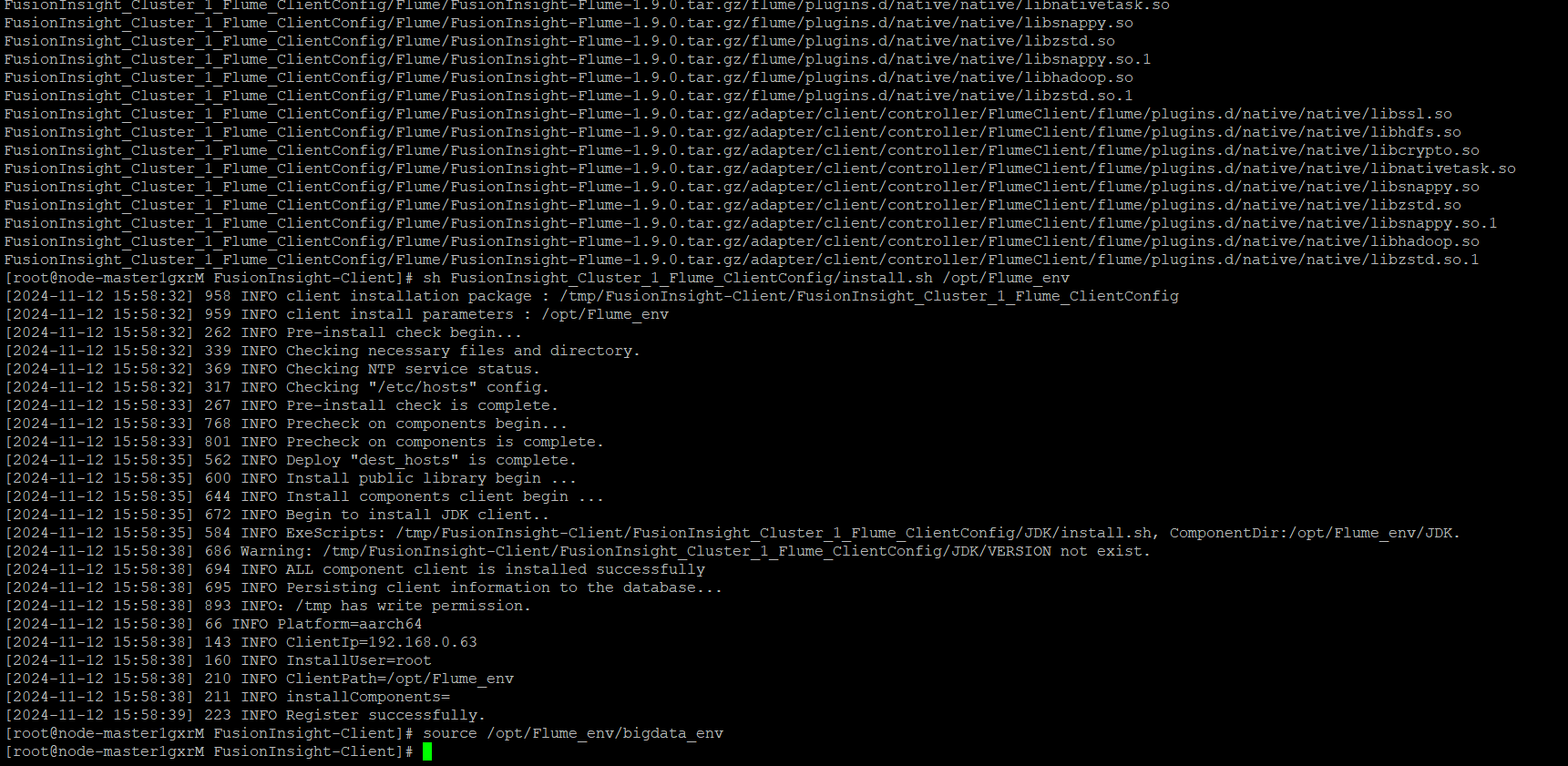
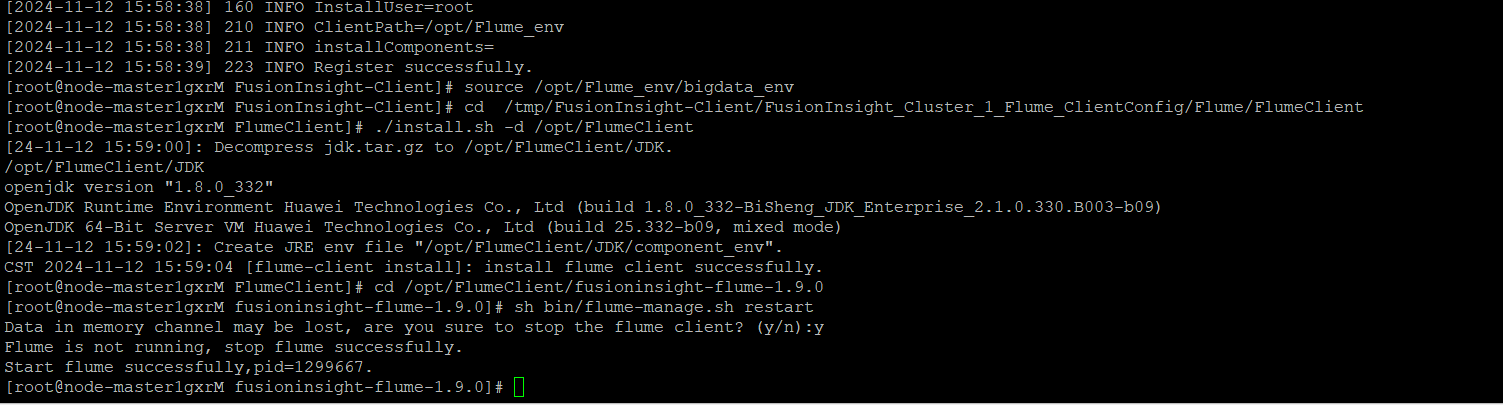
任务三: 安装Flume客户端
-
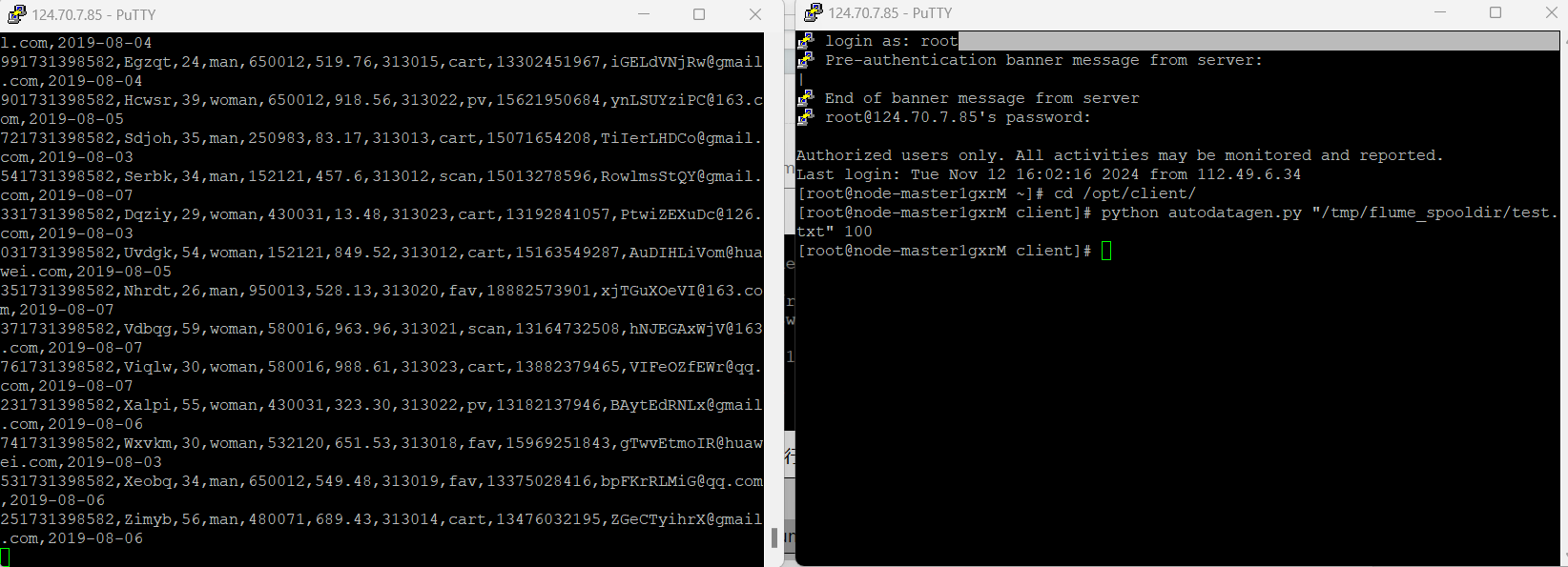
任务四:配置Flume采集数据
-
释放资源:

Gitee文件夹链接:陈家凯第四次实践作业
**心得体会:通过这个实验,我还更加理解了实时数据采集和处理的复杂性。虽然Flume本身非常强大,但在实际生产环境中,我们需要结合业务需求,进行细致的调优和监控。例如,如何处理高并发场景中的数据丢失问题,如何避免数据积压等问题,这些都需要根据具体情况进行配置和调整。总的来说,通过此次实验,我不仅学到了Flume的配置与应用技巧,更重要的是,我深刻体会到大数据处理过程中每一个环节的紧密配合。数据采集、存储、分析的每一步都需要精心设计和优化,Flume作为数据采集的“前哨”,为后续的实时数据分析和处理奠定了坚实的基础。这次实践经验无疑为我未来在大数据项目中的应用提供了宝贵的参考,特别是在日志数据采集、流式数据处理等方面的能力提升,将让我在未来的项目中更加得心应手。


· [翻译] 为什么 Tracebit 用 C# 开发
· 腾讯ima接入deepseek-r1,借用别人脑子用用成真了~
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· DeepSeek崛起:程序员“饭碗”被抢,还是职业进化新起点?
· RFID实践——.NET IoT程序读取高频RFID卡/标签